| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 100,000 add | 7.51 | 133.17 | 1.36e-4 |
| 100,000 add & poll | 44.25 | 22.60 | 0.00 |













| Method | Time Taken | Data Scale | Belongs To | big O |
|---|---|---|---|---|
| Queue.push & shift | 5.83 ms | 100K | Ours | O(1) |
| Array.push & shift | 2829.59 ms | 100K | Native JS | O(n) |
| Deque.unshift & shift | 2.44 ms | 100K | Ours | O(1) |
| Array.unshift & shift | 4750.37 ms | 100K | Native JS | O(n) |
| HashMap.set | 122.51 ms | 1M | Ours | O(1) |
| Map.set | 223.80 ms | 1M | Native JS | O(1) |
| Set.add | 185.06 ms | 1M | Native JS | O(1) |
| Data Structure | Plain Language Definition | Diagram |
|---|---|---|
| Linked List (Singly Linked List) | A line of bunnies, where each bunny holds the tail of the bunny in front of it (each bunny only knows the name of the bunny behind it). You want to find a bunny named Pablo, and you have to start searching from the first bunny. If it's not Pablo, you continue following that bunny's tail to the next one. So, you might need to search n times to find Pablo (O(n) time complexity). If you want to insert a bunny named Remi between Pablo and Vicky, it's very simple. You just need to let Vicky release Pablo's tail, let Remi hold Pablo's tail, and then let Vicky hold Remi's tail (O(1) time complexity). | |
| Array | A line of numbered bunnies. If you want to find the bunny named Pablo, you can directly shout out Pablo's number 0680 (finding the element directly through array indexing, O(1) time complexity). However, if you don't know Pablo's number, you still need to search one by one (O(n) time complexity). Moreover, if you want to add a bunny named Vicky behind Pablo, you will need to renumber all the bunnies after Vicky (O(n) time complexity). | |
| Queue | A line of numbered bunnies with a sticky note on the first bunny. For this line with a sticky note on the first bunny, whenever we want to remove a bunny from the front of the line, we only need to move the sticky note to the face of the next bunny without actually removing the bunny to avoid renumbering all the bunnies behind (removing from the front is also O(1) time complexity). For the tail of the line, we don't need to worry because each new bunny added to the tail is directly given a new number (O(1) time complexity) without needing to renumber all the previous bunnies. | |
| Deque | A line of grouped, numbered bunnies with a sticky note on the first bunny. For this line, we manage it by groups. Each time we remove a bunny from the front of the line, we only move the sticky note to the next bunny. This way, we don't need to renumber all the bunnies behind the first bunny each time a bunny is removed. Only when all members of a group are removed do we reassign numbers and regroup. The tail is handled similarly. This is a strategy of delaying and batching operations to offset the drawbacks of the Array data structure that requires moving all elements behind when inserting or deleting elements in the middle. | |
| Doubly Linked List | A line of bunnies where each bunny holds the tail of the bunny in front (each bunny knows the names of the two adjacent bunnies). This provides the Singly Linked List the ability to search forward, and that's all. For example, if you directly come to the bunny Remi in the line and ask her where Vicky is, she will say the one holding my tail behind me, and if you ask her where Pablo is, she will say right in front. | |
| Stack | A line of bunnies in a dead-end tunnel, where bunnies can only be removed from the tunnel entrance (end), and new bunnies can only be added at the entrance (end) as well. | |
| Binary Tree | As the name suggests, it's a tree where each node has at most two children. When you add consecutive data such as [4, 2, 6, 1, 3, 5, 7], it will be a complete binary tree. When you add data like [4, 2, 6, null, 1, 3, null, 5, null, 7], you can specify whether any left or right child node is null, and the shape of the tree is fully controllable. | |
| Binary Search Tree (BST) | A tree-like rabbit colony composed of doubly linked lists where each rabbit has at most two tails. These rabbits are disciplined and obedient, arranged in their positions according to a certain order. The most important data structure in a binary tree (the core is that the time complexity for insertion, deletion, modification, and search is O(log n)). The data stored in a BST is structured and ordered, not in strict order like 1, 2, 3, 4, 5, but maintaining that all nodes in the left subtree are less than the node, and all nodes in the right subtree are greater than the node. This order provides O(log n) time complexity for insertion, deletion, modification, and search. Reducing O(n) to O(log n) is the most common algorithm complexity optimization in the computer field, an exponential improvement in efficiency. It's also the most efficient way to organize unordered data into ordered data (most sorting algorithms only maintain O(n log n)). Of course, the binary search trees we provide support organizing data in both ascending and descending order. Remember that basic BSTs do not have self-balancing capabilities, and if you sequentially add sorted data to this data structure, it will degrade into a list, thus losing the O(log n) capability. Of course, our addMany method is specially handled to prevent degradation. However, for practical applications, please use Red-black Tree or AVL Tree as much as possible, as they inherently have self-balancing functions. | |
| Red-black Tree | A tree-like rabbit colony composed of doubly linked lists, where each rabbit has at most two tails. These rabbits are not only obedient but also intelligent, automatically arranging their positions in a certain order. A self-balancing binary search tree. Each node is marked with a red-black label. Ensuring that no path is more than twice as long as any other (maintaining a certain balance to improve the speed of search, addition, and deletion). | |
| AVL Tree | A tree-like rabbit colony composed of doubly linked lists, where each rabbit has at most two tails. These rabbits are not only obedient but also intelligent, automatically arranging their positions in a certain order, and they follow very strict rules. A self-balancing binary search tree. Each node is marked with a balance factor, representing the height difference between its left and right subtrees. The absolute value of the balance factor does not exceed 1 (maintaining stricter balance, which makes search efficiency higher than Red-black Tree, but insertion and deletion operations will be more complex and relatively less efficient). | |
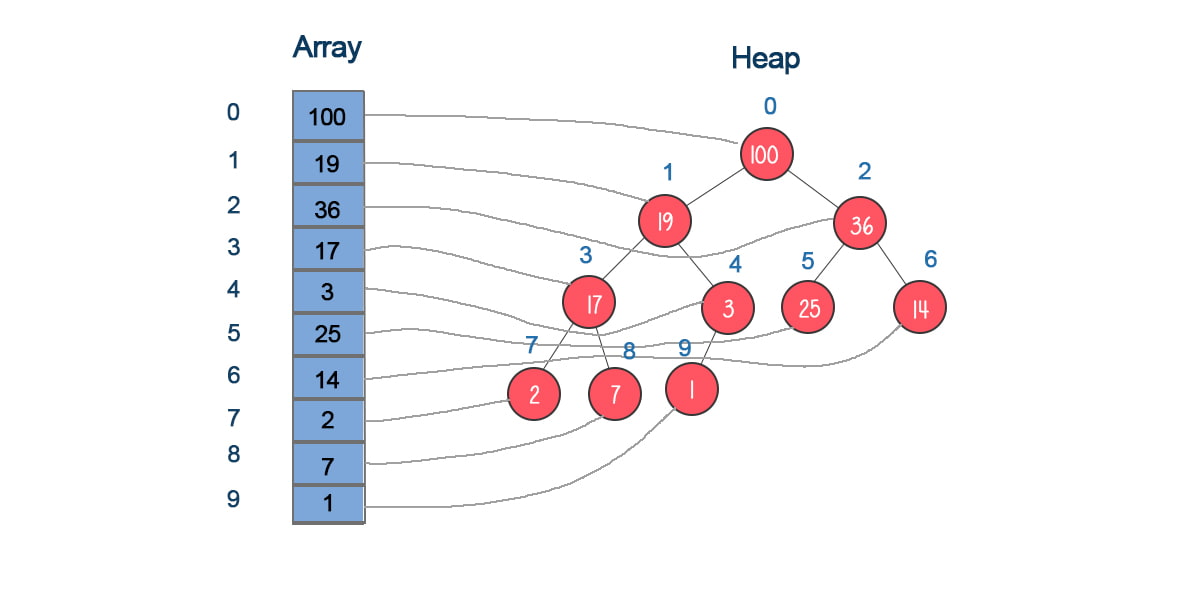
| Heap | A special type of complete binary tree, often stored in an array, where the children nodes of the node at index i are at indices 2i+1 and 2i+2. Naturally, the parent node of any node is at ⌊(i−1)/2⌋. | |
| Priority Queue | It's actually a Heap. | |
| Graph | The base class for Directed Graph and Undirected Graph, providing some common methods. | |
| Directed Graph | A network-like bunny group where each bunny can have up to n tails (Singly Linked List). | |
| Undirected Graph | A network-like bunny group where each bunny can have up to n tails (Doubly Linked List). | |
| Java ArrayList | Java Queue | Java ArrayDeque | Java LinkedList |
|---|---|---|---|
| add | offer | push | push |
| remove | poll | removeLast | removeLast |
| remove | poll | removeFirst | removeFirst |
| add(0, element) | offerFirst | unshift | unshift |
| Data Structure | Unit Test | Perf Test | API Doc | NPM | Downloads |
|---|---|---|---|---|---|
| Binary Tree |  |
|
Docs | NPM |  |
| Binary Search Tree (BST) | |
|
Docs | NPM |  |
| AVL Tree | |
|
Docs | NPM |  |
| Red Black Tree | |
|
Docs | NPM |  |
| Tree Multimap | |
|
Docs | NPM |  |
| Heap | |
|
Docs | NPM |  |
| Priority Queue | |
|
Docs | NPM |  |
| Max Priority Queue | |
|
Docs | NPM |  |
| Min Priority Queue | |
|
Docs | NPM |  |
| Trie | |
|
Docs | NPM |  |
| Graph | |
|
Docs | NPM |  |
| Directed Graph | |
|
Docs | NPM |  |
| Undirected Graph | |
|
Docs | NPM |  |
| Queue | |
|
Docs | NPM |  |
| Deque | |
|
Docs | NPM |  |
| Hash Map | |
|
Docs | ||
| Linked List | |
|
Docs | NPM |  |
| Singly Linked List | |
|
Docs | NPM |  |
| Doubly Linked List | |
|
Docs | NPM |  |
| Stack | |
|
Docs | NPM |  |
| Segment Tree | |
Docs | |||
| Binary Indexed Tree | |
Docs |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 100,000 add | 7.51 | 133.17 | 1.36e-4 |
| 100,000 add & poll | 44.25 | 22.60 | 0.00 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 100,000 add | 76.98 | 12.99 | 0.00 |
| 100,000 add randomly | 80.96 | 12.35 | 0.00 |
| 100,000 get | 111.72 | 8.95 | 0.00 |
| 100,000 iterator | 29.58 | 33.81 | 0.00 |
| 100,000 add & delete orderly | 153.21 | 6.53 | 0.00 |
| 100,000 add & delete randomly | 233.26 | 4.29 | 0.00 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000,000 push | 42.18 | 23.71 | 0.01 |
| 100,000 push & shift | 5.16 | 193.66 | 7.47e-4 |
| Native JS Array 100,000 push & shift | 2386.29 | 0.42 | 0.30 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000,000 push | 23.59 | 42.40 | 0.00 |
| 1,000,000 push & pop | 31.93 | 31.32 | 0.00 |
| 1,000,000 push & shift | 33.12 | 30.19 | 0.00 |
| 100,000 push & shift | 3.50 | 285.57 | 9.51e-4 |
| Native JS Array 100,000 push & shift | 2211.26 | 0.45 | 0.34 |
| 100,000 unshift & shift | 3.41 | 292.89 | 5.52e-4 |
| Native JS Array 100,000 unshift & shift | 4343.81 | 0.23 | 0.25 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000,000 set | 259.74 | 3.85 | 0.07 |
| Native JS Map 1,000,000 set | 208.35 | 4.80 | 0.02 |
| Native JS Set 1,000,000 add | 167.66 | 5.96 | 0.01 |
| 1,000,000 set & get | 260.46 | 3.84 | 0.04 |
| Native JS Map 1,000,000 set & get | 265.09 | 3.77 | 0.02 |
| Native JS Set 1,000,000 add & has | 169.15 | 5.91 | 0.01 |
| 1,000,000 ObjKey set & get | 317.23 | 3.15 | 0.04 |
| Native JS Map 1,000,000 ObjKey set & get | 304.84 | 3.28 | 0.04 |
| Native JS Set 1,000,000 ObjKey add & has | 278.30 | 3.59 | 0.05 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 100,000 push | 43.93 | 22.76 | 5.95e-4 |
| 100,000 getWords | 82.18 | 12.17 | 0.00 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 100,000 add | 275.72 | 3.63 | 0.00 |
| 100,000 add randomly | 332.35 | 3.01 | 0.00 |
| 100,000 get | 129.56 | 7.72 | 0.00 |
| 100,000 iterator | 32.03 | 31.22 | 0.01 |
| 100,000 add & delete orderly | 447.87 | 2.23 | 0.00 |
| 100,000 add & delete randomly | 605.40 | 1.65 | 0.03 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 10,000 RBTree add randomly | 6.91 | 144.82 | 1.13e-4 |
| 10,000 RBTree get randomly | 9.08 | 110.14 | 7.72e-5 |
| 10,000 RBTree add & delete randomly | 18.97 | 52.71 | 8.49e-4 |
| 10,000 AVLTree add randomly | 24.97 | 40.05 | 4.34e-4 |
| 10,000 AVLTree get randomly | 9.95 | 100.47 | 0.00 |
| 10,000 AVLTree add & delete randomly | 45.96 | 21.76 | 5.77e-4 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000 addVertex | 0.10 | 9730.42 | 1.39e-6 |
| 1,000 addEdge | 6.01 | 166.32 | 9.47e-5 |
| 1,000 getVertex | 0.04 | 2.59e+4 | 3.52e-7 |
| 1,000 getEdge | 23.80 | 42.03 | 0.00 |
| tarjan | 215.66 | 4.64 | 0.01 |
| topologicalSort | 187.85 | 5.32 | 0.00 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000,000 push | 197.45 | 5.06 | 0.03 |
| 1,000,000 unshift | 214.02 | 4.67 | 0.08 |
| 1,000,000 unshift & shift | 198.97 | 5.03 | 0.05 |
| 1,000,000 addBefore | 315.44 | 3.17 | 0.05 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000,000 push & shift | 196.91 | 5.08 | 0.04 |
| 10,000 push & pop | 222.29 | 4.50 | 0.01 |
| 10,000 addBefore | 248.87 | 4.02 | 0.01 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 100,000 add | 27.69 | 36.11 | 8.96e-4 |
| 100,000 add & poll | 75.38 | 13.27 | 6.45e-4 |
| test name | time taken (ms) | executions per sec | sample deviation |
|---|---|---|---|
| 1,000,000 push | 39.19 | 25.52 | 0.00 |
| 1,000,000 push & pop | 45.24 | 22.10 | 0.00 |
| Data Structure Typed | C++ STL | java.util | Python collections |
|---|---|---|---|
| Heap<E> | - | - | heapq |
| PriorityQueue<E> | priority_queue<T> | PriorityQueue<E> | - |
| Deque<E> | deque<T> | ArrayDeque<E> | deque |
| Queue<E> | queue<T> | Queue<E> | - |
| HashMap<K, V> | unordered_map<K, V> | HashMap<K, V> | defaultdict |
| DoublyLinkedList<E> | list<T> | LinkedList<E> | - |
| SinglyLinkedList<E> | - | - | - |
| BinaryTree<K, V> | - | - | - |
| BST<K, V> | - | - | - |
| RedBlackTree<E> | set<T> | TreeSet<E> | - |
| RedBlackTree<K, V> | map<K, V> | TreeMap<K, V> | - |
| TreeMultiMap<K, V> | multimap<K, V> | - | - |
| TreeMultiMap<E> | multiset<T> | - | - |
| Trie | - | - | - |
| DirectedGraph<V, E> | - | - | - |
| UndirectedGraph<V, E> | - | - | - |
| PriorityQueue<E> | priority_queue<T> | PriorityQueue<E> | - |
| Array<E> | vector<T> | ArrayList<E> | list |
| Stack<E> | stack<T> | Stack<E> | - |
| HashMap<E> | unordered_set<T> | HashSet<E> | set |
| - | unordered_multiset | - | Counter |
| LinkedHashMap<K, V> | - | LinkedHashMap<K, V> | OrderedDict |
| - | unordered_multimap<K, V> | - | - |
| - | bitset<N> | - | - |
| Algorithm | Function Description | Iteration Type |
|---|---|---|
| Binary Tree DFS | Traverse a binary tree in a depth-first manner, starting from the root node, first visiting the left subtree, and then the right subtree, using recursion. | Recursion + Iteration |
| Binary Tree BFS | Traverse a binary tree in a breadth-first manner, starting from the root node, visiting nodes level by level from left to right. | Iteration |
| Graph DFS | Traverse a graph in a depth-first manner, starting from a given node, exploring along one path as deeply as possible, and backtracking to explore other paths. Used for finding connected components, paths, etc. | Recursion + Iteration |
| Binary Tree Morris | Morris traversal is an in-order traversal algorithm for binary trees with O(1) space complexity. It allows tree traversal without additional stack or recursion. | Iteration |
| Graph BFS | Traverse a graph in a breadth-first manner, starting from a given node, first visiting nodes directly connected to the starting node, and then expanding level by level. Used for finding shortest paths, etc. | Recursion + Iteration |
| Graph Tarjan's Algorithm | Find strongly connected components in a graph, typically implemented using depth-first search. | Recursion |
| Graph Bellman-Ford Algorithm | Finding the shortest paths from a single source, can handle negative weight edges | Iteration |
| Graph Dijkstra's Algorithm | Finding the shortest paths from a single source, cannot handle negative weight edges | Iteration |
| Graph Floyd-Warshall Algorithm | Finding the shortest paths between all pairs of nodes | Iteration |
| Graph getCycles | Find all cycles in a graph or detect the presence of cycles. | Recursion |
| Graph getCutVertices | Find cut vertices in a graph, which are nodes that, when removed, increase the number of connected components in the graph. | Recursion |
| Graph getSCCs | Find strongly connected components in a graph, which are subgraphs where any two nodes can reach each other. | Recursion |
| Graph getBridges | Find bridges in a graph, which are edges that, when removed, increase the number of connected components in the graph. | Recursion |
| Graph topologicalSort | Perform topological sorting on a directed acyclic graph (DAG) to find a linear order of nodes such that all directed edges go from earlier nodes to later nodes. | Recursion |
| Principle | Description |
|---|---|
| Practicality | Follows ES6 and ESNext standards, offering unified and considerate optional parameters, and simplifies method names. |
| Extensibility | Adheres to OOP (Object-Oriented Programming) principles, allowing inheritance for all data structures. |
| Modularization | Includes data structure modularization and independent NPM packages. |
| Efficiency | All methods provide time and space complexity, comparable to native JS performance. |
| Maintainability | Follows open-source community development standards, complete documentation, continuous integration, and adheres to TDD (Test-Driven Development) patterns. |
| Testability | Automated and customized unit testing, performance testing, and integration testing. |
| Portability | Plans for porting to Java, Python, and C++, currently achieved to 80%. |
| Reusability | Fully decoupled, minimized side effects, and adheres to OOP. |
| Security | Carefully designed security for member variables and methods. Read-write separation. Data structure software does not need to consider other security aspects. |
| Scalability | Data structure software does not involve load issues. |